
ℹ️ This repo contains questions and exercises on various technical topics, sometimes related to DevOps and SRE :)
📊 There are currently 1571 questions
📚 To learn more about DevOps and SRE, check the resources in devops-resources repository
⚠️ You can use these for preparing for an interview but most of the questions and exercises don't represent an actual interview. Please read Q&A for more details
👥 Join our DevOps community where we have discussions and share resources on DevOps
📝 You can add more questions and exercises by submitting pull requests :) Read about contribution guidelines here





































DevOps
DevOps Exercises
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| Set up a CI pipeline | CI | Exercise |
DevOps Self Assessment
What is DevOps?
You can answer it by describing what DevOps means to you and/or rely on how companies define it. I've put here a couple of examples.
Amazon:
"DevOps is the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes. This speed enables organizations to better serve their customers and compete more effectively in the market."
Microsoft:
"DevOps is the union of people, process, and products to enable continuous delivery of value to our end users. The contraction of “Dev” and “Ops” refers to replacing siloed Development and Operations to create multidisciplinary teams that now work together with shared and efficient practices and tools. Essential DevOps practices include agile planning, continuous integration, continuous delivery, and monitoring of applications."
Red Hat:
"DevOps describes approaches to speeding up the processes by which an idea (like a new software feature, a request for enhancement, or a bug fix) goes from development to deployment in a production environment where it can provide value to the user. These approaches require that development teams and operations teams communicate frequently and approach their work with empathy for their teammates. Scalability and flexible provisioning are also necessary. With DevOps, those that need power the most, get it—through self service and automation. Developers, usually coding in a standard development environment, work closely with IT operations to speed software builds, tests, and releases—without sacrificing reliability."
Google:
"...The organizational and cultural movement that aims to increase software delivery velocity, improve service reliability, and build shared ownership among software stakeholders"
What are the benefits of DevOps? What can it help us to achieve?
- Collaboration
- Improved delivery
- Security
- Speed
- Scale
- Reliability
What are the anti-patterns of DevOps?
A couple of examples:
- One person is in charge of specific tasks. For example there is only one person who is allowed to merge the code of everyone else into the repository.
- Treating production differently from development environment. For example, not implementing security in development environment
- Not allowing someone to push to production on Friday ;)
How would you describe a successful DevOps engineer or a team?
The answer can focus on:
- Collaboration
- Communication
- Set up and improve workflows and processes (related to testing, delivery, ...)
- Dealing with issues
Things to think about:
- What DevOps teams or engineers should NOT focus on or do?
- Do DevOps teams or engineers have to be innovative or practice innovation as part of their role?
Tooling
What are you taking into consideration when choosing a tool/technology?
A few ideas to think about:
- mature/stable vs. cutting edge
- community size
- architecture aspects - agent vs. agentless, master vs. masterless, etc.
- learning curve
Can you describe which tool or platform you chose to use in some of the following areas and how?
- CI/CD
- Provisioning infrastructure
- Configuration Management
- Monitoring & alerting
- Logging
- Code review
- Code coverage
- Issue Tracking
- Containers and Containers Orchestration
- Tests
This is a more practical version of the previous question where you might be asked additional specific questions on the technology you chose
- CI/CD - Jenkins, Circle CI, Travis, Drone, Argo CD, Zuul
- Provisioning infrastructure - Terraform, CloudFormation
- Configuration Management - Ansible, Puppet, Chef
- Monitoring & alerting - Prometheus, Nagios
- Logging - Logstash, Graylog, Fluentd
- Code review - Gerrit, Review Board
- Code coverage - Cobertura, Clover, JaCoCo
- Issue tracking - Jira, Bugzilla
- Containers and Containers Orchestration - Docker, Podman, Kubernetes, Nomad
- Tests - Robot, Serenity, Gauge
A team member of yours, suggests to replace the current CI/CD platform used by the organization with a new one. How would you reply?
Things to think about:
- What we gain from doing so? Are there new features in the new platform? Does the new platform deals with some of the limitations presented in the current platform?
- What this suggestion is based on? In other words, did he/she tried out the new platform? Was there extensive technical research?
- What does the switch from one platform to another will require from the organization? For example, training users who use the platform? How much time the team has to invest in such move?
Version Control
What is Version Control?
- Version control is the sytem of tracking and managing changes to software code.
- It helps software teams to manage changes to source code over time.
- Version control also helps developers move faster and allows software teams to preserve efficiency and agility as the team scales to include more developers.
What is a commit?
- In Git, a commit is a snapshot of your repo at a specific point in time.
- The git commit command will save all staged changes, along with a brief description from the user, in a “commit” to the local repository.
What is a merge?
- Merging is Git's way of putting a forked history back together again. The git merge command lets you take the independent lines of development created by git branch and integrate them into a single branch.
What is a merge conflict?
- A merge conflict is an event that occurs when Git is unable to automatically resolve differences in code between two commits. When all the changes in the code occur on different lines or in different files, Git will successfully merge commits without your help.
What best practices are you familiar with regarding version control?
- Use a descriptive commit message
- Make each commit a logical unit
- Incorporate others' changes frequently
- Share your changes frequently
- Coordinate with your co-workers
- Don't commit generated files
CI/CD
What is Continuous Integration?
A development practice where developers integrate code into a shared repository frequently. It can range from a couple of changes every day or a week to a couple of changes in one hour in larger scales.
Each piece of code (change/patch) is verified, to make the change is safe to merge. Today, it's a common practice to test the change using an automated build that makes sure the code can integrated. It can be one build which runs several tests in different levels (unit, functional, etc.) or several separate builds that all or some has to pass in order for the change to be merged into the repository.
What is Continuous Deployment?
A development strategy used by developers to release software automatically into production where any code commit must pass through an automated testing phase. Only when this is successful is the release considered production worthy. This eliminates any human interaction and should be implemented only after production-ready pipelines have been set with real-time monitoring and reporting of deployed assets. If any issues are detected in production it should be easy to rollback to previous working state.
For more info please read here
Can you describe an example of a CI (and/or CD) process starting the moment a developer submitted a change/PR to a repository?
There are many answers for such a question, as CI processes vary, depending on the technologies used and the type of the project to where the change was submitted. Such processes can include one or more of the following stages:
- Compile
- Build
- Install
- Configure
- Update
- Test
An example of one possible answer:
A developer submitted a pull request to a project. The PR (pull request) triggered two jobs (or one combined job). One job for running lint test on the change and the second job for building a package which includes the submitted change, and running multiple api/scenario tests using that package. Once all tests passed and the change was approved by a maintainer/core, it's merged/pushed to the repository. If some of the tests failed, the change will not be allowed to merged/pushed to the repository.
A complete different answer or CI process, can describe how a developer pushes code to a repository, a workflow then triggered to build a container image and push it to the registry. Once in the registry, the k8s cluster is applied with the new changes.
What is Continuous Delivery?
A development strategy used to frequently deliver code to QA and Ops for testing. This entails having a staging area that has production like features where changes can only be accepted for production after a manual review. Because of this human entanglement there is usually a time lag between release and review making it slower and error prone as compared to continous deployment.
For more info please read here
What CI/CD best practices are you familiar with? Or what do you consider as CI/CD best practice?
- Automated process of building, testing and deploying software
- Commit and test often
- Testing/Staging environment should be a clone of production environment
You are given a pipeline and a pool with 3 workers: virtual machine, baremetal and a container. How will you decide on which one of them to run the pipeline?
Where do you store CI/CD pipelines? Why?
There are multiple approaches as to where to store the CI/CD pipeline definitions:
- App Repository - store them in the same repository of the application they are building or testing (perhaps the most popular one)
- Central Repository - store all organization's/project's CI/CD pipelines in one separate repository (perhaps the best approach when multiple teams test the same set of projects and they end up having many pipelines)
- CI repo for every app repo - you separate CI related code from app code but you don't put everything in one place (perhaps the worst option due to the maintenance)
Would you prefer a "configuration->deployment" model or "deployment->configuration"? Why?
Both have advantages and disadvantages. With "configuration->deployment" model for example, where you build one image to be used by multiple deployments, there is less chance of deployments being different from one another, so it has a clear advantage of a consistent environment.
Explain mutable vs. immutable infrastructure
In mutable infrastructure paradigm, changes are applied on top of the existing infrastructure and over time the infrastructure builds up a history of changes. Ansible, Puppet and Chef are examples of tools which follow mutable infrastructure paradigm.
In immutable infrastructure paradigm, every change is actually a new infrastructure. So a change to a server will result in a new server instead of updating it. Terraform is an example of technology which follows the immutable infrastructure paradigm.
Explain "Software Distribution"
Read this fantastic article on the topic.
From the article: "Thus, software distribution is about the mechanism and the community that takes the burden and decisions to build an assemblage of coherent software that can be shipped."
Why are there multiple software distributions? What differences can they have?
Different distributions can focus on different things like: focus on different environments (server vs. mobile vs. desktop), support specific hardware, specialize in different domains (security, multimedia, ...), etc. Basically, different aspects of the software and what it supports, get different priority in each distribution.
What is a Software Repository?
Wikipedia: "A software repository, or “repo” for short, is a storage location for software packages. Often a table of contents is stored, as well as metadata."
Read more here
What ways are there to distribute software? What are the advantages and disadvantages of each method?
- Source - Maintain build script within version control system so that user can build your app after cloning repository. Advantage: User can quickly checkout different versions of application. Disadvantage: requires build tools installed on users machine.
- Archive - collect all your app files into one archive (e.g. tar) and deliver it to the user. Advantage: User gets everything he needs in one file. Disadvantage: Requires repeating the same procedure when updating, not good if there are a lot of dependencies.
- Package - depends on the OS, you can use your OS package format (e.g. in RHEL/Fefodra it's RPM) to deliver your software with a way to install, uninstall and update it using the standard packager commands. Advantages: Package manager takes care of support for installation, uninstallation, updating and dependency management. Disadvantage: Requires managing package repository.
- Images - Either VM or container images where your package is included with everything it needs in order to run successfully. Advantage: everything is preinstalled, it has high degree of environment isolation. Disadvantage: Requires knowledge of building and optimizing images.
Are you familiar with "The Cathedral and the Bazaar models"? Explain each of the models
- Cathedral - source code released when software is released
- Bazaar - source code is always available publicly (e.g. Linux Kernel)
What is caching? How does it works? Why is it important?
Caching is fast access to frequently used resources which are computationally expensive or IO intensive and do not change often. There can be several layers of cache that can start from CPU caches to distributed cache systems. Common ones are in memory caching and distributed caching.
Caches are typically data structures that contains some data, such as a hashtable or dictionary. However, any data structure can provide caching capabilities, like set, sorted set, sorted dictionary etc. While, caching is used in many applications, they can create subtle bugs if not implemented correctly or used correctly. For example,cache invalidation, expiration or updating is usually quite challenging and hard.
Explain stateless vs. stateful
Stateless applications don't store any data in the host which makes it ideal for horizontal scaling and microservices. Stateful applications depend on the storage to save state and data, typically databases are stateful applications.
What is Reliability? How does it fit DevOps?
Reliability, when used in DevOps context, is the ability of a system to recover from infrastructure failure or disruption. Part of it is also being able to scale based on your organization or team demands.
What "Availability" means? What means are there to track Availability of a service?
Describe the workflow of setting up some type of web server (Apache, IIS, Tomcat, ...)
How a web server works?
Explain "Open Source"
Describe me the architecture of service/app/project/... you designed and/or implemented
What types of tests are you familiar with?
Styling, unit, functional, API, integration, smoke, scenario, ...
You should be able to explain those that you mention.
You need to install periodically a package (unless it's already exists) on different operating systems (Ubuntu, RHEL, ...). How would you do it?
There are multiple ways to answer this question (there is no right and wrong here):
- Simple cron job
- Pipeline with configuration management technology (such Puppet, Ansible, Chef, etc.) ...
What is Chaos Engineering?
Wikipedia: "Chaos engineering is the discipline of experimenting on a software system in production in order to build confidence in the system's capability to withstand turbulent and unexpected conditions"
Read about Chaos Engineering here
What is "infrastructure as code"? What implementation of IAC are you familiar with?
IAC (infrastructure as code) is a declerative approach of defining infrastructure or architecture of a system. Some implementations are ARM templates for Azure and Terraform that can work across multiple cloud providers.
How do you manage build artifacts?
Build artifacts are usually stored in a repository. They can be used in release pipelines for deployment purposes. Usually there is retention period on the build artifacts.
What Continuous Integration solution are you using/prefer and why?
What deployment strategies are you familiar with or have used?
There are several deployment strategies:
* Rolling
* Blue green deployment
* Canary releases
* Recreate strategy
You joined a team where everyone developing one project and the practice is to run tests locally on their workstation and push it to the repository if the tests passed. What is the problem with the process as it is now and how to improve it?
Explain test-driven development (TDD)
Explain agile software development
What do you think about the following sentence?: "implementing or practicing DevOps leads to more secure software"
Do you know what is a "post-mortem meeting"? What is your opinion on that?
How do you perform plan capacity for your CI/CD resources? (e.g. servers, storage, etc.)
How would you structure/implement CD for an application which depends on several other applications?
How do you measure your CI/CD quality? Are there any metrics or KPIs you are using for measuring the quality?
What is a configuration drift? What problems is it causing?
Configuration drift happens when in an environment of servers with the exact same configuration and software, a certain server or servers are being applied with updates or configuration which other servers don't get and over time these servers become slightly different than all others.
This situation might lead to bugs which hard to identify and reproduce.
How to deal with a configuration drift?
Configuration drift can be avoided with desired state configuration (DSC) implementation. Desired state configuration can be a declarative file that defined how a system should be. There are tools to enforce desired state such a terraform or azure dsc. There are incramental or complete strategies.
Explain Declarative and Procedural styles. The technologies you are familiar with (or using) are using procedural or declarative style?
Declarative - You write code that specifies the desired end state Procedural - You describe the steps to get to the desired end state
Declarative Tools - Terraform, Puppet, CloudFormation Procedural Tools - Ansible, Chef
To better emphasize the difference, consider creating two virtual instances/servers. In declarative style, you would specify two servers and the tool will figure out how to reach that state. In procedural style, you need to specify the steps to reach the end state of two instances/servers - for example, create a loop and in each iteration of the loop create one instance (running the loop twice of course).
Do you have experience with testing cross-projects changes? (aka cross-dependency)
Note: cross-dependency is when you have two or more changes to separate projects and you would like to test them in mutual build instead of testing each change separately.
Have you contributed to an open source project? Tell me about this experience
What is Distributed Tracing?
What is GitOps?
GitLab: "GitOps is an operational framework that takes DevOps best practices used for application development such as version control, collaboration, compliance, and CI/CD tooling, and applies them to infrastructure automation".
Read more here
SRE
What are the differences between SRE and DevOps?
Google: "One could view DevOps as a generalization of several core SRE principles to a wider range of organizations, management structures, and personnel."
Read more about it here
What SRE team is responsible for?
Google: "the SRE team is responsible for availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning of their services"
Read more about it here
What is an error budget?
Atlassian: "An error budget is the maximum amount of time that a technical system can fail without contractual consequences."
Read more about it here
What do you think about the following statement: "100% is the only right availability target for a system"
Wrong. No system can guarantee 100% availability as no system is safe from experiencing zero downtime. Many systems and services will fall somewhere between 99% and 100% uptime (or at least this is how most systems and services should be).
What are MTTF (mean time to failure) and MTTR (mean time to repair)? What these metrics help us to evaluate?
* MTTF (mean time to failure) other known as uptime, can be defined as how long the system runs before if fails.
* MTTR (mean time to recover) on the other hand, is the amount of time it takes to repair a broken system.
* MTBF (mean time between failures) is the amount of time between failures of the system.
What is the role of monitoring in SRE?
Google: "Monitoring is one of the primary means by which service owners keep track of a system’s health and availability"
Read more about it here
Jenkins
Jenkins Exercises
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| Remove Jobs | Scripts - Jobs | Exercise | Solution | |
| Remove Builds | Scripts - Builds | Exercise | Solution |
Jenkins Self Assessment
What is Jenkins? What have you used it for?
Jenkins is an open source automation tool written in Java with plugins built for Continuous Integration purpose. Jenkins is used to build and test your software projects continuously making it easier for developers to integrate changes to the project, and making it easier for users to obtain a fresh build. It also allows you to continuously deliver your software by integrating with a large number of testing and deployment technologies.
Jenkins integrates development life-cycle processes of all kinds, including build, document, test, package, stage, deploy, static analysis and much more.
What are the advantages of Jenkins over its competitors? Can you compare it to one of the following systems?
- Travis
- Bamboo
- Teamcity
- CircleCI
What are the limitations or disadvantages of Jenkins?
This might be considered to be an opinionated answer:
- Old fashioned dashboards with not many options to customize it
- Containers readiness (this has improved with Jenkins X)
- By itself, it doesn't have many features. On the other hand, there many plugins created by the community to expand its abilities
- Managing Jenkins and its piplines as a code can be one hell of a nightmare
Explain the following:
- Job
- Build
- Plugin
- Node or Worker
- Executor
What plugins have you used in Jenkins?
Have you used Jenkins for CI or CD processes? Can you describe them?
What type of jobs are there? Which types have you used?
How did you report build results to users? What ways are there to report the results?
You can report via:
- Emails
- Messaging apps
- Dashboards
Each has its own disadvantages and advantages. Emails for example, if sent too often, can be eventually disregarded or ignored.
You need to run unit tests every time a change submitted to a given project. Describe in details how your pipeline would look like and what will be executed in each stage
The pipelines will have multiple stages:
- Clone the project
- Install test dependencies (for example, if I need tox package to run the tests, I will install it in this stage)
- Run unit tests
- (Optional) report results (For example an email to the users)
- Archive the relevant logs/files
How to secure Jenkins?
Jenkins documentation provides some basic intro for securing your Jenkins server.
Describe how do you add new nodes (agents) to Jenkins
You can describe the UI way to add new nodes but better to explain how to do in a way that scales like a script or using dynamic source for nodes like one of the existing clouds.
How to acquire multiple nodes for one specific build?
Whenever a build fails, you would like to notify the team owning the job regarding the failure and provide failure reason. How would you do that?
There are four teams in your organization. How to prioritize the builds of each team? So the jobs of team x will always run before team y for example
If you are managing a dozen of jobs, you can probably use the Jenkins UI. But how do you manage the creation and deletion of hundreds of jobs every week/month?
What are some of Jenkins limitations?
- Testing cross-dependencies (changes from multiple projects together)
- Starting builds from any stage (although cloudbees implemented something called checkpoints)
How would you implement an option of a starting a build from a certain stage and not from the beginning?
Jenkins Dev
Do you have experience with developing a Jenkins plugin? Can you describe this experience?
Have you written Jenkins scripts? If yes, what for and how they work?
Cloud
What is Cloud Computing? What is a Cloud Provider?
Cloud computing refers to the delivery of on-demand computing services over the internet on a pay-as-you-go basis.
In simple words, Cloud computing is a service that lets you use any computing service such as a server, storage, networking, databases, and intelligence, right through your browser without owning anything. You can do anything you can think of unless it doesn’t require you to stay close to your hardware.
Cloud service providers are companies that establish public clouds, manage private clouds, or offer on-demand cloud computing components (also known as cloud computing services) like Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and Software-as-a-Service(SaaS). Cloud services can reduce business process costs when compared to on-premise IT.
What are the advantages of cloud computing? Mention at least 3 advantages
- Pay as you go (or consumption-based payment) - you are paying only for what you are using. No upfront payments and payment stops when resources are no longer used.
- Scalable - resources are scaled down or up based on demand
What types of Cloud Computing services are there?
IAAS - Infrastructure as a Service PAAS - Platform as a Service SAAS - Software as a Service
Explain each of the following and give an example:
- IAAS
- PAAS
- SAAS
What types of clouds (or cloud deployments) are there?
- Public
- Hybrid
- Private
Explain each of the following Cloud Computing Deployments:
- Public
- Private
- Hybrid
What are the differences between Cloud Providers and On-Premise solution?
In cloud providers, someone else owns and manages the hardware, hire the relevant infrastructure teams and pays for real-estate (for both hardware and people). You can focus on your business.
