You've already forked Curso-lenguaje-python
Compare commits
3 Commits
4756d756ac
...
6cb79e3418
| Author | SHA1 | Date | |
|---|---|---|---|
| 6cb79e3418 | |||
| 28f9bb389d | |||
| f525beaf11 |
2
.gitignore
vendored
2
.gitignore
vendored
@@ -193,3 +193,5 @@ rss.db
|
|||||||
# Ignore volume files
|
# Ignore volume files
|
||||||
rabbitmq/
|
rabbitmq/
|
||||||
rabbitmq/*
|
rabbitmq/*
|
||||||
|
*_data
|
||||||
|
*_data/*
|
||||||
|
|||||||
318
catch-all/05_infra_test/03_kafka/README.md
Normal file
318
catch-all/05_infra_test/03_kafka/README.md
Normal file
@@ -0,0 +1,318 @@
|
|||||||
|
# Empezando con Apache Kafka en Python
|
||||||
|
|
||||||
|
En este artículo, voy a hablar sobre Apache Kafka y cómo los programadores de Python pueden usarlo para construir sistemas distribuidos.
|
||||||
|
|
||||||
|
|
||||||
|
## ¿Qué es Apache Kafka?
|
||||||
|
|
||||||
|
Apache Kafka es una plataforma de streaming de código abierto que fue inicialmente desarrollada por LinkedIn. Más tarde fue entregada a la fundación Apache y se convirtió en código abierto en 2011.
|
||||||
|
|
||||||
|
Según [Wikipedia](https://en.wikipedia.org/wiki/Apache_Kafka):
|
||||||
|
|
||||||
|
__Apache Kafka es una plataforma de software de procesamiento de flujos de código abierto desarrollada por la Fundación Apache, escrita en Scala y Java. El proyecto tiene como objetivo proporcionar una plataforma unificada, de alto rendimiento y baja latencia para manejar flujos de datos en tiempo real. Su capa de almacenamiento es esencialmente una "cola de mensajes pub/sub masivamente escalable arquitectada como un registro de transacciones distribuidas", lo que la hace altamente valiosa para las infraestructuras empresariales para procesar datos de streaming. Además, Kafka se conecta a sistemas externos (para importación/exportación de datos) a través de Kafka Connect y proporciona Kafka Streams, una biblioteca de procesamiento de flujos en Java.__
|
||||||
|
|
||||||
|
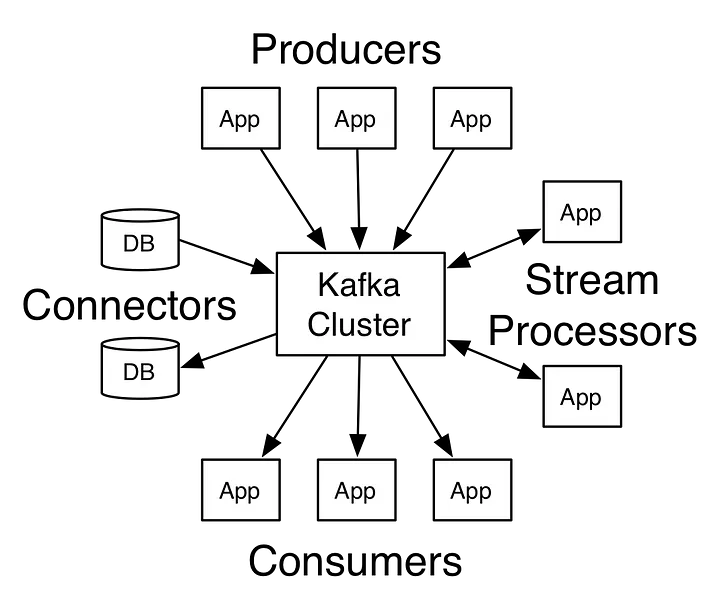
|
||||||
|
|
||||||
|
Piense en él como un gran registro de commits donde los datos se almacenan en secuencia a medida que ocurren. Los usuarios de este registro pueden acceder y usarlo según sus necesidades.
|
||||||
|
|
||||||
|
|
||||||
|
## Casos de uso de Kafka
|
||||||
|
|
||||||
|
Los usos de Kafka son múltiples. Aquí hay algunos casos de uso que podrían ayudarte a comprender su aplicación:
|
||||||
|
|
||||||
|
- **Monitoreo de Actividad**: Kafka puede ser utilizado para el monitoreo de actividad. La actividad puede pertenecer a un sitio web o a sensores y dispositivos físicos. Los productores pueden publicar datos en bruto de las fuentes de datos que luego pueden usarse para encontrar tendencias y patrones.
|
||||||
|
- **Mensajería**: Kafka puede ser utilizado como un intermediario de mensajes entre servicios. Si estás implementando una arquitectura de microservicios, puedes tener un microservicio como productor y otro como consumidor. Por ejemplo, tienes un microservicio responsable de crear nuevas cuentas y otro para enviar correos electrónicos a los usuarios sobre la creación de la cuenta.
|
||||||
|
- **Agregación de Logs**: Puedes usar Kafka para recopilar logs de diferentes sistemas y almacenarlos en un sistema centralizado para un procesamiento posterior.
|
||||||
|
- **ETL**: Kafka tiene una característica de streaming casi en tiempo real, por lo que puedes crear un ETL basado en tus necesidades.
|
||||||
|
- **Base de Datos**: Basado en lo que mencioné antes, podrías decir que Kafka también actúa como una base de datos. No una base de datos típica que tiene una característica de consulta de datos según sea necesario, lo que quise decir es que puedes mantener datos en Kafka todo el tiempo que quieras sin consumirlos.
|
||||||
|
|
||||||
|
|
||||||
|
## Conceptos de Kafka
|
||||||
|
|
||||||
|
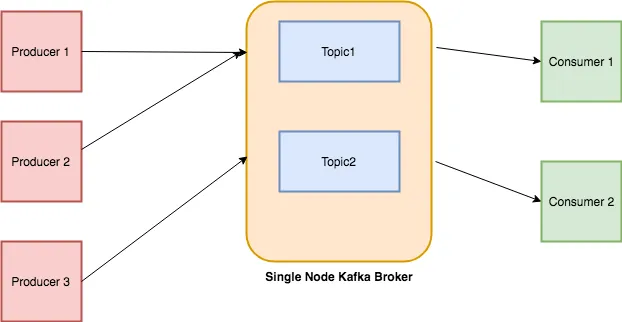
|
||||||
|
|
||||||
|
|
||||||
|
### Topics
|
||||||
|
|
||||||
|
Cada mensaje que se introduce en el sistema debe ser parte de algún topic. El topic no es más que un flujo de registros. Los mensajes se almacenan en formato clave-valor. A cada mensaje se le asigna una secuencia, llamada Offset. La salida de un mensaje podría ser una entrada de otro para un procesamiento posterior.
