Pruebas con rabbitmq
Índice de contenidos:
- Pruebas con rabbitmq
Despliegue rabbitmq con docker
Para desplegar RabbitMQ rápidamente, puedes usar Docker. Ejecuta el siguiente comando para iniciar un contenedor con RabbitMQ y su consola de gestión:
docker run -d --hostname my-rabbit --name some-rabbit -p 8080:15672 -p 5672:5672 rabbitmq:3-management
Si prefieres usar docker-compose, utiliza el archivo docker-compose.yaml con el siguiente comando:
docker compose up -d
Pruebas
Pruebas extraídas de los tutoriales de la documentación oficial de RabbitMQ.
Hello World
Lo más sencillo que hace algo.
Tenemos que diferenciar algunos conceptos:
- Producer: es el que envía mensajes.
- Queue: es donde se almacenan los mensajes.
- Consumer: es el que recibe mensajes.

Vamos a programar un producer y un consumer en Python.
RabbitMQ habla múltiples protocolos. Este tutorial utiliza AMQP 0-9-1, que es un protocolo abierto de propósito general para mensajería.
Hay un gran número de clientes para RabbitMQ en muchos idiomas diferentes. En esta serie de tutoriales vamos a usar Pika 1.0.0, que es el cliente Python recomendado por el equipo de RabbitMQ. Para instalarlo puedes usar la herramienta de gestión de paquetes pip:
pip install pika --upgrade
Nuestro primer programa send.py será el producer que enviará un único mensaje a la cola. Este script también crea la cola hola.
El programa receive.py será el consumer que recibirá mensajes de la cola y los imprimirá en pantalla.
Desde la instalación de rabbitmq puedes ver qué colas tiene RabbitMQ y cuántos mensajes hay en ellas con rabbitmqctl:
sudo rabbitmqctl list_queues
Antes tendrás que entrar en el contenedor de rabbitmq:
docker exec -it rabbitmq-server bash
Ahora, para probarlo, ejecuta el producer y el consumer en dos terminales diferentes:
cd hello-world
python send.py
python receive.py
Work Queues
Reparto de tareas entre los trabajadores (el modelo de consumidores competidores).
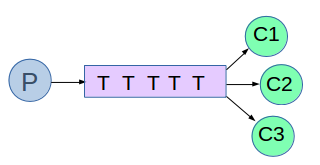
Antes hemos enviado un mensaje que contenía ¡Hola Mundo!. Ahora enviaremos cadenas que representan tareas complejas. No tenemos una tarea del mundo real, como imágenes para ser redimensionadas o archivos pdf para ser renderizados, así que vamos a fingir que estamos ocupados usando la función time.sleep(). Tomaremos el número de puntos de la cadena como su complejidad; cada punto representará un segundo de «trabajo». Por ejemplo, una tarea falsa descrita por Hola... tardará tres segundos.
Vamos a modificar el anterior send.py para permitir el envío de mensajes arbitrarios desde la línea de comando. Le llamaremos new_task.py.
También modificaremos receive.py para simular un segundo trabajao por cada punto en el cuerpo del mensaje. Como sacará mensajes de la cola y realizará la tarea le llamaremos worker.py.
Ahora, si ejecutamos dos veces o más el script worker.py, veremos cómo se reparten las tareas entre los dos consumidores.
En dos terminales distintas:
cd 02work-queues
python worker.py
Y en la tercera terminal enviaremos trabajos:
python new_task.py Primer mensaje.
python new_task.py Segundo mensaje..
python new_task.py Tercer mensaje...
python new_task.py Cuarto mensaje....
python new_task.py Quinto mensaje.....
Por defecto, RabbitMQ enviará cada mensaje al siguiente consumidor, en secuencia. Por término medio, cada consumidor recibirá el mismo número de mensajes. Esta forma de distribuir mensajes se llama round-robin.
Para asegurarse de que un mensaje nunca se pierde, RabbitMQ soporta acuses de recibo de mensajes. Un ack(nowledgement) es enviado de vuelta por el consumidor para decirle a RabbitMQ que un mensaje en particular ha sido recibido, procesado y que RabbitMQ es libre de borrarlo.
Apunte:
ackes una abreviatura de acknowledgement (reconocimiento). En el caso de que un consumidor muera (su conexión se cierre, por ejemplo) sin enviar un ack, RabbitMQ entenderá que no ha procesado el mensaje y lo reenviará a otro consumidor. Si hay otros consumidores conectados a la cola, se les enviará el mensaje.