In On-Premise solution, it's quite the opposite. You need to take care of hardware, infrastructure teams and pay for everything which can be quite expensive. On the other hand it's tailored to your needs.
What is Serverless Computing?
The main idea behind serverless computing is that you don't need to manage the creation and configuration of server. All you need to focus on is splitting your app into multiple functions which will be triggered by some actions.
It's important to note that:
- Serverless Computing is still using servers. So saying there are no servers in serverless computing is completely wrong
- Serverless Computing allows you to have a different paying model. You basically pay only when your functions are running and not when the VM or containers are running as in other payment models
Can we replace any type of computing on servers with serverless?
Is there a difference between managed service to SaaS or is it the same thing?
AWS
AWS Global Infrastructure
Explain the following
- Availability zone
- Region
- Edge location
AWS regions are data centers hosted across different geographical locations worldwide.
Within each region, there are multiple isolated locations known as Availability Zones. Multiple availability zones ensure high availability in case one of them goes down.
Edge locations are basically content delivery network which caches data and insures lower latency and faster delivery to the users in any location. They are located in major cities in the world.
True or False? Each AWS region is designed to be completely isolated from the other AWS regions
True.
Do you agree with the statement "AWS region should be chosen based on proximity alone"?
Note: opinionated answer.
No. There are a couple of factors to consider when choosing a region (order doesn't mean anything):
- Cost - regions vary in cost and AWS Price List API can assist in calculating the difference in cost between the different regions.
- Speed
- Features
AWS IAM
What is IAM? What are some of its features?
Full explanation is here In short: it's used for managing users, groups, access policies & roles
True or False? IAM configuration is defined globally and not per region
True
Given an example of IAM best practices?
- Set up MFA
- Delete root account access keys
- Create IAM users instead of using root for daily management
What are Roles?
A way for allowing a service of AWS to use another service of AWS. You assign roles to AWS resources. For example, you can make use of a role which allows EC2 service to acesses s3 buckets (read and write).
What are Policies?
Policies documents used to give permissions as to what a user, group or role are able to do. Their format is JSON.
A user is unable to access an s3 bucket. What might be the problem?
There can be several reasons for that. One of them is lack of policy. To solve that, the admin has to attach the user with a policy what allows him to access the s3 bucket.
What should you use to:
- Grant access between two services/resources?
- Grant user access to resources/services?
- Role
- Policy
What permissions does a new user have?
Only a login access.
AWS Compute
What is EC2?
"a web service that provides secure, resizable compute capacity in the cloud". Read more here
What is AMI?
Amazon Machine Images is "An Amazon Machine Image (AMI) provides the information required to launch an instance". Read more here
What are the different source for AMIs?
- Personal AMIs - AMIs you create
- AWS Marketplace for AMIs - Paid AMIs usually with bundled with licensed software
- Community AMIs - Free
What is instance type?
"the instance type that you specify determines the hardware of the host computer used for your instance" Read more about instance types here
True or False? The following are instance types available for a user in AWS:
- Compute optimizied
- Network optimizied
- Web optimized
False. From the above list only compute optimized is available.
What is EBS?
"provides block level storage volumes for use with EC2 instances. EBS volumes behave like raw, unformatted block devices." More on EBS here
What EC2 pricing models are there?
On Demand - pay a fixed rate by the hour/second with no commitment. You can provision and terminate it at any given time. Reserved - you get capacity reservation, basically purchase an instance for a fixed time of period. The longer, the cheaper. Spot - Enables you to bid whatever price you want for instances or pay the spot price. Dedicated Hosts - physical EC2 server dedicated for your use.
What are Security Groups?
"A security group acts as a virtual firewall that controls the traffic for one or more instances" More on this subject here
How to migrate an instance to another availability zone?
What can you attach to an EC2 instance in order to store data?
EBS
What EC2 RI types are there?
Standard RI - most significant discount + suited for steady-state usage Convertible RI - discount + change attribute of RI + suited for steady-state usage Scheduled RI - launch within time windows you reserve
Learn more about EC2 RI here
AWS Serverless Compute
Explain what is AWS Lambda
AWS definition: "AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume."
Read more on it here
True or False? In AWS Lambda, you are charged as long as a function exists, regardless of whether it's running or not
False. Charges are being made when the code is executed.
Which of the following set of languages Lambda supports?
- R, Swift, Rust, Kotlin
- Python, Ruby, Go
- Python, Ruby, PHP
- Python, Ruby, Go
AWS Containers
What is Amazon ECS?
Amazon definition: "Amazon Elastic Container Service (Amazon ECS) is a fully managed container orchestration service. Customers such as Duolingo, Samsung, GE, and Cook Pad use ECS to run their most sensitive and mission critical applications because of its security, reliability, and scalability."
Learn more here
What is Amazon ECR?
Amazon definition: "Amazon Elastic Container Registry (ECR) is a fully-managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images."
Learn more here
What is AWS Fargate?
Amazon definition: "AWS Fargate is a serverless compute engine for containers that works with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS)."
Learn more here
AWS Storage
Explain what is AWS S3?
S3 stands for 3 S, Simple Storage Service. S3 is a object storage service which is fast, scalable and durable. S3 enables customers to upload, download or store any file or object that is up to 5 TB in size.
More on S3 here
What is a bucket?
An S3 bucket is a resource which is similar to folders in a file system and allows storing objects, which consist of data.
True or False? A bucket name must be globally unique
True
Explain folders and objects in regards to buckets
- Folder - any sub folder in an s3 bucket
- Object - The files which are stored in a bucket
Explain the following:
- Object Lifecycles
- Object Sharing
- Object Versioning
- Object Lifecycles - Transfer objects between storage classes based on defined rules of time periods
- Object Sharing - Share objects via a URL link
- Object Versioning - Manage multiple versions of an object
Explain Object Durability and Object Availability
Object Durability: The percent over a one-year time period that a file will not be lost Object Availability: The percent over a one-year time period that a file will be accessible
What is a storage class? What storage classes are there?
Each object has a storage class assigned to, affecting its availability and durability. This also has effect on costs. Storage classes offered today:
-
Standard:
- Used for general, all-purpose storage (mostly storage that needs to be accessed frequently)
- The most expensive storage class
- 11x9% durability
- 2x9% availability
- Default storage class
-
Standard-IA (Infrequent Access)
- Long lived, infrequently accessed data but must be available the moment it's being accessed
- 11x9% durability
- 99.90% availability
-
One Zone-IA (Infrequent Access):
- Long-lived, infrequently accessed, non-critical data
- Less expensive than Standard and Standard-IA storage classes
- 2x9% durability
- 99.50% availability
-
Intelligent-Tiering:
- Long-lived data with changing or unknown access patterns. Basically, In this class the data automatically moves to the class most suitable for you based on usage patterns
- Price depends on the used class
- 11x9% durability
- 99.90% availability
-
Glacier: Archive data with retrieval time ranging from minutes to hours
-
Glacier Deep Archive: Archive data that rarely, if ever, needs to be accessed with retrieval times in hours
-
Both Glacier and Glacier Deep Archive are:
- The most cheap storage classes
- have 9x9% durability
More on storage classes here
A customer would like to move data which is rarely accessed from standard storage class to the most cheapest class there is. Which storage class should be used?
- One Zone-IA
- Glacier Deep Archive
- Intelligent-Tiering
Glacier Deep Archive
What Glacier retrieval options are available for the user?
Expedited, Standard and Bulk
True or False? Each AWS account can store up to 500 PetaByte of data. Any additional storage will cost double
False. Unlimited capacity.
Explain what is Storage Gateway
"AWS Storage Gateway is a hybrid cloud storage service that gives you on-premises access to virtually unlimited cloud storage". More on Storage Gateway here
Explain the following Storage Gateway deployments types
- File Gateway
- Volume Gateway
- Tape Gateway
Explained in detail here
What is the difference between stored volumes and cached volumes?
Stored Volumes - Data is located at customer's data center and periodically backed up to AWS Cached Volumes - Data is stored in AWS cloud and cached at customer's data center for quick access
What is "Amazon S3 Transfer Acceleration"?
AWS definition: "Amazon S3 Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket"
Learn more here
Explain data consistency
Can you host dynamic websites on S3? What about static websites?
What security measures have you taken in context of S3?
What storage options are there for EC2 Instances?
What is Amazon EFS?
Amazon definition: "Amazon Elastic File System (Amazon EFS) provides a simple, scalable, fully managed elastic NFS file system for use with AWS Cloud services and on-premises resources."
Learn more here
What is AWS Snowmobile?
"AWS Snowmobile is an Exabyte-scale data transfer service used to move extremely large amounts of data to AWS."
Learn more here
AWS Disaster Recovery
In regards to disaster recovery, what is RTO and RPO?
RTO - The maximum acceptable length of time that your application can be offline.
RPO - The maximum acceptable length of time during which data might be lost from your application due to an incident.
What types of disaster recovery techniques AWS supports?
- The Cold Method - Periodically backups and sending the backups off-site
- Pilot Light - Data is mirrored to an environment which is always running
- Warm Standby - Running scaled down version of production environment
- Multi-site - Duplicated environment that is always running
Which disaster recovery option has the highest downtime and which has the lowest?
Lowest - Multi-site Highest - The cold method
AWS CloudFront
Explain what is CloudFront
AWS definition: "Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers data, videos, applications, and APIs to customers globally with low latency, high transfer speeds, all within a developer-friendly environment."
More on CloudFront here
Explain the following
- Origin
- Edge location
- Distribution
What delivery methods available for the user with CDN?
True or False?. Objects are cached for the life of TTL
True
What is AWS Snowball?
A transport solution which was designed for transferring large amounts of data (petabyte-scale) into and out the AWS cloud.
AWS ELB
What is ELB (Elastic Load Balancing)?
AWS definition: "Elastic Load Balancing automatically distributes incoming application traffic across multiple targets, such as Amazon EC2 instances, containers, IP addresses, and Lambda functions."
More on ELB here
What is auto scaling?
AWS definition: "AWS Auto Scaling monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost"
Read more about auto scaling here
True or False? Auto Scaling is about adding resources (such as instances) and not about removing resource
False. Auto scaling adjusts capacity and this can mean removing some resources based on usage and performances.
What types of load balancers are supported in EC2 and what are they used for?
- Application LB - layer 7 traffic
- Network LB - ultra-high performances or static IP address
- Classic LB - low costs, good for test or dev environments
AWS Security
What is the shared responsibility model? What AWS is responsible for and what the user is responsible for based on the shared responsibility model?
The shared responsibility model defines what the customer is responsible for and what AWS is responsible for.
More on the shared responsibility model here
True or False? Based on the shared responsibility model, Amazon is responsible for physical CPUs and security groups on instances
False. It is responsible for Hardware in its sites but not for security groups which created and managed by the users.
Explain "Shared Controls" in regards to the shared responsibility model
AWS definition: "apply to both the infrastructure layer and customer layers, but in completely separate contexts or perspectives. In a shared control, AWS provides the requirements for the infrastructure and the customer must provide their own control implementation within their use of AWS services"
Learn more about it here
What is the AWS compliance program?
What is AWS Artifact?
AWS definition: "AWS Artifact is your go-to, central resource for compliance-related information that matters to you. It provides on-demand access to AWS’ security and compliance reports and select online agreements."
Read more about it here
What is AWS Inspector?
AWS definition: "Amazon Inspector is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS. Amazon Inspector automatically assesses applications for exposure, vulnerabilities, and deviations from best practices.""
Learn more here
What is AWS Guarduty?
What is AWS Shield?
AWS definition: "AWS Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS."
What is AWS WAF? Give an example of how it can used and describe what resources or services you can use it with
What AWS VPN is used for?
What is the difference between Site-to-Site VPN and Client VPN?
What is AWS CloudHSM?
Amazon definition: "AWS CloudHSM is a cloud-based hardware security module (HSM) that enables you to easily generate and use your own encryption keys on the AWS Cloud."
Learn more here
True or False? AWS Inspector can perform both network and host assessments
True
What is AWS Key Management Service (KMS)?
AWS definition: "KMS makes it easy for you to create and manage cryptographic keys and control their use across a wide range of AWS services and in your applications." More on KMS here
What is AWS Acceptable Use Policy?
It describes prohibited uses of the web services offered by AWS. More on AWS Acceptable Use Policy here
True or False? A user is not allowed to perform penetration testing on any of the AWS services
False. On some services, like EC2, CloudFront and RDS, penetration testing is allowed.
True or False? DDoS attack is an example of allowed penetration testing activity
False.
True or False? AWS Access Key is a type of MFA device used for AWS resources protection
False. Security key is an example of an MFA device.
What is Amazon Cognito?
Amazon definition: "Amazon Cognito handles user authentication and authorization for your web and mobile apps."
Learn more here
What is AWS ACM?
Amazon definition: "AWS Certificate Manager is a service that lets you easily provision, manage, and deploy public and private Secure Sockets Layer/Transport Layer Security (SSL/TLS) certificates for use with AWS services and your internal connected resources."
Learn more here
AWS Databases
What is AWS RDS?
What is AWS DynamoDB?
Explain "Point-in-Time Recovery" feature in DynamoDB
Amazon definition: "You can create on-demand backups of your Amazon DynamoDB tables, or you can enable continuous backups using point-in-time recovery. For more information about on-demand backups, see On-Demand Backup and Restore for DynamoDB."
Learn more here
Explain "Global Tables" in DynamoDB
Amazon definition: "A global table is a collection of one or more replica tables, all owned by a single AWS account."
Learn more here
What is DynamoDB Accelerator?
Amazon definition: "Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds..."
Learn more here
What is AWS Redshift and how is it different than RDS?
cloud data warehouse
What do you if you suspect AWS Redshift performs slowly?
- You can confirm your suspicion by going to AWS Redshift console and see running queries graph. This should tell you if there are any long-running queries.
- If confirmed, you can query for running queries and cancel the irrelevant queries
- Check for connection leaks (query for running connections and include their IP)
- Check for table locks and kill irrelevant locking sessions
What is AWS ElastiCache? For what cases is it used?
Amazon Elasticache is a fully managed Redis or Memcached in-memory data store. It's great for use cases like two-tier web applications where the most frequently accesses data is stored in ElastiCache so response time is optimal.
What is Amazon Aurora
A MySQL & Postgresql based relational database. Also, the default database proposed for the user when using RDS for creating a database. Great for use cases like two-tier web applications that has a MySQL or Postgresql database layer and you need automated backups for your application.
What is Amazon DocumentDB?
Amazon definition: "Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data."
Learn more here
What "AWS Database Migration Service" is used for?
What type of storage is used by Amazon RDS?
EBS
Explain Amazon RDS Read Replicas
AWS definition: "Amazon RDS Read Replicas provide enhanced performance and durability for RDS database (DB) instances. They make it easy to elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads." Read more about here
AWS Networking
What is VPC?
"A logically isolated section of the AWS cloud where you can launch AWS resources in a virtual network that you define" Read more about it here.
True or False? VPC spans multiple regions
False
True or False? Subnets belong to the same VPC, can be in different availability zones
True. Just to clarify, a single subnet resides entirely in one AZ.
What is an Internet Gateway?
"component that allows communication between instances in your VPC and the internet" (AWS docs). Read more about it here
True or False? NACL allow or deny traffic on the subnet level
True
True or False? Multiple Internet Gateways can be attached to one VPC
False. Only one internet gateway can be attached to a single VPC.
What is an Elastic IP address?
An Elastic IP address is a reserved public IP address that you can assign to any EC2 instance in a particular region, until you choose to release it. When you associate an Elastic IP address with an EC2 instance, it replaces the default public IP address. If an external hostname was allocated to the instance from your launch settings, it will also replace this hostname; otherwise, it will create one for the instance. The Elastic IP address remains in place through events that normally cause the address to change, such as stopping or restarting the instance.
True or False? Route Tables used to allow or deny traffic from the internet to AWS instances
False.
Explain Security Groups and Network ACLs
- NACL - security layer on the subnet level.
- Security Group - security layer on the instance level.
What is AWS Direct Connect?
Allows you to connect your corporate network to AWS network.
AWS - Identify the service or tool
What would you use for automating code/software deployments?
AWS CodeDeploy
What would you use for easily creating similar AWS environments/resources for different customers?
CloudFormation
Using which service, can you add user sign-up, sign-in and access control to mobile and web apps?
Cognito
Which service would you use for building a website or web application?
Lightsail
Which tool would you use for choosing between Reserved instances or On-Demand instances?
Cost Explorer
What would you use to check how many unassociated Elastic IP address you have?
Trusted Advisor
Which service allows you to transfer large amounts (Petabytes) of data in and out of the AWS cloud?
AWS Snowball
Which service provides a virtual network dedicated to your AWS account?
VPC
What you would use for having automated backups for an application that has MySQL database layer?
Amazon Aurora
What would you use to migrate on-premise database to AWS?
AWS Database Migration Service (DMS)
What would you use to check why certain EC2 instances were terminated?
AWS CloudTrail
What would you use for SQL database?
AWS RDS
What would you use for NoSQL database?
AWS DynamoDB
What would you use for adding image and video analysis to your application?
AWS Rekognition
Which service would you use for debugging and improving performances issues with your applications?
AWS X-Ray
Which service is used for sending notifications?
SNS
What would you use for running SQL queries interactively on S3?
AWS Athena
Which service would you use for monitoring malicious activity and unauthorized behavior in regards to AWS accounts and workloads?
Amazon GuardDuty
Which service would you use for centrally manage billing, control access, compliance, and security across multiple AWS accounts?
AWS Organizations
Which service would you use for web application protection?
AWS WAF
You would like to monitor some of your resources in the different services. Which service would you use for that?
CloudWatch
Which service would you use for performing security assessment?
AWS Inspector
Which service would you use for creating DNS record?
Route 53
What would you use if you need a fully managed document database?
Amazon DocumentDB
Which service would you use to add access control (or sign-up, sign-in forms) to your web/mobile apps?
AWS Cognito
Which service would you use if you need messaging queue?
Simple Queue Service (SQS)
Which service would you use if you need managed DDOS protection?
AWS Shield
Which service would you use if you need store frequently used data for low latency access?
ElastiCache
What would you use to transfer files over long distances between a client and an S3 bucket?
Amazon S3 Transfer Acceleration
Which service would you use for distributing incoming requests across multiple?
Route 53
AWS DNS
What is Route 53?
"Amazon Route 53 is a highly available and scalable cloud Domain Name System (DNS) web service..." Some of Route 53 features:
- Register domain
- DNS service - domain name translations
- Health checks - verify your app is available
More on Route 53 here
AWS Monitoring & Logging
What is AWS CloudWatch?
AWS definition: "Amazon CloudWatch is a monitoring and observability service..."
More on CloudWatch here
What is AWS CloudTrail?
AWS definition: "AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account."
Read more on CloudTrail here
What is Simply Notification Service?
AWS definition: "a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications."
Read more about it here
Explain the following in regards to SNS:
- Topics
- Subscribers
- Publishers
- Topics - used for grouping multiple endpoints
- Subscribers - the endpoints where topics send messages to
- Publishers - the provider of the message (event, person, ...)
AWS Billing & Support
What is AWS Organizations?
AWS definition: "AWS Organizations helps you centrally govern your environment as you grow and scale your workloads on AWS." More on Organizations here
What are Service Control Policies and to what service they belong?
AWS organizations service and the definition by Amazon: "SCPs offer central control over the maximum available permissions for all accounts in your organization, allowing you to ensure your accounts stay within your organization’s access control guidelines."
Learn more here
Explain AWS pricing model
It mainly works on "pay-as-you-go" meaning you pay only for what are using and when you are using it. In s3 you pay for 1. How much data you are storing 2. Making requests (PUT, POST, ...) In EC2 it's based on the purchasing option (on-demand, spot, ...), instance type, AMI type and the region used.
More on AWS pricing model here
How one should estimate AWS costs when for example comparing to on-premise solutions?
- TCO calculator
- AWS simple calculator
- Cost Explorer
What basic support in AWS includes?
- 24x7 customer service
- Trusted Advisor
- AWS personal Health Dashoard
How are EC2 instances billed?
What AWS Pricing Calculator is used for?
What is Amazon Connect?
Amazon definition: "Amazon Connect is an easy to use omnichannel cloud contact center that helps companies provide superior customer service at a lower cost."