|
||||||
|
|
||||||
|
|
||||||
|
### Producers
|
||||||
|
|
||||||
|
Los Producers son las aplicaciones responsables de publicar datos en el sistema Kafka. Publican datos en el topic de su elección.
|
||||||
|
|
||||||
|
|
||||||
|
### Consumers
|
||||||
|
|
||||||
|
Los mensajes publicados en los topics son luego utilizados por las aplicaciones Consumers. Un consumer se suscribe al topic de su elección y consume datos.
|
||||||
|
|
||||||
|
|
||||||
|
### Broker
|
||||||
|
|
||||||
|
Cada instancia de Kafka que es responsable del intercambio de mensajes se llama Broker. Kafka puede ser utilizado como una máquina independiente o como parte de un cluster.
|
||||||
|
|
||||||
|
Trataré de explicar todo con un ejemplo simple: hay un almacén de un restaurante donde se almacenan todos los ingredientes como arroz, verduras, etc. El restaurante sirve diferentes tipos de platos: chino, desi, italiano, etc. Los chefs de cada cocina pueden referirse al almacén, elegir lo que desean y preparar los platos. Existe la posibilidad de que lo que se haga con el material crudo pueda ser usado más tarde por todos los chefs de los diferentes departamentos, por ejemplo, una salsa secreta que se usa en TODO tipo de platos. Aquí, el almacén es un broker, los proveedores de bienes son los producers, los bienes y la salsa secreta hecha por los chefs son los topics, mientras que los chefs son los consumers. Mi analogía puede sonar divertida e inexacta, pero al menos te habría ayudado a entender todo :-)
|
||||||
|
|
||||||
|
|
||||||
|
## Configuración y Ejecución
|
||||||
|
|
||||||
|
La forma más sencilla de instalar Kafka es descargar los binarios y ejecutarlo. Dado que está basado en lenguajes JVM como Scala y Java, debes asegurarte de estar usando Java 7 o superior.
|
||||||
|
|
||||||
|
Kafka está disponible en dos versiones diferentes: Una por la [fundación Apache](https://kafka.apache.org/downloads) y otra por [Confluent](https://www.confluent.io/about/) como un [paquete](https://www.confluent.io/download/). Para este tutorial, utilizaré la proporcionada por la fundación Apache. Por cierto, Confluent fue fundada por los [desarrolladores originales](https://www.confluent.io/about/) de Kafka.
|
||||||
|
|
||||||
|
|
||||||
|
## Iniciando Zookeeper
|
||||||
|
|
||||||
|
Kafka depende de Zookeeper, para hacerlo funcionar primero tendremos que ejecutar Zookeeper.
|
||||||
|
|
||||||
|
```
|
||||||
|
bin/zookeeper-server-start.sh config/zookeeper.properties
|
||||||
|
```
|
||||||
|
|
||||||
|
mostrará muchos textos en la pantalla, si ves lo siguiente significa que está correctamente configurado.
|
||||||
|
|
||||||
|
```
|
||||||
|
2018-06-10 06:36:15,023] INFO maxSessionTimeout set to -1 (org.apache.zookeeper.server.ZooKeeperServer)
|
||||||
|
[2018-06-10 06:36:15,044] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Iniciando el Servidor Kafka
|
||||||
|
|
||||||
|
A continuación, tenemos que iniciar el servidor broker de Kafka:
|
||||||
|
|
||||||
|
```
|
||||||
|
bin/kafka-server-start.sh config/server.properties
|
||||||
|
```
|
||||||
|
|
||||||
|
Y si ves el siguiente texto en la consola significa que está en funcionamiento.
|
||||||
|
|
||||||
|
```
|
||||||
|
2018-06-10 06:38:44,477] INFO Kafka commitId : fdcf75ea326b8e07 (org.apache.kafka.common.utils.AppInfoParser)
|
||||||
|
[2018-06-10 06:38:44,478] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Crear Topics
|
||||||
|
|
||||||
|
Los mensajes se publican en topics. Usa este comando para crear un nuevo topic.
|
||||||
|
|
||||||
|
```
|
||||||
|
➜ kafka_2.11-1.1.0 bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
|
||||||
|
Created topic "test".
|
||||||
|
```
|
||||||
|
|
||||||
|
También puedes listar todos los topics disponibles ejecutando el siguiente comando.
|
||||||
|
|
||||||
|
```
|
||||||
|
➜ kafka_2.11-1.1.0 bin/kafka-topics.sh --list --zookeeper localhost:2181
|
||||||
|
test
|
||||||
|
```
|
||||||
|
|
||||||
|
Como ves, imprime, test.
|
||||||
|
|
||||||
|
|
||||||
|
## Enviar Mensajes
|
||||||
|
|
||||||
|
A continuación, tenemos que enviar mensajes, los *producers* se utilizan para ese propósito. Vamos a iniciar un *producer*.
|
||||||
|
|
||||||
|
```
|
||||||
|
➜ kafka_2.11-1.1.0 bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
|
||||||
|
>Hello
|
||||||
|
>World
|
||||||
|
```
|
||||||
|
|
||||||
|
Inicias la interfaz del *producer* basada en consola que se ejecuta en el puerto 9092 por defecto. `--topic` te permite establecer el *topic* en el que se publicarán los mensajes. En nuestro caso, el *topic* es `test`.
|
||||||
|
|
||||||
|
Te muestra un prompt `>` y puedes ingresar lo que quieras.
|
||||||
|
|
||||||
|
Los mensajes se almacenan localmente en tu disco. Puedes conocer la ruta de almacenamiento verificando el valor de `log.dirs` en el archivo `config/server.properties`. Por defecto, están configurados en `/tmp/kafka-logs/`.
|
||||||
|
|
||||||
|
Si listamos esta carpeta, encontraremos una carpeta con el nombre `test-0`. Al listar su contenido encontrarás 3 archivos: `00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex`.
|
||||||
|
|
||||||
|
Si abres `00000000000000000000.log` en un editor, muestra algo como:
|
||||||
|
|
||||||
|
```
|
||||||
|
^@^@^@^@^@^@^@^@^@^@^@=^@^@^@^@^BÐØR^V^@^@^@^@^@^@^@^@^Acça<9a>o^@^@^Acça<9a>oÿÿÿÿÿÿÿÿÿÿÿÿÿÿ^@^@^@^A^V^@^@^@^A
|
||||||
|
Hello^@^@^@^@^@^@^@^@^A^@^@^@=^@^@^@^@^BÉJ^B^@^@^@^@^@^@^@^@^Acça<9f>^?^@^@^Acça<9f>^?ÿÿÿÿÿÿÿÿÿÿÿÿÿÿ^@^@^@^A^V^@^@^@^A
|
||||||
|
World^@
|
||||||
|
~
|
||||||
|
```
|
||||||
|
|
||||||
|
Parece que los datos están codificados o delimitados por separadores, no estoy seguro. Si alguien conoce este formato, que me lo haga saber.
|
||||||
|
|
||||||
|
De todos modos, Kafka proporciona una utilidad que te permite examinar cada mensaje entrante.