Acuse de recibo olvidado
Es un error común olvidar el basic_ack. Los mensajes se volverán a entregar cuando tu cliente salga (lo que puede parecer una redistribución aleatoria), pero RabbitMQ consumirá cada vez más memoria ya que no será capaz de liberar ningún mensaje no empaquetado.
Para depurar este tipo de errores puedes usar rabbitmqctl para imprimir el campo messages_unacknowledged:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Publish/Subscribe
A diferencia de las colas de trabajo, donde cada tarea se entrega a un solo trabajador, este tutorial demuestra el patrón de publicación/suscripción, que entrega mensajes a múltiples consumidores.

El ejemplo es un sistema de registro con dos programas: uno que emite mensajes de registro y otro que los recibe y los imprime.
Cada instancia del programa receptor recibe todos los mensajes, permitiendo que los registros se dirijan al disco o se visualicen en pantalla.
Enfoque:
El ejemplo es un sistema de registro con dos programas: uno que emite mensajes de registro y otro que los recibe y los imprime.
Cada instancia del programa receptor recibe todos los mensajes, permitiendo que los registros se dirijan al disco o se visualicen en pantalla.
Exchange: En RabbitMQ, los productores envían mensajes a un intercambio, no directamente a una cola.
Un intercambio enruta los mensajes a las colas según las reglas definidas por su tipo.
Los tipos de intercambios incluyen directo, tópico, cabeceras y fanout. El tutorial se centra en fanout, que transmite mensajes a todas las colas conocidas.
Ejemplo de declaración de un intercambio fanout:
channel.exchange_declare(exchange='logs', exchange_type='fanout')
Colas Temporales: Las colas temporales se crean con nombres generados aleatoriamente, y se eliminan automáticamente cuando se cierra la conexión del consumidor. Ejemplo de declaración de una cola temporal:
result = channel.queue_declare(queue='', exclusive=True)
Código de Ejemplo:
- emit_log.py para enviar mensajes de log.
- receive_logs.py para recibir mensajes de log.
Routing
En el tutorial anterior, creamos un sistema de registro simple que enviaba mensajes de log a múltiples receptores. En este tutorial, añadiremos la capacidad de suscribirse solo a un subconjunto de mensajes, permitiendo, por ejemplo, que solo los mensajes de error críticos se registren en un archivo, mientras que todos los mensajes de log se imprimen en la consola.

Enlaces
En ejemplos anteriores, ya creamos enlaces entre intercambios (exchanges) y colas (queues). Un enlace determina qué colas están interesadas en los mensajes de un intercambio. Los enlaces pueden incluir una clave de enrutamiento (routing key) que especifica qué mensajes de un intercambio deben ser enviados a una cola.
channel.queue_bind(exchange=exchange_name,
queue=queue_name,
routing_key='black')
La clave de enlace depende del tipo de intercambio. En un intercambio de tipo fanout, esta clave es ignorada.
Intercambio Directo
Anteriormente, usamos un intercambio de tipo fanout que transmitía todos los mensajes a todos los consumidores sin distinción. Ahora utilizaremos un intercambio direct que permite filtrar mensajes basándose en su severidad. Así, los mensajes serán enviados solo a las colas que coincidan exactamente con la clave de enrutamiento del mensaje.
Por ejemplo, si un intercambio tiene dos colas con claves de enlace orange y black, un mensaje con clave de enrutamiento orange solo irá a la cola correspondiente a orange.
Múltiples Enlaces
Es posible vincular varias colas con la misma clave de enlace. En este caso, el intercambio direct actúa como un fanout, enviando el mensaje a todas las colas que tengan una clave de enlace coincidente.
Emisión de Logs
Usaremos este modelo para nuestro sistema de logs. En lugar de fanout, enviaremos mensajes a un intercambio direct, usando la severidad del log como clave de enrutamiento.
Primero, debemos declarar un intercambio:
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
Y luego podemos enviar un mensaje:
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
Las severidades pueden ser 'info', 'warning' o 'error'.
Suscripción
Para recibir mensajes, crearemos un enlace para cada severidad de interés.
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
Código de Ejemplo
- emit_log_direct.py: Script para emitir mensajes de log.
- receive_logs_direct.py: Script para recibir mensajes de log.
Ejemplos de Uso
-
Para guardar solo los mensajes de
'warning'y'error'en un archivo:python receive_logs_direct.py warning error > logs_from_rabbit.log -
Para ver todos los mensajes de log en pantalla:
python receive_logs_direct.py info warning error -
Para emitir un mensaje de error:
python emit_log_direct.py error "Run. Run. Or it will explode."