Learn more here
What are "APN Consulting Partners"?
Amazon definition: "APN Consulting Partners are professional services firms that help customers of all types and sizes design, architect, build, migrate, and manage their workloads and applications on AWS, accelerating their journey to the cloud."
Learn more here
Which of the following are AWS accounts types (and are sorted by order)?
- Basic, Developer, Business, Enterprise
- Newbie, Intermediate, Pro, Enterprise
- Developer, Basic, Business, Enterprise
- Beginner, Pro, Intermediate Enterprise
- Basic, Developer, Business, Enterprise
True or False? Region is a factor when it comes to EC2 costs/pricing
True. You pay differently based on the chosen region.
What is "AWS Infrastructure Event Management"?
AWS Definition: "AWS Infrastructure Event Management is a structured program available to Enterprise Support customers (and Business Support customers for an additional fee) that helps you plan for large-scale events such as product or application launches, infrastructure migrations, and marketing events."
AWS Automation
What is AWS CodeDeploy?
Amazon definition: "AWS CodeDeploy is a fully managed deployment service that automates software deployments to a variety of compute services such as Amazon EC2, AWS Fargate, AWS Lambda, and your on-premises servers."
Learn more here
Explain what is CloudFormation
AWS Misc
Which AWS service you have experience with that you think is not very common?
What is AWS CloudSearch?
What is AWS Lightsail?
AWS definition: "Lightsail is an easy-to-use cloud platform that offers you everything needed to build an application or website, plus a cost-effective, monthly plan."
What is AWS Rekognition?
AWS definition: "Amazon Rekognition makes it easy to add image and video analysis to your applications using proven, highly scalable, deep learning technology that requires no machine learning expertise to use."
Learn more here
What AWS Resource Groups used for?
Amazon definition: "You can use resource groups to organize your AWS resources. Resource groups make it easier to manage and automate tasks on large numbers of resources at one time. "
Learn more here
What is AWS Global Accelerator?
Amazon definition: "AWS Global Accelerator is a service that improves the availability and performance of your applications with local or global users..."
Learn more here
What is AWS Config?
Amazon definition: "AWS Config is a service that enables you to assess, audit, and evaluate the configurations of your AWS resources."
Learn more here
What is AWS X-Ray?
AWS definition: "AWS X-Ray helps developers analyze and debug production, distributed applications, such as those built using a microservices architecture." Learn more here
What is AWS OpsWorks?
Amazon definition: "AWS OpsWorks is a configuration management service that provides managed instances of Chef and Puppet."
Learn more about it here
What is AWS Athena?
"Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL."
Learn more about AWS Athena here
What is Amazon Cloud Directory?
Amazon definition: "Amazon Cloud Directory is a highly available multi-tenant directory-based store in AWS. These directories scale automatically to hundreds of millions of objects as needed for applications."
Learn more here
What is AWS Elastic Beanstalk?
AWS definition: "AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and services...You can simply upload your code and Elastic Beanstalk automatically handles the deployment"
Learn more about it here
What is AWS SWF?
Amazon definition: "Amazon SWF helps developers build, run, and scale background jobs that have parallel or sequential steps. You can think of Amazon SWF as a fully-managed state tracker and task coordinator in the Cloud."
Learn more on Amazon Simple Workflow Service here
What is AWS EMR?
AWS definition: "big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto."
Learn more here
What is AWS Quick Starts?
AWS definition: "Quick Starts are built by AWS solutions architects and partners to help you deploy popular technologies on AWS, based on AWS best practices for security and high availability."
Read more here
What is the Trusted Advisor?
What is AWS Service Catalog?
Amazon definition: "AWS Service Catalog allows organizations to create and manage catalogs of IT services that are approved for use on AWS."
Learn more here
What is AWS CAF?
Amazon definition: "AWS Professional Services created the AWS Cloud Adoption Framework (AWS CAF) to help organizations design and travel an accelerated path to successful cloud adoption. "
Learn more here
What is AWS Cloud9?
AWS definition: "AWS Cloud9 is a cloud-based integrated development environment (IDE) that lets you write, run, and debug your code with just a browser"
What is AWS Application Discovery Service?
Amazon definition: "AWS Application Discovery Service helps enterprise customers plan migration projects by gathering information about their on-premises data centers."
Learn more here
What is the AWS well-architected framework and what pillars it's based on?
AWS definition: "The Well-Architected Framework has been developed to help cloud architects build secure, high-performing, resilient, and efficient infrastructure for their applications. Based on five pillars — operational excellence, security, reliability, performance efficiency, and cost optimization"
Learn more here
What AWS services are serverless (or have the option to be serverless)?
AWS Lambda AWS Athena
What is Simple Queue Service (SQS)?
AWS definition: "Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications".
Learn more about it here
Network
What is Ethernet?
Ethernet simply refers to the most common type of Local Area Network (LAN) used today. A LAN—in contrast to a WAN (Wide Area Network), which spans a larger geographical area—is a connected network of computers in a small area, like your office, college campus, or even home.
What is TCP/IP?
A set of protocols that define how two or more devices can communicate with each other. To learn more about TCP/IP, read here
What is a MAC address? What is it used for?
A MAC address is a unique identification number or code used to identify individual devices on the network.
Packets that are sent on the ethernet are always coming from a MAC address and sent to a MAC address. If a network adapter is receiving a packet, it is comparing the packet’s destination MAC address to the adapter’s own MAC address.
When is this MAC address used?: ff:ff:ff:ff:ff:ff
When a device sends a packet to the broadcast MAC address (FF:FF:FF:FF:FF:FF), it is delivered to all stations on the local network. It needs to be used in order for all devices to receive your packet at the datalink layer.
What is an IP address?
An Internet Protocol address (IP address) is a numerical label assigned to each device connected to a computer network that uses the Internet Protocol for communication.An IP address serves two main functions: host or network interface identification and location addressing.
Explain subnet mask and given an example
A Subnet mask is a 32-bit number that masks an IP address, and divides the IP address into network address and host address. Subnet Mask is made by setting network bits to all "1"s and setting host bits to all "0"s. Within a given network, two host addresses are reserved for special purpose, and cannot be assigned to hosts. The "0" address is assigned a network address and "255" is assigned to a broadcast address, and they cannot be assigned to hosts.
For Example
| Address Class | No of Network Bits | No of Host Bits | Subnet mask | CIDR notation |
| ------------- | ------------------ | --------------- | --------------- | ------------- |
| A | 8 | 24 | 255.0.0.0 | /8 |
| A | 9 | 23 | 255.128.0.0 | /9 |
| A | 12 | 20 | 255.240.0.0 | /12 |
| A | 14 | 18 | 255.252.0.0 | /14 |
| B | 16 | 16 | 255.255.0.0 | /16 |
| B | 17 | 15 | 255.255.128.0 | /17 |
| B | 20 | 12 | 255.255.240.0 | /20 |
| B | 22 | 10 | 255.255.252.0 | /22 |
| C | 24 | 8 | 255.255.255.0 | /24 |
| C | 25 | 7 | 255.255.255.128 | /25 |
| C | 28 | 4 | 255.255.255.240 | /28 |
| C | 30 | 2 | 255.255.255.252 | /30 |
What is a private IP address? In which scenarios/system designs, one should use it?
What is a public IP address? In which scenarios/system designs, one should use it?
Explain the OSI model. What layers there are? What each layer is responsible for?
- Application: user end (HTTP is here)
- Presentation: establishes context between application-layer entities (Encryption is here)
- Session: establishes, manages and terminates the connections
- Transport: transfers variable-length data sequences from a source to a destination host (TCP & UDP are here)
- Network: transfers datagrams from one network to another (IP is here)
- Data link: provides a link between two directly connected nodes (MAC is here)
- Physical: the electrical and physical spec the data connection (Bits are here)
You can read more about the OSI model in penguintutor.com
For each of the following determine to which OSI layer it belongs:
- Error correction
- Packets routing
- Cables and electrical signals
- MAC address
- IP address
- Terminate connections
- 3 way handshake
What delivery schemes are you familiar with?
Unitcast: One to one communication where there is one sender and one receiver.
Broadcast: Sending a message to everyone in the network. The address ff:ff:ff:ff:ff:ff is used for broadcasting. Two common protocols which use broadcast are ARP and DHCP.
Multicast: Sending a message to a group of subscribers. It can be one-to-many or many-to-many.
What is CSMA/CD? Is it used in modern ethernet networks?
CSMA/CD stands for Carrier Sense Multiple Access / Collision Detection. Its primarily focus it to manage access to shared medium/bus where only one host can transmit at a given point of time.
CSMA/CD algorithm:
- Before sending a frame, it checks whether another host already transmitting a frame.
- If no one transmitting, it starts transmitting the frame.
- If two hosts transmitted at the same time, we have a collision.
- Both hosts stop sending the frame and they send to everyone a 'jam signal' notifying everyone that a collision occurred
- They are waiting for a random time before sending again
- Once each host waited for a random time, they try to send the frame again and so the
Describe the following network devices and the difference between them:
- router
- switch
- hub
How does a router works?
A router is a physical or virtual appliance that passes information between two or more packet-switched computer networks. A router inspects a given data packet's destination Internet Protocol address (IP address), calculates the best way for it to reach its destination and then forwards it accordingly.
What is NAT?
Network Address Translation (NAT) is a process in which one or more local IP address is translated into one or more Global IP address and vice versa in order to provide Internet access to the local hosts.
What is a proxy? How does it works? What do we need it for?
A proxy server acts as a gateway between you and the internet. It’s an intermediary server separating end users from the websites they browse.
If you’re using a proxy server, internet traffic flows through the proxy server on its way to the address you requested. The request then comes back through that same proxy server (there are exceptions to this rule), and then the proxy server forwards the data received from the website to you.
roxy servers provide varying levels of functionality, security, and privacy depending on your use case, needs, or company policy.
What is TCP? How does it works? What is the 3 way handshake?
TCP 3-way handshake or three-way handshake is a process which is used in a TCP/IP network to make a connection between server and client.
A three-way handshake is primarily used to create a TCP socket connection. It works when:
- A client node sends a SYN data packet over an IP network to a server on the same or an external network. The objective of this packet is to ask/infer if the server is open for new connections.
- The target server must have open ports that can accept and initiate new connections. When the server receives the SYN packet from the client node, it responds and returns a confirmation receipt – the ACK packet or SYN/ACK packet.
- The client node receives the SYN/ACK from the server and responds with an ACK packet.
What is round-trip delay or round-trip time?
From wikipedia: "the length of time it takes for a signal to be sent plus the length of time it takes for an acknowledgement of that signal to be received"
Bonus question: what is the RTT of LAN?
How does SSL handshake work?
What is the difference between TCP and UDP?
TCP establishes a connection between the client and the server to guarantee the order of the packages, on the other hand, UDP does not establish a connection between client and server and doesn't handle package order. This makes UDP more lightweight than TCP and a perfect candidate for services like streaming.
Penguintutor.com provides a good explanation.
What TCP/IP protocols are you familiar with?
Explain "default gateway"
A default gateway serves as an access point or IP router that a networked computer uses to send information to a computer in another network or the internet.
What is ARP? How does it works?
ARP stands for Address Resolution Protocol. When you try to ping an IP address on your local network, say 192.168.1.1, your system has to turn the IP address 192.168.1.1 into a MAC address. This involves using ARP to resolve the address, hence its name.
Systems keep an ARP look-up table where they store information about what IP addresses are associated with what MAC addresses. When trying to send a packet to an IP address, the system will first consult this table to see if it already knows the MAC address. If there is a value cached, ARP is not used.
What is TTL? What does it helps to prevent?
What is DHCP? How does it works?
It stands for Dynamic Host Configuration Protocol, and allocates IP addresses, subnet masks and gateways to hosts. This is how it works:
- A host upon entering a network, broadcasts a message in search of a DHCP server (DHCP DISCOVER)
- An offer message is sent back by the DHCP server as a packet containing lease time, subnet mask, IP addresses, etc (DHCP OFFER)
- Depending on which offer accepted, the client sends back a reply broadcast letting all DHCP servers know (DHCP REQUEST)
- Server sends an acknowledgment (DHCP ACK)
Read more here
What is SSL tunneling? How does it works?
What is a socket? Where can you see the list of sockets in your system?
What is IPv6? Why should we consider using it if we have IPv4?
What is VLAN?
What is MTU?
What happens if you send a packet that is bigger than the MTU?
True or False?. Ping is using UDP because it doesn't care about reliable connection
What is SDN?
What is ICMP? What is it used for?
What is NAT? How does it work?
NAT stands for network address translation. It’s a way to map multiple local private addresses to a public one before transferring the information. Organizations that want multiple devices to employ a single IP address use NAT, as do most home routers. For example, your computer's private IP could be 192.168.1.100, but your router maps the traffic to it's public IP (e.g. 1.1.1.1). Any device on the internet would see the traffic coming from your public IP (1.1.1.1) instead of your private IP (192.168.1.100).
Which factors affect network performances
What the terms "Data Plane" and "Control Plane" refer?
The exact meaning is usually depends on the context but overall data plane refers to all the functions that forward packets and/or frames from one interface to another while control plane refers to all the functions that make use of routing protocols.
There is also "Management Plane" which refers to monitoring and management functions.
Explain Spanning Tree Protocol (STP)
What is link aggregation? Why is it used?
What is Asymmetric Routing? How do deal with it?
What overlay (tunnel) protocols are you familiar with?
What is GRE? How does it works?
What is VXLAN? How does it works?
What is SNAT?
Explain OSPF
What is latency?
What is bandwidth?
What is throughput?
When performing a search query, what is more important, latency or throughput? And how to assure that what managing global infrastructure?
Latency. To have a good latency, a search query should be forwarded to the closest datacenter.
When uploading a video, what is more important, latency or throughput? And how to assure that?
Throughput. To have a good throughput, the upload stream should be routed to an underutilized link.
What other considerations (except latency and throughput) are there when forwarding requests?
- Keep caches updated (which means the request could be forwarded not to the closest datacenter)
Explain Spine & Leaf
What is Network Congestion? What can cause it?
What can you tell me about UDP packet format? What about TCP packet format? How is it different?
What is the exponential backoff algorithm? Where is it used?
Using Hamming code, what would be the code word for the following data word 100111010001101?
00110011110100011101
Give examples of protocols found in the application layer
- Hypertext Transfer Protocol (HTTP) - used for the webpages on the internet
- Simple Mail Transfer Protocol (SMTP) - email transmission
- Telecommunications Network - (TELNET) - terminal emulation to allow client access to telnet server
- File Transfer Protocol (FTP) - facilitates transfer of files between any two machines
- Domain Name System (DNS) - domain name translation
- Dynamic Host Configuration Protocol (DHCP) - allocates IP addresses, subnet masks and gateways to hosts
- Simple Network Management Protocol (SNMP) - gathers data of devices on the network
Give examples of protocols found in the network Layer
- Internet Protocol (IP) - assists in routing packets from one machine to another
- Internet Control Message Protocol (ICMP) - lets one know what is going such as error messages and debugging information
What is HSTS?
HTTP Strict Transport Security is a web server directive that informs user agents and web browsers how to handle its connection through a response header sent at the very beginning and back to the browser. This forces connections over HTTPS encryption, disregarding any script's call to load any resource in that domain over HTTP.
What is the difference if any between SSL and TLS?
Linux
Linux Master Application
A completely free application for testing your knowledge on Linux

Linux Self Assessment
What is your experience with Linux?
Only you know :)
For example:
- Administration
- Troubleshooting & Debugging
- Storage
- Networking
- Development
- Deployments
Explain what each of the following commands does and give an example on how to use it:
- touch
- ls
- rm
- cat
- cp
- mkdir
Some of the commands in the previous question can be run with the -r/--recursive flag. What does it do?
Explain each field in the output of `ls -l` command
It shows a detailed list of files in a long format. From the left:
- file permissions, number of links, owner name, owner group, file size, timestamp of last modification and directory/file name
What are hidden files/directories? How to list them?
These are files directly not displayed after performing a standard ls direct listing. An example of these files are .bashrc which are used to execute some scripts. Some also store configuration about services on your host like .KUBECONFIG. The command used to list them is,
ls -a
What do > and < do in terms of input and output for programs?
They take in input (<) and output for a given file (>) using stdin and stdout.
myProgram < input.txt > executionOutput.txt
Explain what each of the following commands does and give an example on how to use it:
- sed
- grep
- cut
- awk
What each of the following commands does?
- pwd
- cd
- find
- ls
What each of the following commands does?
- cd /
- cd ~
- cd
- cd ..
- cd .
- cd -
- cd / -> change to the root directory
- cd ~ -> change to your home directory
- cd -> change to your home directory
- cd .. -> change to the directory above your current i.e parent directory
- cd . -> change to the directory you currently in
- cd - -> change to the last visited path
How to rename the name of a file or a directory?
Using the mv command.
Specify which command would you use (and how) for each of the following scenarios
- Remove a directory with files
- Display the content of a file
- Provides access to the file /tmp/x for everyone
- Change working directory to user home directory
- Replace every occurrence of the word "good" with "great" in the file /tmp/y
How can you check what is the path of a certain command?
- whereis
- which
Explain redirection
Explain piping. How do you perform piping?
Using a pipe in Linux, allows you to send the output of one to another (also called redirection). For example: cat /etc/services | wc -l
Fix the following commands:
- sed "s/1/2/g' /tmp/myFile
- find . -iname *.yaml -exec sed -i "s/1/2/g" {} ;
sed 's/1/2/g' /tmp/myFile find . -iname "*.yaml" -exec sed -i "s/1/2/g" {} \;
Linux FHS
In Linux FHS (Filesystem Hierarchy Standard) what is the /?
What is stored in each of the following paths?
- /bin, /sbin, /usr/bin and /usr/sbin
- /etc
- /home
- /var
- /tmp
What is special about the /tmp directory when compared to other directories?
/tmp folder get cleaned automatically, usually upon reboot.
What kind of information one can find in /proc?
Can you create files in /proc?
In which path can you find the system devices (e.g. block storage)?
Running the command df you get "command not found". What could be wrong and how to fix it?
Most likely the default/generated $PATH was somehow modified or overridden thus not containing /bin/ where df would normally go.
This issue could also happen if bash_profile or any configuration file of your interpreter was wrongly modified, causing erratics behaviours.
You would solve this by fixing your $PATH variable:
As to fix it there are several options:
- Manually adding what you need to your $PATH
PATH="$PATH":/user/bin:/..etc - You have your weird env variables backed up.
- You would look for your distro default $PATH variable, copy paste using method #1
Note: There are many ways of getting errors like this: if bash_profile or any configuration file of your interpreter was wrongly modified; causing erratics behaviours, permissions issues, bad compiled software (if you compiled it by yourself)... there is no answer that will be true 100% of the time.
How do you schedule tasks periodically?
You can use the commands cron and at.
With cron, tasks are scheduled using the following format:
*/30 * * * * bash myscript.sh Executes the script every 30 minutes.
The tasks are stored in a cron file, you can write in it using crontab -e
Alternatively if you are using a distro with systemd it's recommended to use systemd timers.
How to check which commands you executed in the past?
history command or .bash_history file
Linux Permissions
How to change the permissions of a file?
Using the chmod command.
What does the following permissions mean?:
- 777
- 644
- 750
777 - You give the owner, group and other: Execute (1), Write (2) and Read (4); 4+2+1 = 7. 644 - Owner has Read (4), Write (2), 4+2 = 6; Group and Other have Read (4). 750 - Owner has x+r+w, Group has Read (4) and Execute (1); 4+1 = 5. Other have no permissions.
What this command does? chmod +x some_file
It adds execute permissions to all sets i.e user, group and others
Explain what is setgid and setuid
- setuid is a linux file permission that permits a user to run a file or program with the permissions of the owner of that file. This is possible by elevation of current user privileges.
- setgid is a process when executed will run as the group that owns the file.
What is the purpose of sticky bit?
Its a bit that only allows the owner or the root user to delete or modify the file.
What the following commands do?
- chmod
- chown
- chgrp
- chmod - changes access permissions to files system objects
- chown - changes the owner of file system files and directories
- chgrp - changes the group associated with a file system object
What is sudo? How do you set it up?
True or False? In order to install packages on the system one must be the root user or use the sudo command
True
Explain what are ACLs. For what use cases would you recommend to use them?