|
||||||
|
|
||||||
|
```
|
||||||
|
➜ kafka_2.11-1.1.0 bin/kafka-run-class.sh kafka.tools.DumpLogSegments --deep-iteration --print-data-log --files /tmp/kafka-logs/test-0/00000000000000000000.log
|
||||||
|
Dumping /tmp/kafka-logs/test-0/00000000000000000000.log
|
||||||
|
Starting offset: 0
|
||||||
|
offset: 0 position: 0 CreateTime: 1528595323503 isvalid: true keysize: -1 valuesize: 5 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: Hello
|
||||||
|
offset: 1 position: 73 CreateTime: 1528595324799 isvalid: true keysize: -1 valuesize: 5 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: World
|
||||||
|
```
|
||||||
|
|
||||||
|
Puedes ver el mensaje con otros detalles como `offset`, `position` y `CreateTime`, etc.
|
||||||
|
|
||||||
|
|
||||||
|
## Consumir Mensajes
|
||||||
|
|
||||||
|
Los mensajes que se almacenan también deben ser consumidos. Vamos a iniciar un *consumer* basado en consola.
|
||||||
|
|
||||||
|
```
|
||||||
|
➜ kafka_2.11-1.1.0 bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
|
||||||
|
```
|
||||||
|
|
||||||
|
Si lo ejecutas, volcará todos los mensajes desde el principio hasta ahora. Si solo estás interesado en consumir los mensajes después de ejecutar el *consumer*, entonces puedes simplemente omitir el interruptor `--from-beginning` y ejecutarlo. La razón por la cual no muestra los mensajes antiguos es porque el *offset* se actualiza una vez que el *consumer* envía un ACK al *broker* de Kafka sobre el procesamiento de mensajes. Puedes ver el flujo de trabajo a continuación.
|
||||||
|
|
||||||
|
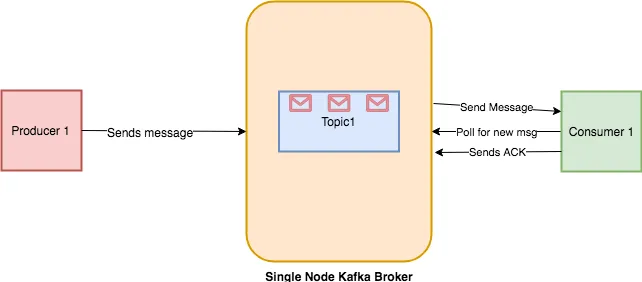
|
||||||
|
|
||||||
|
|
||||||
|
## Acceder a Kafka en Python
|
||||||
|
|
||||||
|
Hay múltiples librerías de Python disponibles para su uso:
|
||||||
|
|
||||||
|
- **Kafka-Python** — Una librería de código abierto basada en la comunidad.
|
||||||
|
- **PyKafka** — Esta librería es mantenida por Parsly y se dice que es una API Pythónica. A diferencia de Kafka-Python, no puedes crear *topics* dinámicos.
|
||||||
|
- **Confluent Python Kafka**:— Es ofrecida por Confluent como un contenedor delgado alrededor de **librdkafka**, por lo tanto, su rendimiento es mejor que el de las dos anteriores.
|
||||||
|
|
||||||
|
Para este artículo, usaremos la librería de código abierto Kafka-Python.
|
||||||
|
|
||||||
|
|
||||||
|
## Sistema de Alerta de Recetas en Kafka
|
||||||
|
|
||||||
|
En el último artículo sobre Elasticsearch, extraje datos de Allrecipes. En este artículo, voy a usar el mismo scraper como fuente de datos. El sistema que vamos a construir es un sistema de alertas que enviará notificaciones sobre las recetas si cumplen con cierto umbral de calorías. Habrá dos *topics*:
|
||||||
|
|
||||||
|
- **raw_recipes**:— Almacenará el HTML en bruto de cada receta. La idea es usar este *topic* como la fuente principal de nuestros datos que luego pueden ser procesados y transformados según sea necesario.
|
||||||
|
- **parsed_recipes**:— Como su nombre indica, este será el dato analizado de cada receta en formato JSON.
|
||||||
|
|
||||||
|
La longitud del nombre de un *topic* en Kafka no debe exceder los 249 caracteres.
|
||||||
|
|
||||||
|
Un flujo de trabajo típico se verá así:
|
||||||
|
|
||||||
|
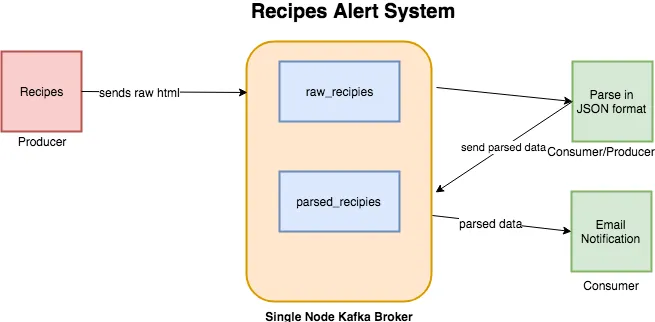
|
||||||
|
|
||||||
|
|
||||||
|
Instala `kafka-python` mediante `pip`.
|
||||||
|
|
||||||
|
```
|
||||||
|
pip install kafka-python
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Productor de Recetas en Bruto
|
||||||
|
|
||||||
|
El primer programa que vamos a escribir es el *producer*. Accederá a Allrecipes.com y obtendrá el HTML en bruto y lo almacenará en el *topic* `raw_recipes`. Archivo [producer-raw-recipes.py](./producer-raw-recipes/producer-raw-recipies.py).
|
||||||
|
|
||||||
|
Este fragmento de código extraerá el marcado de cada receta y lo devolverá en formato `list`.
|
||||||
|
|
||||||
|
A continuación, debemos crear un objeto *producer*. Antes de proceder, haremos cambios en el archivo `config/server.properties`. Debemos establecer `advertised.listeners` en `PLAINTEXT://localhost:9092`, de lo contrario, podrías experimentar el siguiente error:
|
||||||
|
|
||||||
|
```
|
||||||
|
Error encountered when producing to broker b'adnans-mbp':9092. Retrying.
|
||||||
|
```
|
||||||
|
|
||||||
|
Ahora añadiremos dos métodos: `connect_kafka_producer()` que te dará una instancia del *producer* de Kafka y `publish_message()` que solo almacenará el HTML en bruto de recetas individuales.
|
||||||
|
|
||||||
|
El __main__ se verá así.
|
||||||
|
|
||||||
|
Si funciona bien, mostrará la siguiente salida:
|
||||||
|
|
||||||
|
```
|
||||||
|
/anaconda3/anaconda/bin/python /Development/DataScience/Kafka/kafka-recipie-alert/producer-raw-recipies.py
|
||||||
|
Accessing list
|
||||||
|
Processing..https://www.allrecipes.com/recipe/20762/california-coleslaw/
|
||||||
|
Processing..https://www.allrecipes.com/recipe/8584/holiday-chicken-salad/
|
||||||
|
Processing..https://www.allrecipes.com/recipe/80867/cran-broccoli-salad/
|
||||||
|
Message published successfully.