Topics (Próximamente)
En el tutorial anterior, mejoramos nuestro sistema de registro utilizando un intercambio de tipo direct para recibir registros selectivamente, basado en criterios como la severidad del mensaje. Sin embargo, para mayor flexibilidad, podemos usar un intercambio de tipo topic, que permite el enrutamiento de mensajes basado en múltiples criterios.
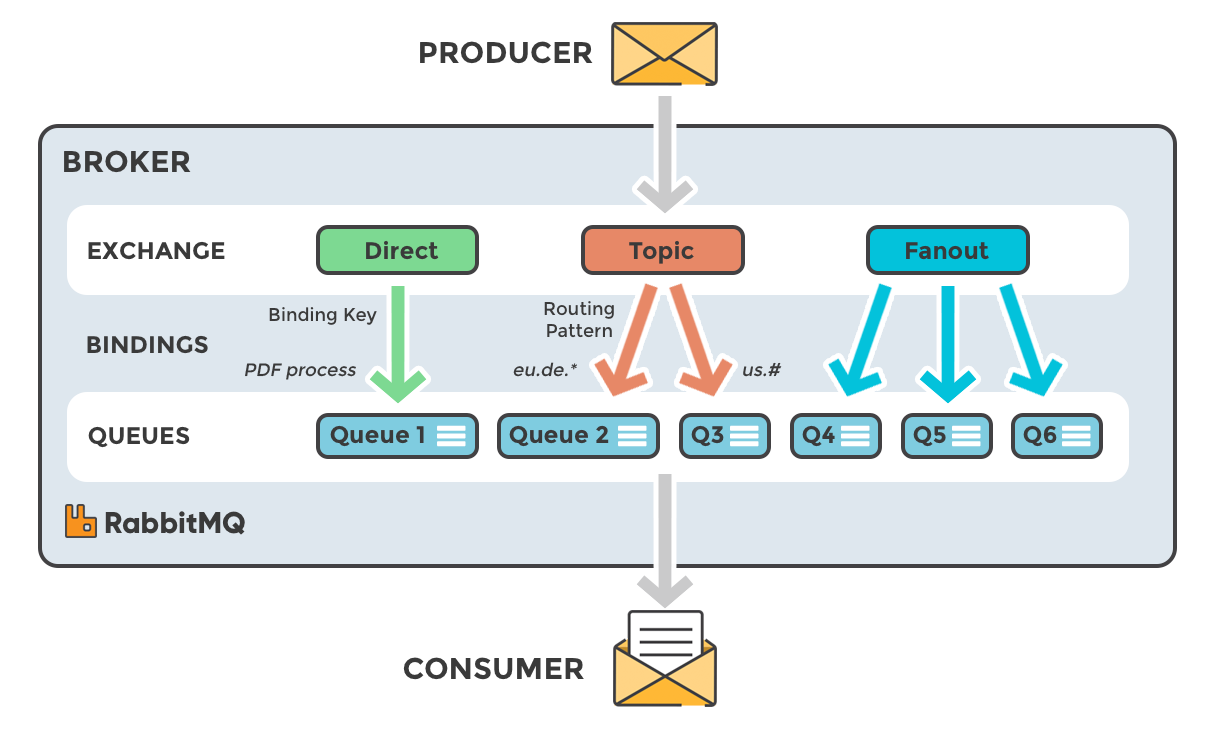
¿Qué es un intercambio de temas?
routing_key: En un intercambio de tipotopic, los mensajes tienen una clave de enrutamiento (routing_key) que es una lista de palabras separadas por puntos. Ejemplos:"quick.orange.rabbit","lazy.brown.fox".binding_key: Las claves de enlace (binding_key) también tienen el mismo formato y determinan qué mensajes recibe cada cola.
Casos especiales de binding_key
*(asterisco): Sustituye exactamente una palabra.#(almohadilla): Sustituye cero o más palabras.
Ejemplo de uso
Considera el siguiente escenario con dos colas (Q1 y Q2) y estas claves de enlace:
- Q1:
*.orange.*(recibe todos los mensajes sobre animales naranjas) - Q2:
*.*.rabbitylazy.#(recibe todos los mensajes sobre conejos y animales perezosos)
Ejemplos de mensajes:
"quick.orange.rabbit": Entregado a Q1 y Q2."lazy.orange.elephant": Entregado a Q1 y Q2."quick.orange.fox": Solo entregado a Q1."lazy.brown.fox": Solo entregado a Q2.
Mensajes con una o cuatro palabras, como "orange" o "quick.orange.new.rabbit", no coinciden con ningún enlace y se pierden.
Características del intercambio de temas
- Puede comportarse como un intercambio
fanoutsi se usa#comobinding_key(recibe todos los mensajes). - Se comporta como un intercambio
directsi no se utilizan*o#en las claves de enlace.