You try to create a file but it fails. Name at least three different reason as to why it could happen
- No more disk space
- No more inodes
- No permissions
Linux Shell Scripting
What this line in scripts mean?: #!/bin/bash
#!/bin/bash is She-bang
/bin/bash is the most common shell used as default shell for user login of the linux system. The shell’s name is an acronym for Bourne-again shell. Bash can execute the vast majority of scripts and thus is widely used because it has more features, is well developed and better syntax.
True or False?: when a certain command/line fails, the script, by default, will exit and will no keep running
Depends on the language and settings used. When a script written in Bash fails to run a certain command it will keep running and will execute all other commands mentioned after the command which failed. Most of the time we would actually want the opposite to happen. In order to make Bash exist when a specific command fails, use 'set -e' in your script.
Explain what would be the result of each command:
echo $0echo $?echo $$echo $@echo $#
echo $0echo $?echo $$echo $@echo $#How do you debug shell scripts?
Answer depends on the language you are using for writing your scripts. If Bash is used for example then:
- Adding -x to the script I'm running in Bash
- Old good way of adding echo statements
If Python, then using pdb is very useful.
How do you get input from the user in shell scripts?
Using the keyword read so for example read x will wait for user input and will store it in the variable x.
Explain continue and break. When do you use them if at all?
Running the following bash script, we don't get 2 as a result, why?
x = 2
echo $x
x = 2
echo $x
Should be x=2
How to store the output of a command in a variable?
How do you check variable length?
Explain the following code:
:(){ :|:& };:
:(){ :|:& };:Can you give an example to some Bash best practices?
What is the ternary operator? How do you use it in bash?
A short way of using if/else. An example:
What does the following code do and when would you use it?
diff <(ls /tmp) <(ls /var/tmp)
diff <(ls /tmp) <(ls /var/tmp)It is called 'process substitution'. It provides a way to pass the output of a command to another command when using a pipe
| is not possible. It can be used when a command does not support STDIN or you need the output of multiple commands.
https://superuser.com/a/1060002/167769
Linux systemd
What is systemd?
Systemd is a daemon (System 'd', d stands from daemon).
A daemon is a program that runs in the background without direct control of the user, although the user can at any time talk to the daemon.
systemd has many features such as user processes control/tracking, snapshot support, inhibitor locks..
If we visualize the unix/linux system in layers, systemd would fall directly after the linux kernel.
Hardware -> Kernel -> Daemons, System Libraries, Server Display.
On a system which uses systemd, how would you display the logs?
journalctl
Describe how to make a certain process/app a service
Linux Debugging
Where system logs are located?
/var/log
How to follow file's content as it being appended without opening the file every time?
tail -f <file_name>
What are you using for troubleshooting and debugging network issues?
dstat -t is great for identifying network and disk issues.
netstat -tnlaup can be used to see which processes are running on which ports.
lsof -i -P can be used for the same purpose as netstat.
ngrep -d any metafilter for matching regex against payloads of packets.
tcpdump for capturing packets
wireshark same concept as tcpdump but with GUI (optional).
What are you using for troubleshooting and debugging disk & file system issues?
dstat -t is great for identifying network and disk issues.
opensnoop can be used to see which files are being opened on the system (in real time).
What are you using for troubleshooting and debugging process issues?
strace is great for understanding what your program does. It prints every system call your program executed.
What are you using for debugging CPU related issues?
top will show you how much CPU percentage each process consumes
perf is a great choice for sampling profiler and in general, figuring out what your CPU cycles are "wasted" on
flamegraphs is great for CPU consumption visualization (http://www.brendangregg.com/flamegraphs.html)
You get a call from someone claiming "my system is SLOW". What do you do?
- Check with
topfor anything unusual - Run
dstat -tto check if it's related to disk or network. - Check if it's network related with
sar - Check I/O stats with
iostat
Explain iostat output
How to debug binaries?
What is the difference between CPU load and utilization?
How you measure time execution of a program?
Linux Kernel
What is a kernel, and what does it do?
The kernel is part of the operating system and is responsible for tasks like:
- Allocating memory
- Schedule processes
- Control CPU
How do you find out which Kernel version your system is using?
uname -a command
What is a Linux kernel module and how do you load a new module?
Explain user space vs. kernel space
The operating system executes the kernel in protected memory to prevent anyone from changing (and risking it crashing). This is what is known as "Kernel space". "User space" is where users executes their commands or applications. It's important to create this separation since we can't rely on user applications to not tamper with the kernel, causing it to crash.
Applications can access system resources and indirectly the kernel space by making what is called "system calls".
What are system calls? What system calls are you familiar with?
Linux Virtualization
What virtualization solutions are available for Linux?
What is KVM?
Linux SSH
What is SSH? How to check if a Linux server is running SSH?
Wikipedia Definition: "SSH or Secure Shell is a cryptographic network protocol for operating network services securely over an unsecured network."
Hostinger.com Definition: "SSH, or Secure Shell, is a remote administration protocol that allows users to control and modify their remote servers over the Internet."
An SSH server will have SSH daemon running. Depends on the distribution, you should be able to check whether the service is running (e.g. systemctl status sshd).
Why SSH is considered better than telnet?
Telnet also allows you to connect to a remote host but as opposed to SSH where the communication is encrypted, in telnet, the data is sent in clear text, so it doesn't considered to be secured because anyone on the network can see what exactly is sent, including passwords.
What is stored in ~/.ssh/known_hosts?
You try to ssh to a server and you get "Host key verification failed". What does it mean?
It means that the key of the remote host was changed and doesn't match the one that stored on the machine (in ~/.ssh/known_hosts).
What is the difference between SSH and SSL?
What ssh-keygen is used for?
What is SSH port forwarding?
Linux - Globbing, Wildcards
What is Globbing?
What are wildcards? Can you give an example of how to use them?
Explain what will ls [XYZ] match
Explain what will ls [^XYZ] match
Explain what will ls [0-5] match
What each of the following matches
- ?
- *
- The ? matches any single character
- The * matches zero or more characters
What do we grep for in each of the following commands?:
grep '[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}' some_filegrep -E "error|failure" some_filegrep '[0-9]$' some_file
grep '[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}' some_filegrep -E "error|failure" some_filegrep '[0-9]$' some_file- An IP address
- The word "error" or "failure"
- Lines which end with a number
Which line numbers will be printed when running `grep '\baaa\b'` on the following content:
aaa
bbb
ccc.aaa
aaaaaa
lines 1 and 3.
What is the difference single and double quotes?
What is escaping? What escape character is used for escaping?
What is an exit code? What exit codes are you familiar with?
An exit code (or return code) represents the code returned by a child process to its parent process.
0 is an exit code which represents success while anything higher than 1 represents error. Each number has different meaning, based on how the application was developed.
I consider this as a good blog post to read more about it: https://shapeshed.com/unix-exit-codes
Linux Boot Process
Tell me everything you know about the Linux boot process
Another way to ask this: what happens from the moment you turned on the server until you get a prompt
What is GRUB2?
What is Secure Boot?
What can you find in /boot?
Linux Disk & Filesystem
What's an inode?
For each file (and directory) in Linux there is an inode, a data structure which stores meta data related to the file like its size, owner, permissions, etc.
Which of the following is not included in inode:
- Link count
- File size
- File name
- File timestamp
File name (it's part of the directory file)
How to check which disks are currently mounted?
Run mount
You run the mount command but you get no output. How would you check what mounts you have on your system?
cat /proc/mounts
What is the difference between a soft link and hard link?
Hard link is the same file, using the same inode. Soft link is a shortcut to another file, using a different inode.
True or False? You can create an hard link for a directory
False
True or False? You can create a soft link between different filesystems
True
What happens when you delete the original file in case of soft link and hard link?
Can you check what type of filesystem is used in /home?
There are many answers for this question. One way is running df -T
What is a swap partition? What is it used for?
How to create a
- new empty file
- a file with text (without using text editor)
- a file with given size
You are trying to create a new file but you get "File system is full". You check with df for free space and you see you used only 20% of the space. What could be the problem?
How would you check what is the size of a certain directory?
du -sh
What is LVM?
Explain the following in regards to LVM:
- PV
- VG
- LV
What is NFS? What is it used for?
What RAID is used for? Can you explain the differences between RAID 0, 1, 5 and 10?
Describe the process of extending a filesystem disk space
What is lazy umount?
What is tmpfs?
What is stored in each of the following logs?
- /var/log/messages
- /var/log/boot.log
True or False? both /tmp and /var/tmp cleared upon system boot
False. /tmp is cleared upon system boot while /var/tmp is cleared every a couple of days or not cleared at all (depends on distro).
Linux Performance Analysis
How to check what is the current load average?
One can use uptime or top
You know how to see the load average, great. but what each part of it means? for example 1.43, 2.34, 2.78
This article summarizes the load average topic in a great way
How to check process usage?
pidstat
How to check disk I/O?
iostat -xz 1
How to check how much free memory a system has? How to check memory consumption by each process?
You can use the commands top and free
How to check TCP stats?
sar -n TCP,ETCP 1
Linux Processes
how to list all the processes running in your system?
ps -ef
How to run a process in the background and why to do that in the first place?
You can achieve that by specifying & at the end of the command. As to why, since some commands/processes can take a lot of time to finish execution or run forever, you may want to run them in the background instead of waiting for them to finish before gaining control again in current session.
How can you find how much memory a specific process consumes?
What signal is used by default when you run 'kill *process id*'?
The default signal is SIGTERM (15). This signal kills process gracefully which means it allows it to save current state configuration.
What signals are you familiar with?
SIGTERM - default signal for terminating a process SIGHUP - common usage is for reloading configuration SIGKILL - a signal which cannot caught or ignored
To view all available signals run kill -l
What kill 0 does?
What kill -0 does?
What is a trap?
Every couple of days, a certain process stops running. How can you look into why it's happening?
What happens when you press ctrl + c?
What is a Daemon in Linux?
A background process. Most of these processes are waiting for requests or set of conditions to be met before actually running anything. Some examples: sshd, crond, rpcbind.
What are the possible states of a process in Linux?
Running (R) Uninterruptible Sleep (D) - The process is waiting for I/O Interruptible Sleep (S) Stopped (T) Dead (x) Zombie (z)
How do you kill a process in D state?
What is a zombie process?
A process which has finished to run but has not exited.
One reason it happens is when a parent process is programmed incorrectly. Every parent process should execute wait() to get the exit code from the child process which finished to run. But when the parent isn't checking for the child exit code, the child process can still exists although it finished to run.
How to get rid of zombie processes?
You can't kill a zombie process the regular way with kill -9 for example as it's already dead.
One way to kill zombie process is by sending SIGCHLD to the parent process telling it to terminate its child processes. This might not work if the parent process wasn't programmed properly. The invocation is kill -s SIGCHLD [parent_pid]
You can also try closing/terminating the parent process. This will make the zombie process a child of init (1) which does periodic cleanups and will at some point clean up the zombie process.
How to find all the
- Processes executed/owned by a certain user
- Process which are Java processes
- Zombie Processes
If you mention at any point ps command with arugments, be familiar with what these arguments does exactly.
What is the init process?
It is the first process executed by the kernel during the booting of a system. It is a daemon process which runs till the system is shutdown. That is why, it is the parent of all the processes
Can you describe how processes are being created?
How to change the priority of a process? Why would you want to do that?
Can you explain how network process/connection is established and how it's terminated?>
What strace does? What about ltrace?
Find all the files which end with '.yml' and replace the number 1 in 2 in each file
find /some_dir -iname *.yml -print0 | xargs -0 -r sed -i "s/1/2/g"
You run ls and you get "/lib/ld-linux-armhf.so.3 no such file or directory". What is the problem?
The ls executable is built for an incompatible architecture.
How would you split a 50 lines file into 2 files of 25 lines each?
You can use the split command this way: split -l 25 some_file
What is a file descriptor? What file descriptors are you familiar with?
Kerberos File descriptor, also known as file handler, is a unique number which identifies an open file in the operating system.
In Linux (and Unix) the first three file descriptors are:
- 0 - the default data stream for input
- 1 - the default data stream for output
- 2 - the default data stream for output related to errors
This is a great article on the topic: https://www.computerhope.com/jargon/f/file-descriptor.htm
What is NTP? What is it used for?
Explain Kernel OOM
Linux Security
What is chroot? In what scenarios would you consider using it?
What is SELiunx?
What is Kerberos?
What is nftables?
What firewalld daemon is responsible for?
Do you have experience with hardening servers? Can you describe the process?
Linux Networking
How to list all the interfaces?
ip link show
What is the loopback (lo) interface?
The loopback interface is a special, virtual network interface that your computer uses to communicate with itself. It is used mainly for diagnostics and troubleshooting, and to connect to servers running on the local machine.
What the following commands are used for?
- ip addr
- ip route
- ip link
- ping
- netstat
- traceroute
What is a network namespace? What is it used for?
How to check if a certain port is being used?
One of the following would work:
netstat -tnlp | grep <port_number>
lsof -i -n -P | grep <port_number>
How can you turn your Linux server into a router?
What is a virtual IP? In what situation would you use it?
True or False? The MAC address of an interface is assigned/set by the OS
False
Can you have more than one default gateway in a given system?
Technically, yes.
Which port is used in each of the following protocols?:
- SSH
- SMTP
- HTTP
- DNS
- HTTPS
- SSH - 22
- SMTP - 35
- HTTP - 80
- DNS - 53
- HTTPS - 443
What is telnet and why is it a bad idea to use it in production? (or at all)
Telnet is a type of client-server protocol that can be used to open a command line on a remote computer, typically a server. By default, all the data sent and received via telnet is transmitted in clear/plain text, therefore it should not be used as it does not encrypt any data between the client and the server.
What is the routing table? How do you view it?
How can you send an HTTP request from your shell?
Using nc is one way
What are packet sniffers? Have you used one in the past? If yes, which packet sniffers have you used and for what purpose?
It is a network utility that analyses and may inject tasks into the data-stream travelling over the targeted network.
How to list active connections?
How to trigger neighbor discovery in IPv6?
One way would be ping6 ff02::1
What is network interface bonding and do you know how it's performed in Linux?
What network bonding modes are there?
There a couple of modes:
- balance-rr: round robing bonding
- active-backup: a fault tolerance mode where only one is active
- balance-tlb: Adaptive transmit load balancing
- balance-alb: Adaptive load balancing
What is a bridge? How it's added in Linux OS?
Linux DNS
How to check what is the hostname of the system?
cat /etc/hostname
You can also run hostnamectl or hostname but that might print only a temporary hostname. The one in the file is the permanent one.
What the file /etc/resolv.conf is used for? What does it include?
What commands are you using for performing DNS queries (or troubleshoot DNS related issues)?
You can specify one or more of the following:
dighostnslookup
Linux Packaging
Do you have experience with packaging? (as in building packages) Can you explain how does it works?
How packages installation/removal is performed on the distribution you are using?
The answer depends on the distribution being used.
In Fedora/CentOS/RHEL/Rocky it can be done with rpm or dnf commands.
In Ubuntu it can be done with the apt command.
RPM: explain the spec format (what it should and can include)
How do you list the content of a package without actually installing it?
How to know to which package a file on the system belongs to? Is it a problem if it doesn't belongs to any package?
Where repositories are stored? (based on the distribution you are using)
What is an archive? How do you create one in Linux?
How to extract the content of an archive?
Why do we need package managers? Why not simply creating archives and publish them?
Package managers allow you to manage packages lifecycle as in installing, removing and updating the packages.
In addition, you can specify in a spec how a certain package will be installed - where to copy the files, which commands to run prior to the installation, post the installation, etc.
Linux DNF
How to look for a package that provides the command /usr/bin/git? (the package isn't necessarily installed)
dnf provides /usr/bin/git
Linux Applications and Services
What can you find in /etc/services?
How to make sure a Service starts automatically after a reboot or crash?
Depends on the init system.
Systemd: systemctl enable [service_name]
System V: update-rc.d [service_name] and add this line id:5678:respawn:/bin/sh /path/to/app to /etc/inittab
Upstart: add Upstart init script at /etc/init/service.conf
You run ssh 127.0.0.1 but it fails with "connection refused". What could be the problem?
- SSH server is not installed
- SSH server is not running
How to print the shared libraries required by a certain program? What is it useful for?
What is CUPS?
What types of web servers are you familiar with?
Nginx, Apache httpd.
Linux Users and Groups
What is a "superuser" (or root user)? How is it different from regular users?
How do you create users? Where user information is stored?
Which file stores information about groups?
How do you change/set the password of a user?
Which file stores users passwords? Is it visible for everyone?
Do you know how to create a new user without using adduser/useradd command?
What information is stored in /etc/passwd? explain each field
How to add a new user to the system without providing him the ability to log-in into the system?
adduser user_name --shell=/bin/false --no-create-home
You can also add a user and then edit /etc/passwd.
How to switch to another user? How to switch to the root user?
su command. Use su - to switch to root
What is the UID the root user? What about a regular user?
What can you do if you lost/forogt the root password?
Re-install the OS IS NOT the right answer :)
What is /etc/skel?
How to see a list of who logged-in to the system?
Using the last command.
Explain what each of the following commands does:
- useradd
- usermod
- whoami
- id
Linux Hardware
Where can you find information on the processor?
/proc/cpuinfo
How can you print information on the BIOS, motherboard, processor and RAM?
dmidecoode
How can you print all the information on connected block devices in your system?
lsblk
Linux - Random
Give 5 commands which are two letters long
ls, wc, dd, df, du, ps, ip, cp, cd ...
What ways are there for creating a new empty file?
- touch new_file
- echo "" > new_file
How `cd -` works? How does it knows the previous location?
$OLDPWD
List three ways to print all the files in the current directory
- ls
- find .
- echo *
How to count the number of lines in a file? What about words?
You define x=2 in /etc/bashrc and x=6 ~/.bashrc you then login to the system. What would be the value of x?
Explain "environment variables". How do you list all environment variables?
How to create your own environment variables?
X=2 for example. But this will persist to new shells. To have it in new shells as well, use export X=2
What a double dash (--) mean?
It's used in commands to mark the end of commands options. One common example is when used with git to discard local changes: git checkout -- some_file
Linux - AWK
What the awk command does? Have you used it? What for?
From Wikipedia: "AWK is domain-specific language designed for text processing and typically used as a data extraction and reporting tool"
How to print the 4th column in a file?
awk '{print $4}' file
How to print every line that is longer than 79 characters?
awk 'length($0) > 79' file
What the lsof command does? Have you used it? What for?
What is the difference between find and locate?
System Calls
Explain the fork() system call
fork() is used for creating a new process. It does so by cloning the calling process but the child process has its own PID and any memory locks, I/O operations and semaphores are not inherited.
Explain the exec() system call
What system call is used for listing files?
What system call is used for creating a new process?
What are the differences between exec() and fork()?
Why do we need the wait system call?
wait() is used by a parent process to wait for the child process to finish execution. If wait is not used by a parent process then a child process might become a zombie process.
What execve() does?
Executes a program. The program is passed as a filename (or path) and must be a binary executable or a script.
What is the return value of malloc?
Explain the pipe() system call. What does it used for?
"Pipes provide a unidirectional interprocess communication channel. A pipe has a read end and a write end. Data written to the write end of a pipe can be read from the read end of the pipe. A pipe is created using pipe(2), which returns two file descriptors, one referring to the read end of the pipe, the other referring to the write end."
What happens when you execute ls -l?
-
Shell reads the input using getline() which reads the input file stream and stores into a buffer as a string
-
The buffer is broken down into tokens and stored in an array this way: {"ls", "-l", "NULL"}
-
Shell checks if an expansion is required (in case of ls *.c)
-
Once the program in memory, its execution starts. First by calling readdir()
Notes:
- getline() originates in GNU C library and used to read lines from input stream and stores those lines in the buffer
What happens when you execute ls -l *.log?
What readdir() system call does?
What exactly the command alias x=y does?
Linux Filesystem & Files
How to create a file of a certain size?
There are a couple of ways to do that:
- dd if=/dev/urandom of=new_file.txt bs=2MB count=1
- truncate -s 2M new_file.txt
- fallocate -l 2097152 new_file.txt
What does the following block do?:
open("/my/file") = 5
read(5, "file content")
open("/my/file") = 5
read(5, "file content")
These system calls are reading the file /my/file and 5 is the file descriptor number.