|
||||||
|
Message published successfully.
|
||||||
|
Message published successfully.Process finished with exit code 0
|
||||||
|
```
|
||||||
|
|
||||||
|
Estoy usando una herramienta GUI, llamada Kafka Tool, para navegar por los mensajes publicados recientemente. Está disponible para OSX, Windows y Linux.
|
||||||
|
|
||||||
|
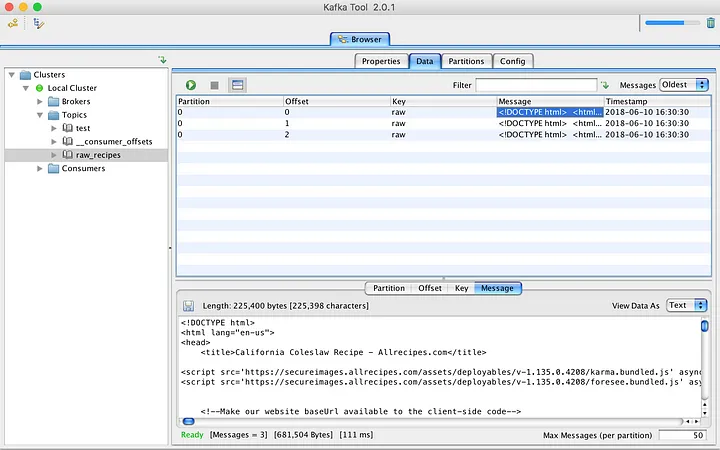
|
||||||
|
|
||||||
|
|
||||||
|
## Analizador de Recetas
|
||||||
|
|
||||||
|
Archivo [producer-consumer-parse-recipes.py](./producer-consumer-parse-recipes/producer-consumer-parse-recipes.py).
|
||||||
|
|
||||||
|
El siguiente script que vamos a escribir servirá como *consumer* y *producer*. Primero consumirá datos del *topic* `raw_recipes`, analizará y transformará los datos en JSON, y luego los publicará en el *topic* `parsed_recipes`. A continuación se muestra el código que obtendrá datos HTML del *topic* `raw_recipes`, los analizará y luego los alimentará al *topic* `parsed_recipes`.
|
||||||
|
|
||||||
|
`KafkaConsumer` acepta algunos parámetros además del nombre del *topic* y la dirección del host. Al proporcionar `auto_offset_reset='earliest'` le estás diciendo a Kafka que devuelva mensajes desde el principio. El parámetro `consumer_timeout_ms` ayuda al *consumer* a desconectarse después de cierto período de tiempo. Una vez desconectado, puedes cerrar el flujo del *consumer* llamando a `consumer.close()`.
|
||||||
|
|
||||||
|
Después de esto, estoy utilizando las mismas rutinas para conectar *producers* y publicar datos analizados en el nuevo *topic*. El navegador KafkaTool da buenas noticias sobre los mensajes almacenados recientemente.
|
||||||
|
|
||||||
|
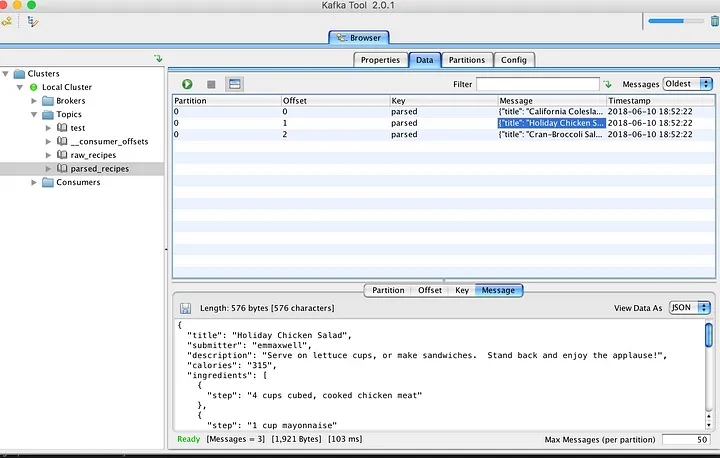
|
||||||
|
|
||||||
|
Hasta ahora, todo bien. Almacenamos las recetas en formato bruto y JSON para uso futuro. A continuación, tenemos que escribir un *consumer* que se conecte con el *topic* `parsed_recipes` y genere una alerta si se cumple cierto criterio de `calories`.
|
||||||
|
|
||||||
|
El JSON se decodifica y luego se verifica la cantidad de calorías, se emite una notificación una vez que se cumple el criterio.
|
||||||
|
|
||||||
|
|
||||||
|
## Ya lo hemos probado en local, ¡ahora a dockerizarlo!
|
||||||
|
|
||||||
|
Ahora que hemos probado el sistema localmente, es hora de dockerizarlo para facilitar su despliegue y escalabilidad. Vamos a crear imágenes Docker para cada uno de los scripts de Python y configurar un entorno de Docker Compose para orquestar todo.
|
||||||
|
|
||||||
|
Esctrutura de directorios:
|
||||||
|
|
||||||
|
```
|
||||||
|
.
|
||||||
|
├── docker-compose.yml
|
||||||
|
├── producer-raw-recipes/
|
||||||
|
│ ├── Dockerfile
|
||||||
|
│ └── producer-raw-recipes.py
|
||||||
|
├── producer-consumer-parse-recipes/
|
||||||
|
│ ├── Dockerfile
|
||||||
|
│ └── producer_consumer_parse_recipes.py
|
||||||
|
└── consumer-notification/
|
||||||
|
├── Dockerfile
|
||||||
|
└── consumer-notification.py
|
||||||
|
```
|
||||||
|
|
||||||
|
Ficheros docker:
|
||||||
|
- [docker-compose.yaml](./docker-compose.yml)
|
||||||
|
- [Dockerfile producer-raw-recipes](./producer-raw-recipes/Dockerfile)
|
||||||
|
- [Dockerfile producer-consumer-parse-recipes](./producer-consumer-parse-recipes/Dockerfile)
|
||||||
|
- [Dockerfile consumer-notification](./consumer-notification/Dockerfile)
|
||||||
|
|
||||||
|
Los ficheros Dockerfile construye las imágenes Docker para cada uno de los scripts de Python.
|
||||||
|
|
||||||
|
El archivo Docker Compose configura los siguientes servicios y las aplicaciones que se ejecutarán:
|
||||||
|
|
||||||
|
- **Zookeeper**: Para coordinar el cluster de Kafka.
|
||||||
|
- **Kafka**: El broker de Kafka.
|
||||||
|
- **Kafdrop**: Una interfaz web para Kafka.