Implementación del sistema de registro
Usaremos un intercambio de temas para enrutar registros usando routing_key con el formato <facilidad>.<severidad>. El código para emitir y recibir registros es similar al de tutoriales anteriores.
Ejemplos de comandos:
- Recibir todos los registros:
python receive_logs_topic.py "#" - Recibir registros de "kern":
python receive_logs_topic.py "kern.*" - Recibir solo registros "critical":
python receive_logs_topic.py "*.critical" - Emitir un registro crítico de "kern":
python emit_log_topic.py "kern.critical" "A critical kernel error"
El código es casi el mismo que en el tutorial anterior.
RPC
En el segundo tutorial aprendimos a usar Work Queues para distribuir tareas que consumen tiempo entre múltiples trabajadores.
Pero, ¿qué pasa si necesitamos ejecutar una función en una computadora remota y esperar el resultado? Eso es una historia diferente. Este patrón es comúnmente conocido como Remote Procedure Call o RPC.
En este tutorial vamos a usar RabbitMQ para construir un sistema RPC: un cliente y un servidor RPC escalable. Como no tenemos tareas que consuman tiempo que valga la pena distribuir, vamos a crear un servicio RPC ficticio que devuelva números de Fibonacci.
Interfaz del cliente
Para ilustrar cómo se podría usar un servicio RPC, vamos a crear una clase de cliente simple. Va a exponer un método llamado call que envía una solicitud RPC y se bloquea hasta que se recibe la respuesta:
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print(f"fib(4) is {result}")
Una nota sobre RPC
Aunque RPC es un patrón bastante común en informática, a menudo se critica. Los problemas surgen cuando un programador no está al tanto de si una llamada a función es local o si es un RPC lento. Confusiones como esas resultan en un sistema impredecible y añaden una complejidad innecesaria a la depuración. En lugar de simplificar el software, el uso indebido de RPC puede resultar en un código enredado e inmantenible.
Teniendo esto en cuenta, considere los siguientes consejos:
- Asegúrese de que sea obvio qué llamada a función es local y cuál es remota.
- Documente su sistema. Haga claras las dependencias entre componentes.
- Maneje los casos de error. ¿Cómo debería reaccionar el cliente cuando el servidor RPC está caído por mucho tiempo?
En caso de duda, evite RPC. Si puede, debe usar un canal asincrónico: en lugar de un bloqueo estilo RPC, los resultados se envían asincrónicamente a la siguiente etapa de computación.
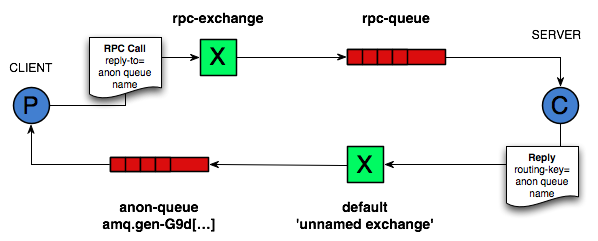
Cola de retorno (Callback queue)
En general, hacer RPC sobre RabbitMQ es fácil. Un cliente envía un mensaje de solicitud y un servidor responde con un mensaje de respuesta. Para recibir una respuesta, el cliente necesita enviar una dirección de una cola de retorno (callback queue) con la solicitud. Vamos a intentarlo:
result = channel.queue_declare(queue='', exclusive=True)
callback_queue = result.method.queue
channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = callback_queue,
),
body=request)
# ... y algo de código para leer un mensaje de respuesta de la callback_queue ...
Propiedades del mensaje
El protocolo AMQP 0-9-1 predefine un conjunto de 14 propiedades que acompañan un mensaje. La mayoría de las propiedades rara vez se utilizan, con la excepción de las siguientes:
delivery_mode: Marca un mensaje como persistente (con un valor de 2) o transitorio (cualquier otro valor). Puede recordar esta propiedad del segundo tutorial.content_type: Se utiliza para describir el tipo MIME de la codificación. Por ejemplo, para la codificación JSON a menudo utilizada, es una buena práctica establecer esta propiedad en:application/json.reply_to: Comúnmente utilizado para nombrar una cola de retorno (callback queue).correlation_id: Útil para correlacionar respuestas RPC con solicitudes.
ID de correlación (Correlation id)
En el método presentado anteriormente, sugerimos crear una cola de retorno para cada solicitud RPC. Eso es bastante ineficiente, pero afortunadamente hay una mejor manera: crear una única cola de retorno por cliente.