Describe three different ways to remove a file (or its content)
What is the difference between a process and a thread?
What is context switch?
From wikipedia: a context switch is the process of storing the state of a process or thread, so that it can be restored and resume execution at a later point
You found there is a server with high CPU load but you didn't find a process with high CPU. How is that possible?
Linux Advanced - Networking
When you run ip a you see there is a device called 'lo'. What is it and why do we need it?
What the traceroute command does? How does it works?
Another common way to task this questions is "what part of the tcp header does traceroute modify?"
What is network bonding? What types are you familiar with?
How to link two separate network namespaces so you can ping an interface on one namespace from the second one?
What are cgroups?
Explain Process Descriptor and Task Structure
What are the differences between threads and processes?
Explain Kernel Threads
What happens when socket system call is used?
This is a good article about the topic: https://ops.tips/blog/how-linux-creates-sockets
You executed a script and while still running, it got accidentally removed. Is it possible to restore the script while it's still running?
Linux Memory
What is the difference between MemFree and MemAvailable in /proc/meminfo?
MemFree - The amount of unused physical RAM in your system MemAvailable - The amount of available memory for new workloads (without pushing system to use swap) based on MemFree, Active(file), Inactive(file), and SReclaimable.
What is the difference between paging and swapping?
Explain what is OOM killer
Distribution
What is a Linux distribution?
What Linux distributions are you familiar with?
What are the components of a Linux distribution?
- Kernel
- Utilities
- Services
- Software/Packages Management
Linux Misc
Wildcards are implemented on user or kernel space?
If I plug a new device into a Linux machine, where on the system, a new device entry/file will be created?
/dev
Why there are different sections in man? What is the difference between the sections?
What is User-mode Linux?
Linux Nerds
Under which license Linux is distributed?
GPL v2
Operating System
What is an operating system?
There are many ways to answer that. For those who look for simplicity, the book "Operating Systems: Three Easy Pieces" offers nice version:
"responsible for making it easy to run programs (even allowing you to seemingly run many at the same time), allowing programs to share memory, enabling programs to interact with devices, and other fun stuff like that"
What is "virtual memory" and what purpose it serves?
What is demand paging?
What is copy-on-write or shadowing?
What is a kernel, and what does it do?
The kernel is part of the operating system and is responsible for tasks like:
- Allocating memory
- Schedule processes
- Control CPU
True or False? Some pieces of the code in the kernel are loaded into protected areas of the memory so applications can't overwritten them
True
What is POSIX?
Processes
Can you explain what is a process?
A process is a running program. A program is one or more instructions and the program (or process) is executed by the operating system.
If you had to design an API for processes in an operating system, what would this API look like?
It would support the following:
- Create - allow to create new processes
- Delete - allow to remove/destroy processes
- State - allow to check the state of the process, whether it's running, stopped, waiting, etc.
- Stop - allow to stop a running process
How a process is created?
- The OS is reading program's code and any additional relevant data
- Program's bytes are loaded into the memory or more specifically, into the address space of the process.
- Memory is allocated for program's stack (aka run-time stack). The stack also initialized by the OS with data like argv, argc and parameters to main()
- Memory is allocated for program's heap which is required for data structures like linked lists and hash tables
- I/O initialization tasks are performed, like in Unix/Linux based systems where each process has 3 file descriptors (input, output and error)
- OS is running the program, starting from main()
Note: The loading of the program's code into the memory done lazily which means the OS loads only partial relevant pieces required for the process to run and not the entire code.
True or False? The loading of the program into the memory is done eagerly (all at once)
False. It was true in the past but today's operating systems perform lazy loading which means only the relevant pieces required for the process to run are loaded first.
What are different states of a process?
- Running - it's executing instructions
- Ready - it's ready to run but for different reasons it's on hold
- Blocked - it's waiting for some operation to complete. For example I/O disk request
What is Inter Process Communication (IPC)?
Concurrency
Explain what is Semaphore and what its role in operating systems
Memory
What is cache? What is buffer?
Buffer: Reserved place in RAM which is used to hold data for temporary purposes Cache: Cache is usually used when processes reading and writing to the disk to make the process faster by making similar data used by different programs easily accessible.
Virtualization
What is Virtualization?
Virtualization uses software to create an abstraction layer over computer hardware that allows the hardware elements of a single computer—processors, memory, storage and more - to be divided into multiple virtual computers, commonly called virtual machines (VMs).
What is a hypervisor?
Red Hat: "A hypervisor is software that creates and runs virtual machines (VMs). A hypervisor, sometimes called a virtual machine monitor (VMM), isolates the hypervisor operating system and resources from the virtual machines and enables the creation and management of those VMs."
Read more here
What types of hypervisors are there?
Hosted hypervisors and bare-metal hypervisors.
What are the advantages and disadvantges of bare-metal hypervisor over a hosted hypervisor?
Due to having its own drivers and a direct access to hardware components, a baremetal hypervisor will often have better performances along with stability and scalability.
On the other hand, there will probably be some limitation regarding loading (any) drivers so a hosted hypervisor will usually benefit from having a better hardware compatibility.
What types of virtualization are there?
Operating system virtualization Network functions virtualization Desktop virtualization
Is containerization is a type of Virtualization?
Yes, it's a operating-system-level virtualization, where the kernel is shared and allows to use multiple isolated user-spaces instances.
What is "time sharing"?
Even when using a system with one physical CPU, it's possible to allow multiple users to work on it and run programs. This is possible with time sharing where computing resources are shared in a way it seems to the user the system has multiple CPUs but in fact it's simply one CPU shared by applying multiprogramming and multi-tasking.
What is "space sharing"?
Somewhat the opposite of time sharing. While in time sharing a resource is used for a while by one entity and then the same resource can be used by another resource, in space sharing the space is shared by multiple entities but in a way it's not being transfered between them.
It's used by one entity until this entity decides to get rid of it. Take for example storage. In storage, a file is your until you decide to delete it.
Ansible
Describe each of the following components in Ansible, including the relationship between them:
- Task
- Module
- Play
- Playbook
- Role
Task – a call to a specific Ansible module Module – the actual unit of code executed by Ansible on your own host or a remote host. Modules are indexed by category (database, file, network, …) and also referred to as task plugins.
Play – One or more tasks executed on a given host(s)
Playbook – One or more plays. Each play can be executed on the same or different hosts
Role – Ansible roles allows you to group resources based on certain functionality/service such that they can be easily reused. In a role, you have directories for variables, defaults, files, templates, handlers, tasks, and metadata. You can then use the role by simply specifying it in your playbook.
How Ansible is different from other Automation tools?
Ansible is:
- Agentless
- Minimal run requirements (Python & SSH) and simple to use
- Default mode is "push" (it supports also pull)
- Focus on simpleness and ease-of-use
True or False? Ansible follows the mutable infrastructure paradigm
True.
True or False? Ansible uses declarative style to describe the expected end state
False. It uses a procedural style.
What kind of automation you wouldn't do with Ansible and why?
While it's possible to provision resources with Ansible, some prefer to use tools that follow immutable infrastructure paradigm. Ansible doesn't saves state by default. So a task that creates 5 instances for example, when executed again will create additional 5 instances (unless additional check is implemented) while other tools will check if 5 instances exist. If only 4 exist, additional instance will be created.
What is an inventory file and how do you define one?
An inventory file defines hosts and/or groups of hosts on which Ansible tasks executed upon.
An example of inventory file:
192.168.1.2
192.168.1.3
192.168.1.4
[web_servers]
190.40.2.20
190.40.2.21
190.40.2.22
What is a dynamic inventory file? When you would use one?
A dynamic inventory file tracks hosts from one or more sources like cloud providers and CMDB systems.
You should use one when using external sources and especially when the hosts in your environment are being automatically
spun up and shut down, without you tracking every change in these sources.
How do you list all modules and how can you see details on a specific module?
- Ansible online docs
ansible-doc -lfor list of modules andansible [module_name]for detailed information on a specific module
Write a task to create the directory ‘/tmp/new_directory’
- name: Create a new directory
file:
path: "/tmp/new_directory"
state: directory
You want to run Ansible playbook only on specific minor version of your OS, how would you achieve that?
What the "become" directive used for in Ansible?
What are facts? How to see all the facts of a certain host?
What would be the result of the following play?
---
- name: Print information about my host
hosts: localhost
gather_facts: 'no'
tasks:
- name: Print hostname
debug:
msg: "It's me, {{ ansible_hostname }}"
When given a written code, always inspect it thoroughly. If your answer is “this will fail” then you are right. We are using a fact (ansible_hostname), which is a gathered piece of information from the host we are running on. But in this case, we disabled facts gathering (gather_facts: no) so the variable would be undefined which will result in failure.
What would be the result of running the following task? How to fix it?
- hosts: localhost
tasks:
- name: Install zlib
package:
name: zlib
state: present
- hosts: localhost
tasks:
- name: Install zlib
package:
name: zlib
state: present
Which Ansible best practices are you familiar with?. Name at least three
Explain the directory layout of an Ansible role
What 'blocks' are used for in Ansible?
How do you handle errors in Ansible?
You would like to run a certain command if a task fails. How would you achieve that?
Write a playbook to install ‘zlib’ and ‘vim’ on all hosts if the file ‘/tmp/mario’ exists on the system.
---
- hosts: all
vars:
mario_file: /tmp/mario
package_list:
- 'zlib'
- 'vim'
tasks:
- name: Check for mario file
stat:
path: "{{ mario_file }}"
register: mario_f
- name: Install zlib and vim if mario file exists
become: "yes"
package:
name: "{{ item }}"
state: present
with_items: "{{ package_list }}"
when: mario_f.stat.exists
Write a single task that verifies all the files in files_list variable exist on the host
- name: Ensure all files exist
assert:
that:
- item.stat.exists
loop: "{{ files_list }}"
Write a playbook to deploy the file ‘/tmp/system_info’ on all hosts except for controllers group, with the following content
I'm <HOSTNAME> and my operating system is <OS>
Replace and with the actual data for the specific host you are running on
The playbook to deploy the system_info file
---
- name: Deploy /tmp/system_info file
hosts: all:!controllers
tasks:
- name: Deploy /tmp/system_info
template:
src: system_info.j2
dest: /tmp/system_info
The content of the system_info.j2 template
# {{ ansible_managed }}
I'm {{ ansible_hostname }} and my operating system is {{ ansible_distribution }
The variable 'whoami' defined in the following places:
- role defaults -> whoami: mario
- extra vars (variables you pass to Ansible CLI with -e) -> whoami: toad
- host facts -> whoami: luigi
- inventory variables (doesn’t matter which type) -> whoami: browser
According to variable precedence, which one will be used?
The right answer is ‘toad’.
Variable precedence is about how variables override each other when they set in different locations. If you didn’t experience it so far I’m sure at some point you will, which makes it a useful topic to be aware of.
In the context of our question, the order will be extra vars (always override any other variable) -> host facts -> inventory variables -> role defaults (the weakest).
Here is the order of precedence from least to greatest (the last listed variables winning prioritization):
- command line values (eg “-u user”)
- role defaults [1]
- inventory file or script group vars [2]
- inventory group_vars/all [3]
- playbook group_vars/all [3]
- inventory group_vars/* [3]
- playbook group_vars/* [3]
- inventory file or script host vars [2]
- inventory host_vars/* [3]
- playbook host_vars/* [3]
- host facts / cached set_facts [4]
- play vars
- play vars_prompt
- play vars_files
- role vars (defined in role/vars/main.yml)
- block vars (only for tasks in block)
- task vars (only for the task)
- include_vars
- set_facts / registered vars
- role (and include_role) params
- include params
- extra vars (always win precedence)
A full list can be found at PlayBook Variables . Also, note there is a significant difference between Ansible 1.x and 2.x.
For each of the following statements determine if it's true or false:
- A module is a collection of tasks
- It’s better to use shell or command instead of a specific module
- Host facts override play variables
- A role might include the following: vars, meta, and handlers
- Dynamic inventory is generated by extracting information from external sources
- It’s a best practice to use indention of 2 spaces instead of 4
- ‘notify’ used to trigger handlers
- This “hosts: all:!controllers” means ‘run only on controllers group hosts
Explain the Diffrence between Forks and Serial & Throttle.
Serial is like running the playbook for each host in turn, waiting for completion of the complete playbook before moving on to the next host. forks=1 means run the first task in a play on one host before running the same task on the next host, so the first task will be run for each host before the next task is touched. Default fork is 5 in ansible.
[defaults]
forks = 30
- hosts: webservers
serial: 1
tasks:
- name: ...
Ansible also supports throttle This keyword limits the number of workers up to the maximum set via the forks setting or serial. This can be useful in restricting tasks that may be CPU-intensive or interact with a rate-limiting API
tasks:
- command: /path/to/cpu_intensive_command
throttle: 1
What is ansible-pull? How is it different from how ansible-playbook works?
What is Ansible Vault?
Demonstrate each of the following with Ansible:
- Conditionals
- Loops
What are filters? Do you have experience with writing filters?
Write a filter to capitalize a string
def cap(self, string):
return string.capitalize()
You would like to run a task only if previous task changed anything. How would you achieve that?
What are callback plugins? What can you achieve by using callback plugins?
What is Ansible Collections?
File '/tmp/exercise' includes the following content
Goku = 9001
Vegeta = 5200
Trunks = 6000
Gotenks = 32
With one task, switch the content to:
Goku = 9001
Vegeta = 250
Trunks = 40
Gotenks = 32
Goku = 9001
Vegeta = 5200
Trunks = 6000
Gotenks = 32
Goku = 9001
Vegeta = 250
Trunks = 40
Gotenks = 32
- name: Change saiyans levels
lineinfile:
dest: /tmp/exercise
regexp: "{{ item.regexp }}"
line: "{{ item.line }}"
with_items:
- { regexp: '^Vegeta', line: 'Vegeta = 250' }
- { regexp: '^Trunks', line: 'Trunks = 40' }
...
Ansible Testing
How do you test your Ansible based projects?
What is Molecule? How does it works?
You run Ansibe tests and you get "idempotence test failed". What does it mean? Why idempotence is important?
Terraform
What benefits infrastructure-as-code has?
- fully automated process of provisioning, modifying and deleting your infrastructure
- version control for your infrastructure which allows you to quickly rollback to previous versions
- validate infrastructure quality and stability with automated tests and code reviews
- makes infrastructure tasks less repetitive
Why Terraform and not other technologies? (e.g. Ansible, Puppet, CloufFormation)
A common wrong answer is to say that Ansible and Puppet are configuration management tools and Terraform is a provisioning tool. While technically true, it doesn't mean Ansible and Puppet can't be used for provisioning infrastructure. Also, it doesn't explain why Terraform should be used over CloudFormation if at all.
The benefits of Terraform over the other tools:
- It follows the immutable infrastructure approach which has benefits like avoiding a configuration drift over time
- Ansible and Puppet are more procedural (you mention what to execute in each step) and Terraform is declarative since you describe the overall desired state and not per resource or task. You can give the example of going from 1 to 2 servers in each tool. In Terraform you specify 2, in Ansible and puppet you have to only provision 1 additional server so you need to explicitly make sure you provision only another one server.
True or False? Terraform follows the mutable infrastructure paradigm
False. Terraform follows immutable infrastructure paradigm.
True or False? Terraform uses declarative style to describe the expected end state
True
Explain what is "Terraform configuration"
A configuration is a root module along with a tree of child modules that are called as dependencies from the root module.
What is HCL?
HCL stands for Hashicorp Configuration Language. It is the language Hashicorp made to use as the configuration language for a number of its tools, including terraform.
Explain each of the following:
- Provider
- Resource
- Provisioner
* Provider is any cloud based technology - github, aws, postgresql etc - which one can make an API call to with its unique terraform provider binary to provision available services and components.
* Resources are the services and components you provision on these platforms.
* Provisioner in terraform's lingo specifically refers to configuration tools like ansible or salt-stack which are used in combination with terraform to orchestrate a system.
What terraform.tfstate file is used for?
It keeps track of the IDs of created resources so that Terraform knows what it is managing.
How do you rename an existing resource?
terraform state mv
Explain what the following commands do:
terraform initterraform planterraform validateterraform apply
terraform initterraform planterraform validateterraform applyterraform init scans your code to figure which providers are you using and download them.
terraform plan will let you see what terraform is about to do before actually doing it.
terraform validate checks if configuration is syntactically valid and internally consistent within a directory.
terraform apply will provision the resources specified in the .tf files.
How to write down a variable which changes by an external source or during terraform apply?
You use it this way: variable “my_var” {}
Give an example of several Terraform best practices
Explain how implicit and explicit dependencies work in Terraform
What is local-exec and remote-exec in the context of provisioners?
What is a "tainted resource"?
It's a resource which was successfully created but failed during provisioning. Terraform will fail and mark this resource as "tainted".
What terraform taint does?
terraform taint resource.id manually marks the resource as tainted in the state file. So when you run terraform apply the next time, the resource will be destroyed and recreated.
What types of variables are supported in Terraform?
string number bool list() set() map() object({<ATTR_NAME> = , ... }) tuple([, ...])
What is a data source? In what scenarios for example would need to use it?
Data sources lookup or compute values that can be used elsewhere in terraform configuration.
There are quite a few cases you might need to use them:
- you want to reference resources not managed through terraform
- you want to reference resources managed by a different terraform module
- you want to cleanly compute a value with typechecking, such as with
aws_iam_policy_document
What are output variables and what terraform output does?
Output variables are named values that are sourced from the attributes of a module. They are stored in terraform state, and can be used by other modules through
remote_state
Explain Modules
A Terraform module is a set of Terraform configuration files in a single directory. Modules are small, reusable Terraform configurations that let you manage a group of related resources as if they were a single resource. Even a simple configuration consisting of a single directory with one or more .tf files is a module. When you run Terraform commands directly from such a directory, it is considered the root module. So in this sense, every Terraform configuration is part of a module.
What is the Terraform Registry?
The Terraform Registry provides a centralized location for official and community-managed providers and modules.
Explain remote-exec and local-exec
Explain "Remote State". When would you use it and how?
Terraform generates a `terraform.tfstate` json file that describes components/service provisioned on the specified provider. Remote State stores this file in a remote storage media to enable collaboration amongst team.
Explain "State Locking"
State locking is a mechanism that blocks an operations against a specific state file from multiple callers so as to avoid conflicting operations from different team members. Once the first caller's operation's lock is released the other team member may go ahead to carryout his own operation. Nevertheless Terraform will first check the state file to see if the desired resource already exist and if not it goes ahead to create it.
What is the "Random" provider? What is it used for
The random provider aids in generating numeric or alphabetic characters to use as a prefix or suffix for a desired named identifier.
How do you test a terraform module?
Many examples are acceptable, but the most common answer would likely to be using the tool
terratest, and to test that a module can be initialized, can create resources, and can destroy those resources cleanly.
Aside from .tfvars files or CLI arguments, how can you inject dependencies from other modules?
The built-in terraform way would be to use
remote-state to lookup the outputs from other modules.
It is also common in the community to use a tool called terragrunt to explicitly inject variables between modules.
Containers
Containers Exercises
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| My First Dockerfile | Dockerfile | Link | Link |
Containers Self Assesment
What is a Container? What is it used for?
Containers are a form of operating system virtualization. A single container might be used to run anything from a small microservice or software process to a larger application. Inside a container are all the necessary executables, binary code, libraries, and configuration files, making them easy to ship and run with same expected results on different machines.
How are containers different from virtual machines (VMs)?
The primary difference between containers and VMs is that containers allow you to virtualize multiple workloads on the operating system while in the case of VMs the hardware is being virtualized to run multiple machines each with its own OS. You can also think about it as containers are for OS-level virtualization while VMs are for hardware virtualization.
- Containers don't require an entire guest operating system as VMs. Containers share the system's kernel as opposed to VMs
- It usually takes a few seconds to set up a container as opposed to VMs which can take minutes or at least more time than containers as there is an entire OS to boot and initialize as opposed to container where you mainly lunch the app itself
- Containers are isolated from each other, but not as concretely as virtual machines. It is possible for a malicious user to break into the host OS from a container and vice versa.
In which scenarios would you use containers and in which you would prefer to use VMs?