|
||||||
|
- **producer-raw-recipes**: El productor que envía recetas en bruto.
|
||||||
|
- **producer-consumer-parse-recipes**: El productor-consumidor que analiza las recetas y las envía a un nuevo topic.
|
||||||
|
- **consumer-notification**: El consumidor que emite alertas sobre recetas con alto contenido calórico.
|
||||||
|
|
||||||
|
El docker-compose es muy completo con healthchecks, dependencias, volumenes, etc.
|
||||||
|
|
||||||
|
### Construir y Ejecutar los Contenedores
|
||||||
|
|
||||||
|
Para construir y ejecutar los contenedores, usa el siguiente comando en el directorio raíz del proyecto:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker-compose up --build
|
||||||
|
```
|
||||||
|
|
||||||
|
Este comando construye las imágenes Docker y levanta los contenedores definidos en `docker-compose.yml`.
|
||||||
|
|
||||||
|
|
||||||
|
### Verificación
|
||||||
|
|
||||||
|
Para verificar que todo está funcionando correctamente:
|
||||||
|
|
||||||
|
1. Asegúrate de que todos los contenedores están en ejecución usando `docker ps`.
|
||||||
|
2. Revisa los logs de cada contenedor con `docker logs <container_name>` para asegurar que no haya errores. Con lazydocker puedes ver los logs de todos los contenedores rápidamente.
|
||||||
|
3. Puedes usar herramientas GUI como Kafka Tool o `kafka-console-consumer.sh` y `kafka-console-producer.sh` para interactuar con los topics y los mensajes.
|
||||||
|
4. Panel de control de Kafdrop en `http://localhost:9000`.
|
||||||
|
|
||||||
|
|
||||||
|
## Conclusión
|
||||||
|
|
||||||
|
Kafka es un sistema de mensajería de publicación-suscripción escalable y tolerante a fallos que te permite construir aplicaciones distribuidas. Debido a su [alto rendimiento y eficiencia](http://searene.me/2017/07/09/Why-is-Kafka-so-fast/), se está volviendo popular entre las empresas que producen grandes cantidades de datos desde diversas fuentes externas y desean proporcionar resultados en tiempo real a partir de ellos. Solo he cubierto lo esencial. Explora los documentos y las implementaciones existentes, y te ayudará a entender cómo podría ser la mejor opción para tu próximo sistema.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
@@ -0,0 +1,17 @@
|
|||||||
|
# Usa una imagen base de Python
|
||||||
|
FROM python:3.9-slim
|
||||||
|
|
||||||
|
# Configura el directorio de trabajo
|
||||||
|
WORKDIR /app
|
||||||
|
|
||||||
|
# Copia el archivo de requisitos al contenedor
|
||||||
|
COPY requirements.txt /app/
|
||||||
|
|
||||||
|
# Instala las dependencias
|
||||||
|
RUN pip install --no-cache-dir -r requirements.txt
|
||||||
|
|
||||||
|
# Copia el script de Python al contenedor
|
||||||
|
COPY consumer-notification.py /app/
|
||||||
|
|
||||||
|
# Comando por defecto para ejecutar el script
|
||||||
|
CMD ["python", "consumer-notification.py"]
|
||||||
@@ -0,0 +1,66 @@
|
|||||||
|
import json
|
||||||
|
import logging
|
||||||
|
from time import sleep
|
||||||
|
from kafka import KafkaConsumer
|
||||||
|
|
||||||
|
# Configuración del registro
|
||||||
|
logging.basicConfig(
|
||||||
|
level=logging.INFO,
|
||||||
|
format='%(asctime)s - %(levelname)s - %(message)s'
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
|
||||||
|
# Nombre del tema de Kafka del que se consumen los mensajes
|
||||||
|
parsed_topic_name = 'parsed_recipes'
|
||||||
|
|
||||||
|
# Umbral de calorías para la notificación
|
||||||
|
calories_threshold = 200
|
||||||
|
|
||||||
|
# Crear un consumidor de Kafka
|
||||||
|
consumer = KafkaConsumer(
|
||||||
|
parsed_topic_name,
|
||||||
|
auto_offset_reset='earliest', # Inicia desde el 1er mensaje si es nuevo
|
||||||
|
bootstrap_servers=['kafka:9092'], # Servidor Kafka
|
||||||
|
api_version=(0, 10), # Versión de la API de Kafka
|
||||||
|
# Tiempo máx. de espera mensajes (milisegundos)
|
||||||
|
consumer_timeout_ms=2000
|
||||||
|
)
|
||||||
|
|
||||||
|
logging.info('[+] Iniciando el consumidor de notificaciones...')
|
||||||
|
|
||||||
|
try:
|
||||||
|
|
||||||
|
for msg in consumer:
|
||||||
|
|
||||||
|
# Decodificar el mensaje de JSON
|
||||||
|
record = json.loads(msg.value)
|
||||||
|
|
||||||
|
# Obtener el valor de calorías
|
||||||
|
calories = int(record.get('calories', 0))
|
||||||
|
title = record.get('title', 'Sin título') # Obtener el título
|
||||||
|
|
||||||
|
# Verificar si las calorías exceden el umbral
|
||||||
|
if calories > calories_threshold:
|
||||||
|
logging.warning(
|
||||||
|
f'[!] Alerta: {title} tiene {calories} calorías')
|
||||||
|
|
||||||
|
# Esperar 5 segundos antes de procesar el siguiente mensaje
|
||||||
|
sleep(5)
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
|
||||||
|
logging.error(
|
||||||
|
'[!] Error en el consumidor de notificaciones', exc_info=True)
|
||||||
|
|
||||||
|
finally:
|
||||||
|
|
||||||
|
if consumer is not None:
|
||||||
|
consumer.close() # Cerrar el consumidor al finalizar
|
||||||
|
logging.info('[i] Consumidor cerrado.')