Eso plantea un nuevo problema: al recibir una respuesta en esa cola, no está claro a qué solicitud pertenece la respuesta. Es entonces cuando se usa la propiedad correlation_id. Vamos a configurarla a un valor único para cada solicitud. Más tarde, cuando recibamos un mensaje en la cola de retorno, miraremos esta propiedad, y con base en eso podremos coincidir una respuesta con una solicitud. Si vemos un valor de correlation_id desconocido, podemos descartar el mensaje de manera segura: no pertenece a nuestras solicitudes.
Puede preguntar, ¿por qué deberíamos ignorar los mensajes desconocidos en la cola de retorno en lugar de fallar con un error? Se debe a la posibilidad de una condición de carrera en el lado del servidor. Aunque es poco probable, es posible que el servidor RPC muera justo después de enviarnos la respuesta, pero antes de enviar un mensaje de confirmación para la solicitud. Si eso sucede, el servidor RPC reiniciado procesará la solicitud nuevamente. Es por eso que, en el cliente, debemos manejar las respuestas duplicadas de manera prudente, y el RPC idealmente debería ser idempotente.
Resumen
Nuestro RPC funcionará así:
- Cuando el cliente se inicia, crea una cola de retorno anónima exclusiva.
- Para una solicitud RPC, el cliente envía un mensaje con dos propiedades:
reply_to, que se establece en la cola de retorno, ycorrelation_id, que se establece en un valor único para cada solicitud. - La solicitud se envía a una cola llamada
rpc_queue. - El trabajador RPC (también conocido como servidor) está esperando solicitudes en esa cola. Cuando aparece una solicitud, hace el trabajo y envía un mensaje con el resultado de vuelta al cliente, usando la cola del campo
reply_to. - El cliente espera datos en la cola de retorno. Cuando aparece un mensaje, verifica la propiedad
correlation_id. Si coincide con el valor de la solicitud, devuelve la respuesta a la aplicación.
Poniéndolo todo junto
El código del servidor es bastante sencillo:
- Como de costumbre, comenzamos estableciendo la conexión y declarando la cola
rpc_queue. - Declaramos nuestra función de Fibonacci. Asume solo una entrada de entero positivo válida. (No espere que funcione para números grandes, probablemente sea la implementación recursiva más lenta posible).
- Declaramos un callback
on_requestparabasic_consume, el núcleo del servidor RPC. Se ejecuta cuando se recibe la solicitud. Hace el trabajo y envía la respuesta de vuelta. - Podríamos querer ejecutar más de un proceso de servidor. Para distribuir la carga de manera equitativa entre varios servidores, necesitamos establecer el ajuste
prefetch_count.
El código del cliente es un poco más complejo:
- Establecemos una conexión, un canal y declaramos una
callback_queueexclusiva para las respuestas. - Nos suscribimos a la
callback_queue, para que podamos recibir respuestas RPC. - El callback
on_responseque se ejecuta en cada respuesta está haciendo un trabajo muy simple: para cada mensaje de respuesta, verifica si elcorrelation_ides el que estamos buscando. Si es así, guarda la respuesta enself.responsey sale del bucle de consumo. - A continuación, definimos nuestro método principal
call: realiza la solicitud RPC real. - En el método
call, generamos un número decorrelation_idúnico y lo guardamos: la función de callbackon_responseusará este valor para capturar
la respuesta apropiada.
- También en el método
call, publicamos el mensaje de solicitud, con dos propiedades:reply_toycorrelation_id. - Al final, esperamos hasta que llegue la respuesta adecuada y devolvemos la respuesta al usuario.
Nuestro servicio RPC ya está listo. Podemos iniciar el servidor:
python rpc_server.py
Para solicitar un número de Fibonacci, ejecute el cliente con el número como argumento:
python rpc_client.py <numero>
El diseño presentado no es la única implementación posible de un servicio RPC, pero tiene algunas ventajas importantes:
- Si el servidor RPC es demasiado lento, puede escalar simplemente ejecutando otro. Intente ejecutar un segundo
rpc_server.pyen una nueva consola. - En el lado del cliente, el RPC requiere enviar y recibir solo un mensaje. No se requieren llamadas sincrónicas como
queue_declare. Como resultado, el cliente RPC necesita solo un viaje de ida y vuelta por la red para una única solicitud RPC.
Nuestro código sigue siendo bastante simplista y no intenta resolver problemas más complejos (pero importantes), como:
- ¿Cómo debería reaccionar el cliente si no hay servidores en funcionamiento?
- ¿Debería un cliente tener algún tipo de tiempo de espera para el RPC?
- Si el servidor funciona mal y genera una excepción, ¿debería enviarse al cliente?
- Proteger contra mensajes entrantes no válidos (por ejemplo, verificando límites) antes de procesar.