You should choose VMs when:
- you need run an application which requires all the resources and functionalities of an OS
- you need full isolation and security
You should choose containers when:
- you need a lightweight solution
- Running multiple versions or instances of a single application
Explain Podman or Docker architecture
Describe in detail what happens when you run `podman/docker run hello-world`?
Docker CLI passes your request to Docker daemon. Docker daemon downloads the image from Docker Hub Docker daemon creates a new container by using the image it downloaded Docker daemon redirects output from container to Docker CLI which redirects it to the standard output
What are `dockerd, docker-containerd, docker-runc, docker-containerd-ctr, docker-containerd-shim` ?
dockerd - The Docker daemon itself. The highest level component in your list and also the only 'Docker' product listed. Provides all the nice UX features of Docker.
(docker-)containerd - Also a daemon, listening on a Unix socket, exposes gRPC endpoints. Handles all the low-level container management tasks, storage, image distribution, network attachment, etc...
(docker-)containerd-ctr - A lightweight CLI to directly communicate with containerd. Think of it as how 'docker' is to 'dockerd'.
(docker-)runc - A lightweight binary for actually running containers. Deals with the low-level interfacing with Linux capabilities like cgroups, namespaces, etc...
(docker-)containerd-shim - After runC actually runs the container, it exits (allowing us to not have any long-running processes responsible for our containers). The shim is the component which sits between containerd and runc to facilitate this.

Describe difference between cgroups and namespaces
cgroup: Control Groups provide a mechanism for aggregating/partitioning sets of tasks, and all their future children, into hierarchical groups with specialized behaviour. namespace: wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource.
In short:
Cgroups = limits how much you can use; namespaces = limits what you can see (and therefore use)
Cgroups involve resource metering and limiting: memory CPU block I/O network
Namespaces provide processes with their own view of the system
Multiple namespaces: pid,net, mnt, uts, ipc, user
Describe in detail what happens when you run `docker pull image:tag`?
Docker CLI passes your request to Docker daemon. Dockerd Logs shows the process
docker.io/library/busybox:latest resolved to a manifestList object with 9 entries; looking for a unknown/amd64 match
found match for linux/amd64 with media type application/vnd.docker.distribution.manifest.v2+json, digest sha256:400ee2ed939df769d4681023810d2e4fb9479b8401d97003c710d0e20f7c49c6
pulling blob "sha256:61c5ed1cbdf8e801f3b73d906c61261ad916b2532d6756e7c4fbcacb975299fb Downloaded 61c5ed1cbdf8 to tempfile /var/lib/docker/tmp/GetImageBlob909736690
Applying tar in /var/lib/docker/overlay2/507df36fe373108f19df4b22a07d10de7800f33c9613acb139827ba2645444f7/diff" storage-driver=overlay2
Applied tar sha256:514c3a3e64d4ebf15f482c9e8909d130bcd53bcc452f0225b0a04744de7b8c43 to 507df36fe373108f19df4b22a07d10de7800f33c9613acb139827ba2645444f7, size: 1223534
How do you run a container?
podman run or docker run
What `podman commit` does?. When will you use it?
Create a new image from a container’s changes
How would you transfer data from one container into another?
What happens to data of the container when a container exists?
Explain what each of the following commands do:
- docker run
- docker rm
- docker ps
- docker pull
- docker build
- docker commit
How do you remove old, non running, containers?
- To remove one or more Docker images use the docker container rm command followed by the ID of the containers you want to remove.
- The docker system prune command will remove all stopped containers, all dangling images, and all unused networks
- docker rm $(docker ps -a -q) - This command will delete all stopped containers. The command docker ps -a -q will return all existing container IDs and pass them to the rm command which will delete them. Any running containers will not be deleted.
Dockerfile
What is Dockerfile
Docker can build images automatically by reading the instructions from a Dockerfile. A Dockerfile is a text document that contains all the commands a user could call on the command line to assemble an image.
What is the difference between ADD and COPY in Dockerfile?
COPY takes in a src and destination. It only lets you copy in a local file or directory from your host (the machine building the Docker image) into the Docker image itself. ADD lets you do that too, but it also supports 2 other sources. First, you can use a URL instead of a local file / directory. Secondly, you can extract a tar file from the source directly into the destination. Although ADD and COPY are functionally similar, generally speaking, COPY is preferred. That’s because it’s more transparent than ADD. COPY only supports the basic copying of local files into the container, while ADD has some features (like local-only tar extraction and remote URL support) that are not immediately obvious.
What is the difference between CMD and RUN in Dockerfile?
RUN lets you execute commands inside of your Docker image. These commands get executed once at build time and get written into your Docker image as a new layer. CMD is the command the container executes by default when you launch the built image. A Dockerfile can only have one CMD. You could say that CMD is a Docker run-time operation, meaning it’s not something that gets executed at build time. It happens when you run an image. A running image is called a container.
Do you perform any checks or testing related to your Dockerfile?
A common answer to this is to use hadolint project which is a linter based on Dockerfile best practices.
Explain what is Docker compose and what is it used for
Compose is a tool for defining and running multi-container Docker applications. With Compose, you use a YAML file to configure your application’s services. Then, with a single command, you create and start all the services from your configuration.
For example, you can use it to set up ELK stack where the services are: elasticsearch, logstash and kibana. Each running in its own container.
Describe the process of using Docker Compose
- Define the services you would like to run together in a docker-compose.yml file
- Run
docker-compose upto run the services
Explain Docker interlock
Where can you store Docker images?
What is Docker Hub?
What is the difference between Docker Hub and Docker cloud?
Docker Hub is a native Docker registry service which allows you to run pull and push commands to install and deploy Docker images from the Docker Hub.
Docker Cloud is built on top of the Docker Hub so Docker Cloud provides you with more options/features compared to Docker Hub. One example is Swarm management which means you can create new swarms in Docker Cloud.
What is Docker Repository?
Explain image layers
A Docker image is built up from a series of layers. Each layer represents an instruction in the image’s Dockerfile. Each layer except the very last one is read-only. Each layer is only a set of differences from the layer before it. The layers are stacked on top of each other. When you create a new container, you add a new writable layer on top of the underlying layers. This layer is often called the “container layer”. All changes made to the running container, such as writing new files, modifying existing files, and deleting files, are written to this thin writable container layer. The major difference between a container and an image is the top writable layer. All writes to the container that add new or modify existing data are stored in this writable layer. When the container is deleted, the writable layer is also deleted. The underlying image remains unchanged. Because each container has its own writable container layer, and all changes are stored in this container layer, multiple containers can share access to the same underlying image and yet have their own data state.
What best practices are you familiar related to working with containers?
How do you manage persistent storage in Docker?
How can you connect from the inside of your container to the localhost of your host, where the container runs?
How do you copy files from Docker container to the host and vice versa?
Kubernetes
Kubernetes Exercises
Developer & Regular User Path
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| My First Pod | Pods | Exercise | Solution | |
| Creating a service | Service | Exercise | Solution |
Kubernetes Self Assesment
What is Kubernetes? Why organizations are using it?
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.
To understand what Kubernetes is good for, let's look at some examples:
- You would like to run a certain application in a container on multiple different locations. Sure, if it's 2-3 servers/locations, you can do it by yourself but it can be challenging to scale it up to additional multiple location.
- Performing updates and changes across hundreds of containers
- Handle cases where the current load requires to scale up (or down)
What is a Kubernetes Cluster?
Red Hat Definition: "A Kubernetes cluster is a set of node machines for running containerized applications. If you’re running Kubernetes, you’re running a cluster.
At a minimum, a cluster contains a worker node and a master node."
Read more here
When or why NOT to use Kubernetes?
Kubernetes Nodes
What is a Node?
A node is a virtual machine or a physical server that serves as a worker for running the applications. It's recommended to have at least 3 nodes in Kubernetes production environment.
What the master node is responsible for?
The master coordinates all the workflows in the cluster:
- Scheduling applications
- Managing desired state
- Rolling out new updates
What do we need the worker nodes for?
The workers are the nodes which run the applications and workloads.
What is kubectl?
Which command you run to view your nodes?
kubectl get nodes
True or False? Every cluster must have 0 or more master nodes and at least on e worker
False. A Kubernetes cluster consists of at least 1 master and can have 0 workers (although that wouldn't be very useful...)
What are the components of the master node?
- API Server - the Kubernetes API. All cluster components communicate through it
- Scheduler - assigns an application with a worker node it can run on
- Controller Manager - cluster maintenance (replications, node failures, etc.)
- etcd - stores cluster configuration
What are the components of a worker node?
- Kubelet - an agent responsible for node communication with the master.
- Kube-proxy - load balancing traffic between app components
- Container runtime - the engine runs the containers (Podman, Docker, ...)
Kubernetes Pod
Explain what is a pod
Deploy a pod called "my-pod" using the nginx:alpine image
kubectl run my-pod --image=nginx:alpine --restart=Never
How many containers can a pod contain?
Multiple containers but in most cases it would be one container per pod.
What does it mean that "pods are ephemeral?
It means they would eventually die and pods are unable to heal so it is recommended that you don't create them directly.
Which command you run to view all pods running on all namespaces?
kubectl get pods --all-namespaces
How to delete a pod?
kubectl delete pod pod_name
Kubernetes Deployment
What is a "Deployment" in Kubernetes?
How to create a deployment?
cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
EOF
How to edit a deployment?
kubectl edit deployment some-deployment
What happens after you edit a deployment and change the image?
The pod will terminate and another, new pod, will be created.
Also, when looking at the replicaset, you'll see the old replica doesn't have any pods and a new replicaset is created.
How to delete a deployment?
One way is by specifying the deployment name: kubectl delete deployment [deployment_name]
Another way is using the deployment configuration file: kubectl delete -f deployment.yaml
What happens when you delete a deployment?
The pod related to the deployment will terminate and the replicaset will be removed.
How make an app accessible on private or external network?
Using a Service.
Kubernetes Service
What is a Service in Kubernetes?
"An abstract way to expose an application running on a set of Pods as a network service." - read more [here](https://kubernetes.io/docs/concepts/services-networking/service)
In simpler words, it allows you to expose the service by attaching permanent IP address for example to a certain pod.
True or False? The lifecycle of Pods and Services isn't connected so when a pod dies, the service still stays
True
How to get information on a certain service?
kubctl describe service [service_name]
How to verify that a certain service forwards the requests to a pod
Run kubectl describe service and if the IPs from "Endpoints" match any IPs from the output of kubectl get pod -o wide
What is the difference between an external and an internal service?
How to turn the following service into an external one?
spec:
selector:
app: some-app
ports:
- protocol: TCP
port: 8081
targetPort: 8081
spec:
selector:
app: some-app
ports:
- protocol: TCP
port: 8081
targetPort: 8081
Adding type: LoadBalancer and nodePort
spec:
selector:
app: some-app
type: LoadBalancer
ports:
- protocol: TCP
port: 8081
targetPort: 8081
nodePort: 32412
What would you use to route traffic from outside the Kubernetes cluster to services within a cluster?
Ingress
Kubernetes Ingress
What is Ingress?
From Kubernetes docs: "Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource."
Read more here
Complete the following configuration file to make it Ingress
metadata:
name: someapp-ingress
spec:
metadata:
name: someapp-ingress
spec:
There are several ways to answer this question.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: someapp-ingress
spec:
rules:
- host: my.host
http:
paths:
- backend:
serviceName: someapp-internal-service
servicePort: 8080
Explain the meaning of "http", "host" and "backend" directives
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: someapp-ingress
spec:
rules:
- host: my.host
http:
paths:
- backend:
serviceName: someapp-internal-service
servicePort: 8080
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: someapp-ingress
spec:
rules:
- host: my.host
http:
paths:
- backend:
serviceName: someapp-internal-service
servicePort: 8080
host is the entry point of the cluster so basically a valid domain address that maps to cluster's node IP address
the http line used for specifying that incoming requests will be forwarded to the internal service using http.
backend is referencing the internal service (serviceName is the name under metadata and servicePort is the port under the ports section).
What is Ingress Controller?
An implementation for Ingress. It's basically another pod (or set of pods) that does evaluates and processes Ingress rules and this it manages all the redirections.
There are multiple Ingress Controller implementations (the one from Kubernetes is Kubernetes Nginx Ingress Controller).
What are some use cases for using Ingress?
- Multiple sub-domains (multiple host entries, each with its own service)
- One domain with multiple services (multiple paths where each one is mapped to a different service/application)
How to list Ingress in your namespace?
kubectl get ingress
What is Ingress Default Backend?
It specifies what do with an incoming request to the Kubernetes cluster that isn't mapped to any backend (= no rule to for mapping the request to a service). If the default backend service isn't defined, it's recommended to define so users still see some kind of message instead of nothing or unclear error.
How to configure a default backend?
Create Service resource that specifies the name of the default backend as reflected in kubectl desrcibe ingress ... and the port under the ports section.
How to configure TLS with Ingress?
Add tls and secretName entries.
spec:
tls:
- hosts:
- some_app.com
secretName: someapp-secret-tls
True or False? When configuring Ingress with TLS, the Secret component must be in the same namespace as the Ingress component
True
Kubernetes Configuration File
Which parts a configuration file has?
It has three main parts:
- Metadata
- Specification
- Status (this automatically generated and added by Kubernetes)
What is the format of a configuration file?
YAML
How to get latest configuration of a deployment?
kubectl get deployment [deployment_name] -o yaml
Where Kubernetes gets the status data (which is added to the configuration file) from?
etcd
Kubernetes etcd
What is etcd?
True or False? Etcd holds the current status of any kubernetes component
True
True or False? The API server is the only component which communicates directly with etcd
True
True or False? application data is not stored in etcd
True
Kubernetes Namespaces
What are namespaces?
Namespaces allow you split your cluster into virtual clusters where you can group your applications in a way that makes sense and is completely separated from the other groups (so you can for example create an app with the same name in two different namespaces)
Why to use namespaces? What is the problem with using one default namespace?
When using the default namespace alone, it becomes hard over time to get an overview of all the applications you manage in your cluster. Namespaces make it easier to organize the applications into groups that makes sense, like a namespace of all the monitoring applications and a namespace for all the security applications, etc.
Namespaces can also be useful for managing Blue/Green environments where each namespace can include a different version of an app and also share resources that are in other namespaces (namespaces like logging, monitoring, etc.).
Another use case for namespaces is one cluster, multiple teams. When multiple teams use the same cluster, they might end up stepping on each others toes. For example if they end up creating an app with the same name it means one of the teams overriden the app of the other team because there can't be too apps in Kubernetes with the same name (in the same namespace).
True or False? When a namespace is deleted all resources in that namespace are not deleted but moved to another default namespace
False. When a namespace is deleted, the resources in that namespace are deleted as well.
What special namespaces are there by default when creating a Kubernetes cluster?
- default
- kube-system
- kube-public
- kube-node-lease
What can you find in kube-system namespace?
- Master and Kubectl processes
- System processes
How to list all namespaces?
kubectl get namespaces
What kube-public contains?
- A configmap, which contains cluster information
- Publicely accessible data
How to get the name of the current namespace?
kubectl config view | grep namespace
What kube-node-lease contains?
It holds information on hearbeats of nodes. Each node gets an object which holds information about its availability.
How to create a namespace?
One way is by running kubectl create namespace [NAMESPACE_NAME]
Another way is by using namespace configuration file:
apiVersion: v1
kind: ConfigMap
metadata:
name: some-cofngimap
namespace: some-namespace
What default namespace contains?
Any resource you create while using Kubernetes.
True or False? With namespaces you can limit the resources consumed by the users/teams
True. With namespaces you can limit CPU, RAM and storage usage.
How to switch to another namespace? In other words how to change active namespace?
kubectl config set-context --current --namespace=some-namespace and validate with kubectl config view --minify | grep namespace:
OR
kubens some-namespace
What is Resource Quota?
How to create a Resource Quota?
kubectl create quota some-quota --hard-cpu=2,pods=2
Which resources are accessible from different namespaces?
Service.
Let's say you have three namespaces: x, y and z. In x namespace you have a ConfigMap referencing service in z namespace. Can you reference the ConfigMap in x namespace from y namespace?
No, you would have to create separate namespace in y namespace.
Which service and in which namespace the following file is referencing?
apiVersion: v1
kind: ConfigMap
metadata:
name: some-configmap
data:
some_url: samurai.jack
apiVersion: v1
kind: ConfigMap
metadata:
name: some-configmap
data:
some_url: samurai.jack
It's referencing the service "samurai" in the namespace called "jack".
Which components can't be created within a namespace?
Volume and Node.
How to list all the components that bound to a namespace?
kubectl api-resources --namespaced=true
How to create components in a namespace?
One way is by specifying --namespace like this: kubectl apply -f my_component.yaml --namespace=some-namespace
Another way is by specifying it in the YAML itself:
apiVersion: v1
kind: ConfigMap
metadata:
name: some-configmap
namespace: some-namespace
and you can verify with: kubectl get configmap -n some-namespace
Kubernetes Commands
What kubectl exec does?
What kubectl get all does?
What the command kubectl get pod does?
How to see all the components of a certain application?
kubectl get all | grep [APP_NAME]
What kubectl apply -f [file] does?
What the command kubectl api-resources --namespaced=false does?
Lists the components that doesn't bound to a namespace.
How to print information on a specific pod?
kubectl describe pod pod_name
How to execute the command "ls" in an existing pod?
kubectl exec some-pod -it -- ls
How to create a service that exposes a deployment?
kubectl expose deploy some-deployment --port=80 --target-port=8080
How to create a pod and a service with one command?
kubectl run nginx --image=nginx --restart=Never --port 80 --expose
Describe in detail what the following command does kubectl create deployment kubernetes-httpd --image=httpd
Why to create kind deployment, if pods can be launched with replicaset?
How to scale a deployment to 8 replicas?
kubectl scale deploy some-deployment --replicas=8
How to get list of resources which are not in a namespace?
kubectl api-resources --namespaced=false
How to delete all pods whose status is not "Running"?
kubectl delete pods --field-selector=status.phase!='Running'
What kubectl logs [pod-name] command does?
What kubectl describe pod [pod name] does? command does?
How to display the resources usages of pods?
kubectl top pod
What kubectl get componentstatus does?
Outputs the status of each of the control plane components.
What is Minikube?
Minikube is a lightweight Kubernetes implementation. It create a local virtual machine and deploys a simple (single node) cluster.
How do you monitor your Kubernetes?
You suspect one of the pods is having issues, what do you do?
Start by inspecting the pods status. we can use the command kubectl get pods (--all-namespaces for pods in system namespace)
If we see "Error" status, we can keep debugging by running the command kubectl describe pod [name]. In case we still don't see anything useful we can try stern for log tailing.
In case we find out there was a temporary issue with the pod or the system, we can try restarting the pod with the following kubectl scale deployment [name] --replicas=0
Setting the replicas to 0 will shut down the process. Now start it with kubectl scale deployment [name] --replicas=1
What the Kubernetes Scheduler does?
What happens to running pods if if you stop Kubelet on the worker nodes?
What happens what pods are using too much memory? (more than its limit)
They become candidates to for termination.
Describe how roll-back works
True or False? Memory is a compressible resource, meaning that when a container reach the memory limit, it will keep running
False. CPU is a compressible resource while memory is a non compressible resource - once a container reached the memory limit, it will be terminated.
Kubernetes Operator
What is an Operator?
Explained here
"Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop."
Why do we need Operators?
The process of managing stateful applications in Kubernetes isn't as straightforward as managing stateless applications where reaching the desired status and upgrades are both handled the same way for every replica. In stateful applications, upgrading each replica might require different handling due to the stateful nature of the app, each replica might be in a different status. As a result, we often need a human operator to manage stateful applications. Kubernetes Operator is suppose to assist with this.
This also help with automating a standard process on multiple Kubernetes clusters
What components the Operator consists of?
- CRD (custom resource definition)
- Controller - Custom control loop which runs against the CRD
How Operator works?
It uses the control loop used by Kubernetes in general. It watches for changes in the application state. The difference is that is uses a custom control loop. In additions.
In addition, it also makes use of CRD's (Custom Resources Definitions) so basically it extends Kubernetes API.
True or False? Kubernetes Operator used for stateful applications
True
What is the Operator Framework?
open source toolkit used to manage k8s native applications, called operators, in an automated and efficient way.
What components the Operator Framework consists of?