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
|
||||||
|
main()
|
||||||
@@ -0,0 +1 @@
|
|||||||
|
kafka-python
|
||||||
137
catch-all/05_infra_test/03_kafka/docker-compose.yaml
Normal file
137
catch-all/05_infra_test/03_kafka/docker-compose.yaml
Normal file
@@ -0,0 +1,137 @@
|
|||||||
|
services:
|
||||||
|
zookeeper:
|
||||||
|
image: bitnami/zookeeper:latest
|
||||||
|
container_name: zookeeper
|
||||||
|
ports:
|
||||||
|
- "2181:2181"
|
||||||
|
volumes:
|
||||||
|
- "zookeeper_data:/bitnami"
|
||||||
|
environment:
|
||||||
|
ALLOW_ANONYMOUS_LOGIN: "yes"
|
||||||
|
networks:
|
||||||
|
- kafka-network
|
||||||
|
healthcheck:
|
||||||
|
test: ["CMD-SHELL", "nc -z localhost 2181"]
|
||||||
|
interval: 10s
|
||||||
|
retries: 5
|
||||||
|
start_period: 10s
|
||||||
|
timeout: 5s
|
||||||
|
|
||||||
|
kafka:
|
||||||
|
image: bitnami/kafka:latest
|
||||||
|
container_name: kafka
|
||||||
|
ports:
|
||||||
|
- "9092:9092"
|
||||||
|
volumes:
|
||||||
|
- "kafka_data:/bitnami"
|
||||||
|
environment:
|
||||||
|
KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:9092,OUTSIDE://localhost:9093
|
||||||
|
KAFKA_LISTENERS: INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9093
|
||||||
|
KAFKA_LISTENER_NAME: INSIDE
|
||||||
|
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
|
||||||
|
KAFKA_LISTENER_SECURITY_PROTOCOL: PLAINTEXT
|
||||||
|
KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE
|
||||||
|
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
|
||||||
|
networks:
|
||||||
|
- kafka-network
|
||||||
|
depends_on:
|
||||||
|
zookeeper:
|
||||||
|
condition: service_healthy
|
||||||
|
healthcheck:
|
||||||
|
test: ["CMD-SHELL", "kafka-broker-api-versions.sh --bootstrap-server localhost:9092"]
|
||||||
|
interval: 10s
|
||||||
|
retries: 10
|
||||||
|
start_period: 60s
|
||||||
|
timeout: 10s
|
||||||
|
|
||||||
|
kafdrop:
|
||||||
|
image: obsidiandynamics/kafdrop:latest
|
||||||
|
container_name: kafdrop
|
||||||
|
ports:
|
||||||
|
- "9000:9000"
|
||||||
|
environment:
|
||||||
|
KAFKA_BROKERCONNECT: kafka:9092
|
||||||
|
networks:
|
||||||
|
- kafka-network
|
||||||
|
depends_on:
|
||||||
|
kafka:
|
||||||
|
condition: service_healthy
|
||||||
|
healthcheck:
|
||||||
|
test: ["CMD-SHELL", "curl -f http://localhost:9000/ || exit 1"]
|
||||||
|
interval: 10s
|
||||||
|
retries: 5
|
||||||
|
start_period: 10s
|
||||||
|
timeout: 5s
|
||||||
|
|
||||||
|
producer_raw_recipes:
|
||||||
|
container_name: producer-raw-recipes
|
||||||
|
build:
|
||||||
|
context: ./producer-raw-recipes
|
||||||
|
networks:
|
||||||
|
- kafka-network
|
||||||
|
depends_on:
|
||||||
|
kafdrop:
|
||||||
|
condition: service_healthy
|
||||||
|
kafka:
|
||||||
|
condition: service_healthy
|
||||||
|
zookeeper:
|
||||||
|
condition: service_healthy
|
||||||
|
healthcheck:
|
||||||
|
test: ["CMD-SHELL", "bash -c 'echo > /dev/tcp/kafka/9092' || exit 1"]
|
||||||
|
interval: 10s
|
||||||
|
retries: 5
|
||||||
|
start_period: 10s
|
||||||
|
timeout: 5s
|
||||||
|
|
||||||
|
|
||||||
|
producer_consumer_parse_recipes:
|
||||||
|
container_name: producer-consumer-parse-recipes
|
||||||
|
build:
|
||||||
|
context: ./producer-consumer-parse-recipes
|
||||||
|
networks:
|
||||||
|
- kafka-network
|
||||||
|
depends_on:
|
||||||
|
kafdrop:
|
||||||
|
condition: service_healthy
|
||||||
|
kafka:
|
||||||
|
condition: service_healthy
|
||||||
|
zookeeper:
|
||||||
|
condition: service_healthy
|
||||||
|
producer_raw_recipes:
|
||||||
|
condition: service_healthy
|
||||||
|
healthcheck:
|
||||||
|
test: ["CMD-SHELL", "bash -c 'echo > /dev/tcp/kafka/9092' || exit 1"]
|
||||||
|
interval: 10s
|
||||||
|
retries: 5
|
||||||
|
start_period: 10s
|
||||||
|
timeout: 5s
|
||||||
|
|
||||||
|
consumer_notification:
|
||||||
|
container_name: consumer-notification
|
||||||
|
build:
|
||||||
|
context: ./consumer-notification
|
||||||
|
networks:
|
||||||
|
- kafka-network
|
||||||
|
depends_on:
|
||||||
|
kafdrop:
|
||||||
|
condition: service_healthy
|
||||||
|
kafka:
|
||||||
|
condition: service_healthy
|
||||||
|
zookeeper:
|
||||||
|
condition: service_healthy
|
||||||
|
healthcheck:
|
||||||
|
test: ["CMD-SHELL", "bash -c 'echo > /dev/tcp/kafka/9092' || exit 1"]
|
||||||
|
interval: 10s
|
||||||
|
retries: 5
|
||||||
|
start_period: 10s
|
||||||
|
timeout: 5s
|
||||||
|
|
||||||
|
networks:
|
||||||
|
kafka-network:
|
||||||
|
driver: bridge
|
||||||
|
|
||||||
|
volumes:
|
||||||
|
zookeeper_data:
|
||||||
|
driver: local
|
||||||
|
kafka_data:
|
||||||
|
driver: local
|
||||||
@@ -0,0 +1,17 @@
|
|||||||
|
# Usa una imagen base de Python
|
||||||
|
FROM python:3.9-slim
|
||||||
|
|
||||||
|
# Configura el directorio de trabajo
|
||||||
|
WORKDIR /app
|
||||||
|
|
||||||
|
# Copia el archivo de requisitos al contenedor
|
||||||
|
COPY requirements.txt /app/
|
||||||
|
|
||||||
|
# Instala las dependencias
|
||||||
|
RUN pip install --no-cache-dir -r requirements.txt
|
||||||
|
|
||||||
|
# Copia el script de Python al contenedor
|
||||||
|
COPY producer-consumer-parse-recipes.py /app/
|
||||||
|
|
||||||
|
# Comando por defecto para ejecutar el script
|
||||||
|
CMD ["python", "producer-consumer-parse-recipes.py"]
|
||||||
@@ -0,0 +1,165 @@
|
|||||||
|
import json
|
||||||
|
import logging
|
||||||
|
from time import sleep
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
from kafka import KafkaConsumer, KafkaProducer
|
||||||
|
|
||||||
|
# Configuración del registro
|
||||||
|
logging.basicConfig(level=logging.INFO,
|
||||||
|
format='%(asctime)s - %(levelname)s - %(message)s')
|
||||||
|
|
||||||
|
|
||||||
|
def publish_message(producer_instance, topic_name, key, value):
|
||||||
|
"""
|
||||||
|
Publica un mensaje en el tema de Kafka especificado.
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
key_bytes = bytes(key, encoding='utf-8') # Convertir clave a bytes
|
||||||
|
value_bytes = bytes(value, encoding='utf-8') # Convertir valor a bytes
|
||||||
|
producer_instance.send( # Enviar mensaje
|
||||||
|
topic_name, key=key_bytes,
|
||||||
|
value=value_bytes
|
||||||
|
)
|
||||||
|
producer_instance.flush() # Asegurar que el mensaje ha sido enviado
|
||||||
|
|
||||||
|
logging.info('[i] Mensaje publicado con éxito.')