- Operator SDK - allows developers to build operators
- Operator Lifecycle Manager - helps to install, update and generally manage the lifecycle of all operators
- Operator Metering - Enables usage reporting for operators that provide specialized services
Describe in detail what is the Operator Lifecycle Manager
It's part of the Operator Framework, used for managing the lifecycle of operators. It basically extends Kubernetes so a user can use a declarative way to manage operators (installation, upgrade, ...).
What openshift-operator-lifecycle-manager namespace includes?
It includes:
- catalog-operator - Resolving and installing ClusterServiceVersions the resource they specify.
- olm-operator - Deploys applications defined by ClusterServiceVersion resource
What is kubconfig? What do you use it for?
Can you use a Deployment for stateful applications?
Explain StatefulSet
Kubernetes ReplicaSet
What is the purpose of ReplicaSet?
How a ReplicaSet works?
What happens when a replica dies?
Kubernetes Secrets
Explain Kubernetes Secrets
Secrets let you store and manage sensitive information (passwords, ssh keys, etc.)
How to create a Secret from a key and value?
kubectl create secret generic some-secret --from-literal=password='donttellmypassword'
How to create a Secret from a file?
kubectl create secret generic some-secret --from-file=/some/file.txt
What type: Opaque in a secret file means? What other types are there?
Opaque is the default type used for key-value pairs.
True or False? storing data in a Secret component makes it automatically secured
False. Some known security mechanisms like "encryption" aren't enabled by default.
What is the problem with the following Secret file:
apiVersion: v1
kind: Secret
metadata:
name: some-secret
type: Opaque
data:
password: mySecretPassword
apiVersion: v1
kind: Secret
metadata:
name: some-secret
type: Opaque
data:
password: mySecretPassword
Password isn't encrypted. You should run something like this: `echo -n 'mySecretPassword' | base64` and paste the result to the file instead of using plain-text.
How to create a Secret from a configuration file?
kubectl apply -f some-secret.yaml
What the following in Deployment configuration file means?
spec:
containers:
- name: USER_PASSWORD
valueFrom:
secretKeyRef:
name: some-secret
key: password
spec:
containers:
- name: USER_PASSWORD
valueFrom:
secretKeyRef:
name: some-secret
key: password
USER_PASSWORD environment variable will store the value from password key in the secret called "some-secret" In other words, you reference a value from a Kubernetes Secret.
Kubernetes Storage
True or False? Kubernetes provides data persistence out of the box, so when you restart a pod, data is saved
False
Explain "Persistent Volumes". Why do we need it?
Persistent Volumes allow us to save data so basically they provide storage that doesn't depend on the pod lifecycle.
True or False? Persistent Volume must be available to all nodes because the pod can restart on any of them
True
What types of persistent volumes are there?
- NFS
- iSCSI
- CephFS
- ...
What is PersistentVolumeClaim?
True or False? Kubernetes manages data persistence
False
Explain Storage Classes
Explain "Dynamic Provisioning" and "Static Provisioning"
Explain Access Modes
What is Reclaim Policy?
What reclaim policies are there?
- Retain
- Recycle
- Delete
Kubernetes Access Control
What is RBAC?
Explain the Role and RoleBinding" objects
What is the difference between Role and ClusterRole objects?
Kubernetes Misc
Explain what Kubernetes Service Discovery means
You have one Kubernetes cluster and multiple teams that would like to use it. You would like to limit the resources each team consumes in the cluster. Which Kubernetes concept would you use for that?
Namespaces will allow to limit resources and also make sure there are no collisions between teams when working in the cluster (like creating an app with the same name).
What Kube Proxy does?
What "Resources Quotas" are used for and how?
Explain ConfigMap
Separate configuration from pods. It's good for cases where you might need to change configuration at some point but you don't want to restart the application or rebuild the image so you create a ConfigMap and connect it to a pod but externally to the pod.
Overall it's good for:
- Sharing the same configuration between different pods
- Storing external to the pod configuration
How to use ConfigMaps?
- Create it (from key&value, a file or an env file)
- Attach it. Mount a configmap as a volume
Trur or False? Sensitive data, like credentials, should be stored in a ConfigMap
False. Use secret.
Explain "Horizontal Pod Autoscaler"
Scale the number of pods automatically on observed CPU utilization.
When you delete a pod, is it deleted instantly? (a moment after running the command)
How to delete a pod instantly?
Use "--grace-period=0 --force"
Explain Liveness probe
Explain Readiness probe
What does being cloud-native mean?
Explain the pet and cattle approach of infrastructure with respect to kubernetes
Describe how you one proceeds to run a containerised web app in K8s, which should be reachable from a public URL.
How would you troubleshoot your cluster if some applications are not reachable any more?
Describe what CustomResourceDefinitions there are in the Kubernetes world? What they can be used for?
How does scheduling work in kubernetes?
The control plane component kube-scheduler asks the following questions,
- What to schedule? It tries to understand the pod-definition specifications
- Which node to schedule? It tries to determine the best node with available resources to spin a pod
- Binds the Pod to a given node
View more here
How are labels and selectors used?
Explain what is CronJob and what is it used for
What QoS classes are there?
- Guaranteed
- Burstable
- BestEffort
Explain Labels. What are they and why would one use them?
Explain Selectors
What is Kubeconfig?
Helm
What is Helm?
Package manager for Kubernetes. Basically the ability to package YAML files and distribute them to other users and apply them in different clusters.
Why do we need Helm? What would be the use case for using it?
Sometimes when you would like to deploy a certain application to your cluster, you need to create multiple YAML files/components like: Secret, Service, ConfigMap, etc. This can be tedious task. So it would make sense to ease the process by introducing something that will allow us to share these bundle of YAMLs every time we would like to add an application to our cluster. This something is called Helm.
A common scenario is having multiple Kubernetes clusters (prod, dev, staging). Instead of individually applying different YAMLs in each cluster, it makes more sense to create one Chart and install it in every cluster.
Explain "Helm Charts"
Helm Charts is a bundle of YAML files. A bundle that you can consume from repositories or create your own and publish it to the repositories.
It is said that Helm is also Templating Engine. What does it mean?
It is useful for scenarios where you have multiple applications and all are similar, so there are minor differences in their configuration files and most values are the same. With Helm you can define a common blueprint for all of them and the values that are not fixed and change can be placeholders. This is called a template file and it looks similar to the following
apiVersion: v1
kind: Pod
metadata:
name: {[ .Values.name ]}
spec:
containers:
- name: {{ .Values.container.name }}
image: {{ .Values.container.image }}
port: {{ .Values.container.port }}
The values themselves will in separate file:
name: some-app
container:
name: some-app-container
image: some-app-image
port: 1991
What are some use cases for using Helm template file?
- Deploy the same application across multiple different environments
- CI/CD
Explain the Helm Chart Directory Structure
someChart/ -> the name of the chart Chart.yaml -> meta information on the chart values.yaml -> values for template files charts/ -> chart dependencies templates/ -> templates files :)
How do you search for charts?
helm search hub [some_keyword]
Is it possible to override values in values.yaml file when installing a chart?
Yes. You can pass another values file: `helm install --values=override-values.yaml [CHART_NAME]`
Or directly on the command line: helm install --set some_key=some_value
How Helm supports release management?
Helm allows you to upgrade, remove and rollback to previous versions of charts. In version 2 of Helm it was with what is known as "Tiller". In version 3, it was removed due to security concerns.
Submariner
Explain what is Submariner and what is it used for
"Submariner enables direct networking between pods and services in different Kubernetes clusters, either on premise or in the cloud."
You can learn more here
What each of the following components does?:
- Lighthouse
- Broker
- Gateway Engine
- Route Agent
Istio
What is Istio? What is it used for?
Programming
What programming language do you prefer to use for DevOps related tasks? Why specifically this one?
What are static typed (or simply typed) languages?
In static typed languages the variable type is known at compile-time instead of at run-time. Such languages are: C, C++ and Java
Explain expressions and statements
An expression is anything that results in a value (even if the value is None). Basically, any sequence of literals so, you can say that a string, integer, list, ... are all expressions.
Statements are instructions executed by the interpreter like variable assignments, for loops and conditionals (if-else).
What is Object Oriented Programming? Why is it important?
Explain Composition
What is a compiler?
What is an interpreter?
Are you familiar with SOLID design principles?
SOLID design principles are about:
- Make it easier to extend the functionality of the system
- Make the code more readable and easier to maintain
SOLID is:
- Single Responsibility - A class should only have a single responsibility
- Open-Closed - An entity should be open for extension, but closed for modification. What this practically means is that you should extend functionality by adding a new code and not by modifying it. Your system should be separated into components so it can be easily extended without breaking everything.
- Liskov Substitution - Any derived class should be able to substitute the its parent without altering its corrections. Practically, every part of the code will get the expected result no matter which part is using it
- Interface segregation - A client should never depend on anything it doesn't uses
- Dependency Inversion - High level modules should depend on abstractions, not low level modules
What is YAGNI? What is your opinion on it?
What is DRY? What is your opinion on it?
What are the four pillars of object oriented programming?
Explain recursion
Explain Inversion of Control
Explain Dependency Injection
True or False? In Dynamically typed languages the variable type is known at run-time instead of at compile-time
True
Explain what are design patterns and describe three of them in detail
Explain big O notation
What is "Duck Typing"?
Common algorithms
Binary search:
- How does it works?
- Can you implement it? (in any language you prefer)
- What is the average performance of the algorithm you wrote?
It's a search algorithm used with sorted arrays/lists to find a target value by dividing the array each iteration and comparing the middle value to the target value. If the middle value is smaller than target value, then the target value is searched in the right part of the divided array, else in the left side. This continues until the value is found (or the array divided max times)
The average performance of the above algorithm is O(log n). Best performance can be O(1) and worst O(log n).
Code Review
What are your code-review best practices?
Do you agree/disagree with each of the following statements and why?:
- The commit message is not important. When reviewing a change/patch one should focus on the actual change
- You shouldn't test your code before submitting it. This is what CI/CD exists for.
Strings
In any language you want, write a function to determine if a given string is a palindrome
In any language you want, write a function to determine if two strings are Anagrams
Integers
In any language you would like, print the numbers from 1 to a given integer. For example for input: 5, the output is: 12345
Time Complexity
Describe what would be the time complexity of the operations access, search insert and remove for the following data structures:
- Stack
- Queue
- Linked List
- Binary Search Tree
What is the complexity for the best, worst and average cases of each of the following algorithms?:
- Quick sort
- Merge sort
- Bucket Sort
- Radix Sort
Data Structures & Types
Implement Stack in any language you would like
Tell me everything you know about Linked Lists
- A linked list is a data structure
- It consists of a collection of nodes. Together these nodes represent a sequence
- Useful for use cases where you need to insert or remove an element from any position of the linked list
- Some programming languages don't have linked lists as a built-in data type (like Python for example) but it can be easily implemented
Describe (no need to implement) how to detect a loop in a Linked List
There are multiple ways to detect a loop in a linked list. I'll mention three here:
Worst solution:
Two pointers where one points to the head and one points to the last node. Each time you advance the last pointer by one and check whether the distance between head pointer to the moved pointer is bigger than the last time you measured the same distance (if not, you have a loop).
The reason it's probably the worst solution, is because time complexity here is O(n^2)
Decent solution:
Create an hash table and start traversing the linked list. Every time you move, check whether the node you moved to is in the hash table. If it isn't, insert it to the hash table. If you do find at any point the node in the hash table, it means you have a loop. When you reach None/Null, it's the end and you can return "no loop" value. This one is very easy to implement (just create a hash table, update it and check whether the node is in the hash table every time you move to the next node) but since the auxiliary space is O(n) because you create a hash table then, it's not the best solution
Good solution:
Instead of creating a hash table to document which nodes in the linked list you have visited, as in the previous solution, you can modify the Linked List (or the Node to be precise) to have a "visited" attribute. Every time you visit a node, you set "visited" to True.
Time compleixty is O(n) and Auxiliary space is O(1), so it's a good solution but the only problem, is that you have to modify the Linked List.
Best solution:
You set two pointers to traverse the linked list from the beginning. You move one pointer by one each time and the other pointer by two. If at any point they meet, you have a loop. This solution is also called "Floyd's Cycle-Finding"
Time complexity is O(n) and auxiliary space is O(1). Perfect :)
Implement Hash table in any language you would like
What is Integer Overflow? How is it handled?
Name 3 design patterns. Do you know how to implement (= provide an example) these design pattern in any language you'll choose?
Given an array/list of integers, find 3 integers which are adding up to 0 (in any language you would like)
def find_triplets_sum_to_zero(li):
li = sorted(li)
for i, val in enumerate(li):
low, up = 0, len(li)-1
while low < i < up:
tmp = var + li[low] + li[up]
if tmp > 0:
up -= 1
elif tmp < 0:
low += 1
else:
yield li[low], val, li[up]
low += 1
up -= 1
Python
What are some characteristics of the Python programming language?
1. It is a high level general purpose programming language created in 1991 by Guido Van Rosum.
2. The language is interpreted, being the CPython (Written in C) the most used/maintained implementation.
3. It is strongly typed. The typing discipline is duck typing and gradual.
4. Python focuses on readability and makes use of whitespaces/identation instead of brackets { }
5. The python package manager is called PIP "pip installs packages", having more than 200.000 available packages.
6. Python comes with pip installed and a big standard library that offers the programmer many precooked solutions.
7. In python **Everything** is an object.
What built-in types Python has?
List
Dictionary
Set
Numbers (int, float, ...)
String
Bool
Tuple
Frozenset
What is mutability? Which of the built-in types in Python are mutable?
Mutability determines whether you can modify an object of specific type.
The mutable data types are:
List
Dictionary
Set
The immutable data types are:
Numbers (int, float, ...)
String
Bool
Tuple
Frozenset
What is a tuple in Python? What is it used for?
A tuple is a built-in data type in Python. It's used for storing multiple items in a single variable.
List, like a tuple, is also used for storing multiple items. What is then, the difference between a tuple and a list?
List, as opposed to a tuple, is a mutable data type. It means we can modify it and at items to it.
What is the result of each of the following?
-
1 > 2
-
'b' > 'a'
-
1 == 'one'
-
2 > 'one'
1 > 2
'b' > 'a'
1 == 'one'
2 > 'one'
False
True
False
TypeError
What is the result of of each of the following?
-
"abc"*3
-
"abc"*2.5
-
"abc"*2.0
-
"abc"*True
-
"abc"*False
"abc"*3
"abc"*2.5
"abc"*2.0
"abc"*True
"abc"*False
abcabcabc
TypeError
TypeError
"abc"
""
What is the result of `bool("")`? What about `bool(" ")`? Explain
bool("") -> evaluates to False
bool(" ") -> evaluates to True
What is the result of running [] is not []? explain the result
It evaluates to True.
The reason is that the two created empty list are different objects. x is y only evaluates to true when x and y are the same object.
Improve the following code:
char = input("Insert a character: ")
if char == "a" or char == "o" or char == "e" or char =="u" or char == "i":
print("It's a vowel!")
char = input("Insert a character: ")
if char == "a" or char == "o" or char == "e" or char =="u" or char == "i":
print("It's a vowel!")
char = input("Insert a character: ") # For readablity
if lower(char[0]) in "aieou": # Takes care of multiple characters and separate cases
print("It's a vowel!")
OR
if lower(input("Insert a character: ")[0]) in "aieou": # Takes care of multiple characters and small/Capital cases
print("It's a vowel!")
How to define a function with Python?
Using the `def` keyword. For Examples:
def sum(a, b):
return (a + b)
In Python, functions are first-class objects. What does it mean?
In general, first class objects in programming languages are objects which can be assigned to variable, used as a return value and can be used as arguments or parameters.
In python you can treat functions this way. Let's say we have the following function
def my_function():
return 5
You can then assign a function to a variables like this x = my_function or you can return functions as return values like this return my_function
Explain inheritance and how to use it in Python
By definition inheritance is the mechanism where an object acts as a base of another object, retaining all its
properties.
So if Class B inherits from Class A, every characteristics from class A will be also available in class B.
Class A would be the 'Base class' and B class would be the 'derived class'.
This comes handy when you have several classes that share the same functionalities.
The basic syntax is:
class Base: pass
class Derived(Base): pass
A more forged example:
class Animal:
def __init__(self):
print("and I'm alive!")
def eat(self, food):
print("ñom ñom ñom", food)
class Human(Animal):
def __init__(self, name):
print('My name is ', name)
super().__init__()
def write_poem(self):
print('Foo bar bar foo foo bar!')
class Dog(Animal):
def __init__(self, name):
print('My name is', name)
super().__init__()
def bark(self):
print('woof woof')
michael = Human('Michael')
michael.eat('Spam')
michael.write_poem()
bruno = Dog('Bruno')
bruno.eat('bone')
bruno.bark()
>>> My name is Michael
>>> and I'm alive!
>>> ñom ñom ñom Spam
>>> Foo bar bar foo foo bar!
>>> My name is Bruno
>>> and I'm alive!
>>> ñom ñom ñom bone
>>> woof woof
Calling super() calls the Base method, thus, calling super().__init__() we called the Animal __init__.
There is a more advanced python feature called MetaClasses that aid the programmer to directly control class creation.
Explain and demonstrate class attributes & instance attributes
In the following block of code x is a class attribute while self.y is a instance attribute
class MyClass(object):
x = 1
def __init__(self, y):
self.y = y
Python - Exceptions
What is an error? What is an exception? What types of exceptions are you familiar with?
# Note that you generally don't need to know the compiling process but knowing where everything comes from
# and giving complete answers shows that you truly know what you are talking about.
Generally, every compiling process have a two steps.
- Analysis
- Code Generation.
Analysis can be broken into:
1. Lexical analysis (Tokenizes source code)
2. Syntactic analysis (Check whether the tokens are legal or not, tldr, if syntax is correct)
for i in 'foo'
^
SyntaxError: invalid syntax
We missed ':'
3. Semantic analysis (Contextual analysis, legal syntax can still trigger errors, did you try to divide by 0,
hash a mutable object or use an undeclared function?)
1/0
ZeroDivisionError: division by zero
These three analysis steps are the responsible for error handlings.
The second step would be responsible for errors, mostly syntax errors, the most common error.
The third step would be responsible for Exceptions.
As we have seen, Exceptions are semantic errors, there are many builtin Exceptions:
ImportError
ValueError
KeyError
FileNotFoundError
IndentationError
IndexError
...
You can also have user defined Exceptions that have to inherit from the `Exception` class, directly or indirectly.
Basic example:
class DividedBy2Error(Exception):
def __init__(self, message):
self.message = message
def division(dividend,divisor):
if divisor == 2:
raise DividedBy2Error('I dont want you to divide by 2!')
return dividend / divisor
division(100, 2)
>>> __main__.DividedBy2Error: I dont want you to divide by 2!
Explain Exception Handling and how to use it in Python
Exceptions: Errors detected during execution are called Exceptions.
Handling Exception: When an error occurs, or exception as we call it, Python will normally stop and generate an error message.
Exceptions can be handled using try and except statement in python.
Example: Following example asks the user for input until a valid integer has been entered.
If user enter a non-integer value it will raise exception and using except it will catch that exception and ask the user to enter valid integer again.
while True:
try:
a = int(input("please enter an integer value: "))
break
except ValueError:
print("Ops! Please enter a valid integer value.")
For more details about errors and exceptions follow this https://docs.python.org/3/tutorial/errors.html
What is the result of running the following function?
def true_or_false():
try:
return True
finally:
return False
def true_or_false():
try:
return True
finally:
return False
False
Python Built-in functions
Explain the following built-in functions (their purpose + use case example):
- repr
- any
- all
What is the difference between repr function and str?
What is the __call__ method?
Do classes has the __call__ method as well? What for?
What _ is used for in Python?
- Translation lookup in i18n
- Hold the result of the last executed expression or statement in the interactive interpreter.
- As a general purpose "throwaway" variable name. For example: x, y, _ = get_data() (x and y are used but since we don't care about third variable, we "threw it away").
Explain what is GIL
What is Lambda? How is it used?
A lambda expression is an 'anonymous' function, the difference from a normal defined function using the keyword `def`` is the syntax and usage.