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
|
||||||
|
logging.error('[!] Error al publicar mensaje', exc_info=True)
|
||||||
|
|
||||||
|
|
||||||
|
def connect_kafka_producer():
|
||||||
|
"""
|
||||||
|
Conecta y devuelve una instancia del productor de Kafka.
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
producer = KafkaProducer(
|
||||||
|
bootstrap_servers=['kafka:9092'], # Servidor Kafka
|
||||||
|
api_version=(0, 10) # Versión de la API de Kafka
|
||||||
|
)
|
||||||
|
|
||||||
|
logging.info('[i] Conectado con éxito al productor de Kafka.')
|
||||||
|
|
||||||
|
return producer
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
|
||||||
|
logging.error('[!] Error al conectar con Kafka', exc_info=True)
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def parse(markup):
|
||||||
|
"""
|
||||||
|
Analiza el HTML y extrae la información de la receta.
|
||||||
|
"""
|
||||||
|
|
||||||
|
title = '-'
|
||||||
|
submit_by = '-'
|
||||||
|
description = '-'
|
||||||
|
calories = 0
|
||||||
|
ingredients = []
|
||||||
|
rec = {}
|
||||||
|
|
||||||
|
try:
|
||||||
|
soup = BeautifulSoup(markup, 'lxml') # Analizar HTML con BeautifulSoup
|
||||||
|
|
||||||
|
# Actualizar selectores CSS para el título, descripción, ingredientes y calorías
|
||||||
|
title_section = soup.select_one('h1.headline.heading-content') # Título
|
||||||
|
submitter_section = soup.select_one('span.author-name') # Autor
|
||||||
|
description_section = soup.select_one('div.recipe-summary > p') # Descripción
|
||||||
|
ingredients_section = soup.select('li.ingredients-item') # Ingredientes
|
||||||
|
calories_section = soup.select_one('span.calorie-count') # Calorías
|
||||||
|
|
||||||
|
# Extraer calorías
|
||||||
|
if calories_section:
|
||||||
|
calories = calories_section.get_text(strip=True).replace('cals', '').strip()
|
||||||
|
|
||||||
|
# Extraer ingredientes
|
||||||
|
if ingredients_section:
|
||||||
|
for ingredient in ingredients_section:
|
||||||
|
ingredient_text = ingredient.get_text(strip=True)
|
||||||
|
if 'Add all ingredients to list' not in ingredient_text and ingredient_text != '':
|
||||||
|
ingredients.append({'step': ingredient_text})
|
||||||
|
|
||||||
|
# Extraer descripción
|
||||||
|
if description_section:
|
||||||
|
description = description_section.get_text(strip=True)
|
||||||
|
|
||||||
|
# Extraer nombre del autor
|
||||||
|
if submitter_section:
|
||||||
|
submit_by = submitter_section.get_text(strip=True)
|
||||||
|
|
||||||
|
# Extraer título
|
||||||
|
if title_section:
|
||||||
|
title = title_section.get_text(strip=True)
|
||||||
|
|
||||||
|
# Crear diccionario con la información de la receta
|
||||||
|
rec = {
|
||||||
|
'title': title,
|
||||||
|
'submitter': submit_by,
|
||||||
|
'description': description,
|
||||||
|
'calories': calories,
|
||||||
|
'ingredients': ingredients
|
||||||
|
}
|
||||||
|
|
||||||
|
logging.info(f"[i] Receta extraída: {rec}")
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
|
||||||
|
logging.error('[!] Error en parsing', exc_info=True)
|
||||||
|
|
||||||
|
return json.dumps(rec)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
"""
|
||||||
|
Ejecuta el proceso de consumo y publicación de mensajes.
|
||||||
|
"""
|
||||||
|
|
||||||
|
topic_name = 'raw_recipes'
|
||||||
|
parsed_topic_name = 'parsed_recipes'
|
||||||
|
parsed_records = []
|
||||||
|
|
||||||
|
# Crear un consumidor de Kafka
|
||||||
|
consumer = KafkaConsumer(
|
||||||
|
topic_name,
|
||||||
|
auto_offset_reset='earliest',
|
||||||
|
bootstrap_servers=['kafka:9092'],
|
||||||
|
api_version=(0, 10),
|
||||||
|
consumer_timeout_ms=2000
|
||||||
|
)
|
||||||
|
|
||||||
|
logging.info('[i] Iniciando el consumidor para parsing...')
|
||||||
|
|
||||||
|
try:
|
||||||
|
for msg in consumer:
|
||||||
|
html = msg.value
|
||||||
|
result = parse(html) # Analizar el HTML
|
||||||
|
parsed_records.append(result)
|
||||||
|
|
||||||
|
consumer.close() # Cerrar el consumidor
|
||||||
|
|
||||||
|
logging.info('[i] Consumidor cerrado.')
|
||||||
|
|
||||||
|
if parsed_records:
|
||||||
|
logging.info('[+] Publicando registros...')
|
||||||
|
producer = connect_kafka_producer()
|
||||||
|
|
||||||
|
if producer:
|
||||||
|
for rec in parsed_records:
|
||||||
|
publish_message(producer, parsed_topic_name, 'parsed', rec)
|
||||||
|
|
||||||
|
producer.close() # Cerrar el productor
|
||||||
|
else:
|
||||||
|
logging.error('[!] El productor de Kafka no está disponible.')
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
logging.error('[!] Error en el productor-consumer', exc_info=True)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
@@ -0,0 +1,3 @@
|
|||||||
|
kafka-python
|
||||||
|
requests
|
||||||
|
beautifulsoup4
|
||||||
@@ -0,0 +1,17 @@
|
|||||||
|
# Usa una imagen base de Python
|
||||||
|
FROM python:3.9-slim
|
||||||
|
|
||||||
|
# Configura el directorio de trabajo
|
||||||
|
WORKDIR /app
|
||||||
|
|
||||||
|
# Copia el archivo de requisitos al contenedor
|
||||||
|
COPY requirements.txt /app/
|
||||||
|
|
||||||
|
# Instala las dependencias
|
||||||
|
RUN pip install --no-cache-dir -r requirements.txt
|
||||||
|
|
||||||
|
# Copia el script de Python al contenedor
|
||||||
|
COPY producer-raw-recipes.py /app/
|
||||||
|
|
||||||
|
# Comando por defecto para ejecutar el script
|
||||||
|
CMD ["python", "producer-raw-recipes.py"]
|
||||||
@@ -0,0 +1,168 @@
|
|||||||
|
import requests
|
||||||
|
from time import sleep
|
||||||
|
import logging
|
||||||
|
from bs4 import BeautifulSoup
|
||||||
|
from kafka import KafkaProducer
|
||||||
|
|
||||||
|
|
||||||
|
# Configuración del registro
|
||||||
|
logging.basicConfig(level=logging.INFO,
|
||||||
|
format='%(asctime)s - %(levelname)s - %(message)s')
|
||||||
|
|
||||||
|
|
||||||
|
def publish_message(producer_instance, topic_name, key, value):
|
||||||
|
"""
|
||||||
|
Publica un mensaje en el tema de Kafka especificado.
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
|
||||||
|
key_bytes = bytes(key, encoding='utf-8') # Convertir clave a bytes
|
||||||
|
value_bytes = bytes(value, encoding='utf-8') # Convertir valor a bytes
|
||||||
|
producer_instance.send( # Enviar mensaje
|
||||||
|
topic_name, key=key_bytes, value=value_bytes
|
||||||
|
)
|
||||||
|
producer_instance.flush() # Asegurar que el mensaje ha sido enviado
|
||||||
|
logging.info('[+] Mensaje publicado con éxito.')
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
|
||||||
|
logging.error('[!] Error al publicar mensaje', exc_info=True)
|
||||||
|
|
||||||
|
|
||||||
|
def connect_kafka_producer():
|
||||||
|
"""
|
||||||
|
Conecta y devuelve una instancia del productor de Kafka.
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
|
||||||
|
producer = KafkaProducer(
|
||||||
|
bootstrap_servers=['kafka:9092'], # Servidor Kafka
|
||||||
|
api_version=(0, 10) # Versión de la API de Kafka
|
||||||
|
)
|
||||||
|
|
||||||
|
logging.info('[i] Conectado con éxito al productor de Kafka.')
|
||||||
|
|
||||||
|
return producer
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
|
||||||
|
logging.error('[!] Error al conectar con Kafka', exc_info=True)
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
def fetch_raw(recipe_url):
|
||||||
|
"""
|
||||||
|
Obtiene el HTML sin procesar de la URL de la receta.
|
||||||
|
"""
|
||||||
|
|
||||||
|
html = None
|
||||||
|
logging.info('[i] Procesando... {}'.format(recipe_url))
|
||||||
|
|
||||||
|
try:
|
||||||
|
|
||||||
|
r = requests.get(recipe_url, headers=headers)
|
||||||
|
|
||||||
|
if r.status_code == 200:
|
||||||
|
html = r.text
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
|
||||||
|
logging.error(
|
||||||
|
'[!] Error al acceder al HTML sin procesar',
|
||||||
|
exc_info=True
|
||||||
|
)
|
||||||
|
|
||||||
|
return html.strip() if html else ''
|
||||||
|
|
||||||
|
|
||||||
|
def get_recipes():
|
||||||
|
"""
|
||||||
|
Obtiene una lista de recetas de la URL de origen.
|
||||||
|
"""
|
||||||
|
|
||||||
|
recipes = []
|
||||||
|
url = 'https://www.allrecipes.com/recipes/96/salad/'
|
||||||
|
|
||||||
|
logging.info('[i] Accediendo a la lista de recetas...')
|
||||||
|
|
||||||
|
try:
|
||||||
|
r = requests.get(url, headers=headers)
|
||||||
|
logging.info('[i] Código de respuesta: {}'.format(r.status_code))
|
||||||
|
|
||||||
|
if r.status_code == 200:
|
||||||
|
logging.info('[i] Página accesible, procesando...')
|
||||||
|
|
||||||
|
html = r.text
|
||||||
|
soup = BeautifulSoup(html, 'lxml')
|
||||||
|
|
||||||
|
# Selecciona los elementos <a> con la clase mntl-card-list-items
|
||||||
|
links = soup.select('a.mntl-card-list-items')
|
||||||
|
|
||||||
|
logging.info('[i] Se encontraron {} recetas'.format(len(links)))
|
||||||
|
|
||||||
|
for link in links:
|
||||||
|
# Obtiene el título del texto de card__title-text
|
||||||
|
recipe_title = link.select_one(
|
||||||
|
'.card__title-text').get_text(strip=True)
|
||||||
|
recipe_url = link['href']
|
||||||
|
logging.info(
|
||||||
|
f'[i] Procesando receta: {recipe_title}, enlace: {recipe_url}'
|
||||||
|
)
|
||||||
|
|
||||||
|
sleep(2)
|
||||||
|
recipe_html = fetch_raw(recipe_url)
|
||||||
|
|
||||||
|
if recipe_html:
|
||||||
|
recipes.append(recipe_html)
|
||||||
|
|
||||||
|
logging.info(
|
||||||
|
'[i] Se obtuvieron {} recetas en total.'.format(len(recipes)))
|
||||||
|
|
||||||
|
else:
|
||||||
|
logging.error(
|
||||||
|
'[!] No se pudo acceder a la página de recetas, código de respuesta: {}'.format(r.status_code))
|
||||||
|
|
||||||
|
except Exception as ex:
|
||||||
|
logging.error('[!] Error en get_recipes', exc_info=True)
|
||||||
|
|
||||||
|
return recipes
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
"""
|
||||||
|
Ejecuta el proceso de obtención y publicación de recetas.
|
||||||
|
"""
|
||||||
|
|
||||||
|
global headers
|
||||||
|
headers = {
|
||||||
|
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
|
||||||
|
'Pragma': 'no-cache'
|
||||||
|
}
|
||||||
|
|
||||||
|
logging.info('Iniciando el productor de recetas...')
|
||||||
|
|
||||||
|
all_recipes = get_recipes() # Obtener recetas
|
||||||
|
|
||||||
|
if all_recipes:
|
||||||
|
|
||||||
|
producer = connect_kafka_producer() # Conectar con Kafka
|
||||||
|
|
||||||
|
if producer:
|
||||||
|
|
||||||
|
for recipe in all_recipes:
|
||||||
|
|
||||||
|
publish_message(producer, 'raw_recipes', 'raw', recipe.strip())
|
||||||
|
|
||||||
|
producer.close() # Cerrar el productor
|
||||||
|
|
||||||
|
else:
|
||||||
|
|
||||||
|
logging.error('[!] El productor de Kafka no está disponible.')
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
|
||||||
|
main()
|
||||||
@@ -0,0 +1,4 @@
|
|||||||
|
kafka-python
|
||||||
|
requests
|
||||||
|
beautifulsoup4
|
||||||
|
lxml
|
||||||
1
catch-all/05_infra_test/05_prometheus_grafana/README.md
Normal file
1
catch-all/05_infra_test/05_prometheus_grafana/README.md
Normal file
@@ -0,0 +1 @@
|
|||||||
|
# Prometheus - Grafana (próximamente)
|
||||||
1
catch-all/05_infra_test/06_sonarqube/README.md
Normal file
1
catch-all/05_infra_test/06_sonarqube/README.md
Normal file
@@ -0,0 +1 @@
|
|||||||
|
# SonarQube (próximamente)
|
||||||
Reference in New Issue
Block a user