The syntax is:
lambda[parameters]: [expresion]
Examples:
- A lambda function add 10 with any argument passed.
x = lambda a: a + 10
print(x(10))
- An addition function
addition = lambda x, y: x + y
print(addition(10, 20))
- Squaring function
square = lambda x : x ** 2
print(square(5))
Generally it is considered a bad practice under PEP 8 to assign a lambda expresion, they are meant to be used as parameters and inside of other defined functions.
Properties
Are there private variables in Python? How would you make an attribute of a class, private?
Explain the following:
- getter
- setter
- deleter
Explain what is @property
How do you swap values between two variables?
x, y = y, x
Explain the following object's magic variables:
- dict
Write a function to return the sum of one or more numbers. The user will decide how many numbers to use
First you ask the user for the amount of numbers that will be use. Use a while loop that runs until amount_of_numbers becomes 0 through subtracting amount_of_numbers by one each loop. In the while loop you want ask the user for a number which will be added a variable each time the loop runs.
def return_sum():
amount_of_numbers = int(input("How many numbers? "))
total_sum = 0
while amount_of_numbers != 0:
num = int(input("Input a number. "))
total_sum += num
amount_of_numbers -= 1
return total_sum
Print the average of [2, 5, 6]. It should be rounded to 3 decimal places
li = [2, 5, 6]
print("{0:.3f}".format(sum(li)/len(li)))
Python Lists
How to add the number 2 to the list x = [1, 2, 3]
x.append(2)
How to check how many items a list contains?
len(sone_list)
How to get the last element of a list?
some_list[-1]
How to add the items of [1, 2, 3] to the list [4, 5, 6]?
x = [4, 5, 6] x.extend([1, 2, 3])
Don't use append unless you would like the list as one item.
How to remove the first 3 items from a list?
my_list[0:3] = []
How do you get the maximum and minimum values from a list?
Maximum: max(some_list)
Minimum: min(some_list)
How to get the top/biggest 3 items from a list?
sorted(some_list, reverse=True)[:3]
Or
some_list.sort(reverse=True)
some_list[:3]
How to insert an item to the beginning of a list? What about two items?
How to sort list by the length of items?
sorted_li = sorted(li, key=len)
Or without creating a new list:
li.sort(key=len)
Do you know what is the difference between list.sort() and sorted(list)?
-
sorted(list) will return a new list (original list doesn't change)
-
list.sort() will return None but the list is change in-place
-
sorted() works on any iterable (Dictionaries, Strings, ...)
-
list.sort() is faster than sorted(list) in case of Lists
Convert every string to an integer: [['1', '2', '3'], ['4', '5', '6']]
nested_li = [['1', '2', '3'], ['4', '5', '6']]
[[int(x) for x in li] for li in nested_li]
How to merge two sorted lists into one sorted list?
sorted(li1 + li2)
Another way:
i, j = 0
merged_li = []
while i < len(li1) and j < len(li2):
if li1[i] < li2[j]:
merged_li.append(li1[i])
i += 1
else:
merged_li.append(li2[j])
j += 1
merged_li = merged_li + merged_li[i:] + merged_li[j:]
How to check if all the elements in a given lists are unique? so [1, 2, 3] is unique but [1, 1, 2, 3] is not unique because 1 exists twice
There are many ways of solving this problem:
# Note: :list and -> bool are just python typings, they are not needed for the correct execution of the algorithm.
Taking advantage of sets and len:
def is_unique(l:list) -> bool:
return len(set(l)) == len(l)
This one is can be seen used in other programming languages.
def is_unique2(l:list) -> bool:
seen = []
for i in l:
if i in seen:
return False
seen.append(i)
return True
Here we just count and make sure every element is just repeated once.
def is_unique3(l:list) -> bool:
for i in l:
if l.count(i) > 1:
return False
return True
This one might look more convulated but hey, one liners.
def is_unique4(l:list) -> bool:
return all(map(lambda x: l.count(x) < 2, l))
You have the following function
def my_func(li = []):
li.append("hmm")
print(li)
If we call it 3 times, what would be the result each call?
def my_func(li = []):
li.append("hmm")
print(li)
['hmm']
['hmm', 'hmm']
['hmm', 'hmm', 'hmm']
How to iterate over a list?
for item in some_list:
print(item)
How to iterate over a list with indexes?
for i, item in enumerate(some_list):
print(i)
How to start list iteration from 2nd index?
Using range like this
for i in range(1, len(some_list)):
some_list[i]
Another way is using slicing
for i in some_list[1:]:
How to iterate over a list in reverse order?
Method 1
for i in reversed(li):
...
Method 2
n = len(li) - 1
while n > 0:
...
n -= 1
Sort a list of lists by the second item of each nested list
li = [[1, 4], [2, 1], [3, 9], [4, 2], [4, 5]]
sorted(li, key=lambda l: l[1])
or
li.sort(key=lambda l: l[1)
Combine [1, 2, 3] and ['x', 'y', 'z'] so the result is [(1, 'x'), (2, 'y'), (3, 'z')]
nums = [1, 2, 3]
letters = ['x', 'y', 'z']
list(zip(nums, letters))
What is List Comprehension? Is it better than a typical loop? Why? Can you demonstrate how to use it?
You have the following list: [{'name': 'Mario', 'food': ['mushrooms', 'goombas']}, {'name': 'Luigi', 'food': ['mushrooms', 'turtles']}]
Extract all type of foods. Final output should be: {'mushrooms', 'goombas', 'turtles'}
brothers_menu = \
[{'name': 'Mario', 'food': ['mushrooms', 'goombas']}, {'name': 'Luigi', 'food': ['mushrooms', 'turtles']}]
# "Classic" Way
def get_food(brothers_menu) -> set:
temp = []
for brother in brothers_menu:
for food in brother['food']:
temp.append(food)
return set(temp)
# One liner way (Using list comprehension)
set([food for bro in x for food in bro['food']])
Python Dictionaries
How to create a dictionary?
my_dict = dict(x=1, y=2) OR my_dict = {'x': 1, 'y': 2} OR my_dict = dict([('x', 1), ('y', 2)])
How to remove a key from a dictionary?
del my_dict['some_key']
you can also use my_dict.pop('some_key') which returns the value of the key.
How to sort a dictionary by values?
{k: v for k, v in sorted(x.items(), key=lambda item: item[1])}
How to sort a dictionary by keys?
dict(sorted(some_dictionary.items()))
How to merge two dictionaries?
some_dict1.update(some_dict2)
Convert the string "a.b.c" to the dictionary {'a': {'b': {'c': 1}}}
output = {}
string = "a.b.c"
path = string.split('.')
target = reduce(lambda d, k: d.setdefault(k, {}), path[:-1], output)
target[path[-1]] = 1
print(output)
Common Algorithms Implementation
Python Files
How to write to a file?
with open('file.txt', 'w') as file:
file.write("My insightful comment")
How to print the 12th line of a file?
How to reverse a file?
Sum all the integers in a given file
Print a random line of a given file
Print every 3rd line of a given file
Print the number of lines in a given file
Print the number of of words in a given file
Can you write a function which will print all the file in a given directory? including sub-directories
Write a dictionary (variable) to a file
import json
with open('file.json', 'w') as f:
f.write(json.dumps(dict_var))
Python OS
How to print current working directory?
import os
print(os.getcwd())
Given the path /dir1/dir2/file1 print the file name (file1)
import os
print(os.path.basename('/dir1/dir2/file1'))
# Another way
print(os.path.split('/dir1/dir2/file1')[1])
Given the path /dir1/dir2/file1
- Print the path without the file name (/dir1/dir2)
- Print the name of the directory where the file resides (dir2)
import os
## Part 1.
# os.path.dirname gives path removing the end component
dirpath = os.path.dirname('/dir1/dir2/file1')
print(dirpath)
## Part 2.
print(os.path.basename(dirpath))
How do you execute shell commands using Python?
How do you join path components? for example /home and luig will result in /home/luigi
How do you remove non-empty directory?
Python Regex
How do you perform regular expressions related operations in Python? (match patterns, substitute strings, etc.)
Using the re module
How to substitute the string "green" with "blue"?
How to find all the IP addresses in a variable? How to find them in a file?
Python Strings
Find the first repeated character in a string
While you iterate through the characters, store them in a dictionary and check for every character whether it's already in the dictionary.
def firstRepeatedCharacter(str):
chars = {}
for ch in str:
if ch in chars:
return ch
else:
chars[ch] = 0
How to extract the unique characters from a string? for example given the input "itssssssameeeemarioooooo" the output will be "mrtisaoe"
x = "itssssssameeeemarioooooo"
y = ''.join(set(x))
Find all the permutations of a given string
def permute_string(string):
if len(string) == 1:
return [string]
permutations = []
for i in range(len(string)):
swaps = permute_string(string[:i] + string[(i+1):])
for swap in swaps:
permutations.append(string[i] + swap)
return permutations
print(permute_string("abc"))
Short way (but probably not acceptable in interviews):
from itertools import permutations
[''.join(p) for p in permutations("abc")]
Detailed answer can be found here: http://codingshell.com/python-all-string-permutations
How to check if a string contains a sub string?
Find the frequency of each character in string
Count the number of spaces in a string
Given a string, find the N most repeated words
Given the string (which represents a matrix) "1 2 3\n4 5 6\n7 8 9" create rows and colums variables (should contain integers, not strings)
What is the result of each of the following?
>> ', '.join(["One", "Two", "Three"])
>> " ".join("welladsadgadoneadsadga".split("adsadga")[:2])
>> "".join(["c", "t", "o", "a", "o", "q", "l"])[0::2]
>> ', '.join(["One", "Two", "Three"])
>> " ".join("welladsadgadoneadsadga".split("adsadga")[:2])
>> "".join(["c", "t", "o", "a", "o", "q", "l"])[0::2]
>>> 'One, Two, Three'
>>> 'well done'
>>> 'cool'
How to reverse a string? (e.g. pizza -> azzip)
The correct way is:
my_string[::-1]
A more visual way is:
Careful: this is very slow
def reverse_string(string):
temp = ""
for char in string:
temp = char + temp
return temp
Reverse each word in a string (while keeping the order)
What is the output of the following code: "".join(["a", "h", "m", "a", "h", "a", "n", "q", "r", "l", "o", "i", "f", "o", "o"])[2::3]
mario
Python Iterators
What is an iterator?
Python Misc
Explain data serialization and how do you perform it with Python
How do you handle argument parsing in Python?
What is a generator? Why using generators?
What would be the output of the following block?
for i in range(3, 3):
print(i)
for i in range(3, 3):
print(i)
No output :)
What is yeild? When would you use it?
Explain the following types of methods and how to use them:
- Static method
- Class method
- instance method
How to reverse a list?
How to combine list of strings into one string with spaces between the strings
You have the following list of nested lists: [['Mario', 90], ['Geralt', 82], ['Gordon', 88]] How to sort the list by the numbers in the nested lists?
One way is:
the_list.sort(key=lambda x: x[1])
Explain the following:
- zip()
- map()
- filter()
Python - Slicing
For the following slicing exercises, assume you have the following list: my_list = [8, 2, 1, 10, 5, 4, 3, 9]
What is the result of `my_list[0:4]`?
What is the result of `my_list[5:6]`?
What is the result of `my_list[5:5]`?
What is the result of `my_list[::-1]`?
What is the result of `my_list[::3]`?
What is the result of `my_list[2:]`?
What is the result of `my_list[:3]`?
Python Debugging
How do you debug Python code?
pdb :D
How to check how much time it took to execute a certain script or block of code?
What empty return returns?
Short answer is: It returns a None object.
We could go a bit deeper and explain the difference between
def a ():
return
>>> None
And
def a ():
pass
>>> None
Or we could be asked this as a following question, since they both give the same result.
We could use the dis module to see what's going on:
2 0 LOAD_CONST 0 (<code object a at 0x0000029C4D3C2DB0, file "<dis>", line 2>)
2 LOAD_CONST 1 ('a')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (a)
5 8 LOAD_CONST 2 (<code object b at 0x0000029C4D3C2ED0, file "<dis>", line 5>)
10 LOAD_CONST 3 ('b')
12 MAKE_FUNCTION 0
14 STORE_NAME 1 (b)
16 LOAD_CONST 4 (None)
18 RETURN_VALUE
Disassembly of <code object a at 0x0000029C4D3C2DB0, file "<dis>", line 2>:
3 0 LOAD_CONST 0 (None)
2 RETURN_VALUE
Disassembly of <code object b at 0x0000029C4D3C2ED0, file "<dis>", line 5>:
6 0 LOAD_CONST 0 (None)
2 RETURN_VALUE
An empty return is exactly the same as return None and functions without any explicit return
will always return None regardless of the operations, therefore
def sum(a, b):
global c
c = a + b
>>> None
How to improve the following block of code?
li = []
for i in range(1, 10):
li.append(i)
li = []
for i in range(1, 10):
li.append(i)
[i for i in range(1, 10)]
Given the following function
def is_int(num):
if isinstance(num, int):
print('Yes')
else:
print('No')
What would be the result of is_int(2) and is_int(False)?
def is_int(num):
if isinstance(num, int):
print('Yes')
else:
print('No')
Python - Linked List
Can you implement a linked list in Python?
The reason we need to implement in the first place, it's because a linked list isn't part of Python standard library.
To implement a linked list, we have to implement two structures: The linked list itself and a node which is used by the linked list.
Let's start with a node. A node has some value (the data it holds) and a pointer to the next node
class Node(object):
def __init__(self, data):
self.data = data
self.next = None
Now the linked list. An empty linked list has nothing but an empty head.
class LinkedList(object):
def __init__(self):
self.head = None
Now we can start using the linked list
ll = Linkedlist()
ll.head = Node(1)
ll.head.next = Node(2)
ll.head.next.next = Node(3)
What we have is:
| 1 | -> | 2 | -> | 3 |
Usually, more methods are implemented, like a push_head() method where you insert a node at the beginning of the linked list
def push_head(self, value):
new_node = Node(value)
new_node.next = self.head
self.head = new_node
Add a method to the Linked List class to traverse (print every node's data) the linked list
def print_list(self): node = self.head while(node): print(node.data) node = node.next
Write a method to that will return a boolean based on whether there is a loop in a linked list or not
Let's use the Floyd's Cycle-Finding algorithm:
def loop_exists(self):
one_step_p = self.head
two_steps_p = self.head
while(one_step_p and two_steps_p and two_steps_p.next):
one_step_p = self.head.next
two_step_p = self.head.next.next
if (one_step_p == two_steps_p):
return True
return False
Python - Stack
Implement Stack in Python
Python Testing
What is your experience with writing tests in Python?
What is PEP8? Give an example of 3 style guidelines
PEP8 is a list of coding conventions and style guidelines for Python
5 style guidelines:
1. Limit all lines to a maximum of 79 characters.
2. Surround top-level function and class definitions with two blank lines.
3. Use commas when making a tuple of one element
4. Use spaces (and not tabs) for indentation
5. Use 4 spaces per indentation level
How to test if an exception was raised?
What assert does in Python?
Explain mocks
How do you measure execution time of small code snippets?
Why one shouldn't use assert in non-test/production code?
Flask
Can you describe what is Django/Flask and how you have used it? Why Flask and not Djano? (or vice versa)
What is a route?
What is a blueprint in Flask?
What is a template?
zip
Given x = [1, 2, 3], what is the result of list(zip(x))?
[(1,), (2,), (3,)]
What is the result of each of the following:
list(zip(range(5), range(50), range(50)))
list(zip(range(5), range(50), range(-2)))
list(zip(range(5), range(50), range(50)))
list(zip(range(5), range(50), range(-2)))
[(0, 0, 0), (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4)]
[]
Python Descriptors
What would be the result of running a.num2 assuming the following code
class B:
def __get__(self, obj, objtype=None):
reuturn 10
class A:
num1 = 2
num2 = Five()
class B:
def __get__(self, obj, objtype=None):
reuturn 10
class A:
num1 = 2
num2 = Five()
10
What would be the result of running some_car = Car("Red", 4) assuming the following code
class Print:
def __get__(self, obj, objtype=None):
value = obj._color
print("Color was set to {}".format(valie))
return value
def __set__(self, obj, value):
print("The color of the car is {}".format(value))
obj._color = value
class Car:
color = Print()
def __ini__(self, color, age):
self.color = color
self.age = age
class Print:
def __get__(self, obj, objtype=None):
value = obj._color
print("Color was set to {}".format(valie))
return value
def __set__(self, obj, value):
print("The color of the car is {}".format(value))
obj._color = value
class Car:
color = Print()
def __ini__(self, color, age):
self.color = color
self.age = age
An instance of Car class will be created and the following will be printed: "The color of the car is Red"
Python Misc
How can you spawn multiple processes with Python?
Implement simple calculator for two numbers
def add(num1, num2):
return num1 + num2
def sub(num1, num2):
return num1 - num2
def mul(num1, num2):
return num1*num2
def div(num1, num2):
return num1 / num2
operators = {
'+': add,
'-': sub,
'*': mul,
'/': div
}
if __name__ == '__main__':
operator = str(input("Operator: "))
num1 = int(input("1st number: "))
num2 = int(input("2nd number: "))
print(operators[operator](num1, num2))
What data types are you familiar with that are not Python built-in types but still provided by modules which are part of the standard library?
This is a good reference https://docs.python.org/3/library/datatypes.html
Explain what is a decorator
In python, everything is an object, even functions themselves. Therefore you could pass functions as arguments for another function eg;
def wee(word):
return word
def oh(f):
return f + "Ohh"
>>> oh(wee("Wee"))
<<< Wee Ohh
This allows us to control the before execution of any given function and if we added another function as wrapper, (a function receiving another function that receives a function as parameter) we could also control the after execution.
Sometimes we want to control the before-after execution of many functions and it would get tedious to write
f = function(function_1())
f = function(function_1(function_2(*args)))
every time, that's what decorators do, they introduce syntax to write all of this on the go, using the keyword '@'.
Can you show how to write and use decorators?
These two decorators (ntimes and timer) are usually used to display decorators functionalities, you can find them in lots of
tutorials/reviews. I first saw these examples two years ago in pyData 2017. https://www.youtube.com/watch?v=7lmCu8wz8ro&t=3731s
Simple decorator:
def deco(f):
print(f"Hi I am the {f.__name__}() function!")
return f
@deco
def hello_world():
return "Hi, I'm in!"
a = hello_world()
print(a)
>>> Hi I am the hello_world() function!
Hi, I'm in!
This is the simplest decorator version, it basically saves us from writting a = deco(hello_world()).
But at this point we can only control the before execution, let's take on the after:
def deco(f):
def wrapper(*args, **kwargs):
print("Rick Sanchez!")
func = f(*args, **kwargs)
print("I'm in!")
return func
return wrapper
@deco
def f(word):
print(word)
a = f("************")
>>> Rick Sanchez!
************
I'm in!
deco receives a function -> f wrapper receives the arguments -> *args, **kwargs
wrapper returns the function plus the arguments -> f(*args, **kwargs) deco returns wrapper.
As you can see we conveniently do things before and after the execution of a given function.
For example, we could write a decorator that calculates the execution time of a function.
import time
def deco(f):
def wrapper(*args, **kwargs):
before = time.time()
func = f(*args, **kwargs)
after = time.time()
print(after-before)
return func
return wrapper
@deco
def f():
time.sleep(2)
print("************")
a = f()
>>> 2.0008859634399414
Or create a decorator that executes a function n times.
def n_times(n):
def wrapper(f):
def inner(*args, **kwargs):
for _ in range(n):
func = f(*args, **kwargs)
return func
return inner
return wrapper
@n_times(4)
def f():
print("************")
a = f()
>>>************
************
************
************
Write a decorator that calculates the execution time of a function
Write a script which will determine if a given host is accessible on a given port
Are you familiar with Dataclasses? Can you explain what are they used for?
You wrote a class to represent a car. How would you compare two cars instances if two cars are equal if they have the same model and color?
class Car:
def __init__(self, model, color):
self.model = model
self.color = color
def __eq__(self, other):
if not isinstance(other, Car):
return NotImplemented
return self.model == other.model and self.color == other.color
>> a = Car('model_1', 'red')
>> b = Car('model_2', 'green')
>> c = Car('model_1', 'red')
>> a == b
False
>> a == c
True
Explain Context Manager
Tell me everything you know about concurrency in Python
Explain the Buffer Protocol
Do you have experience with web scraping? Can you describe what have you used and for what?
Can you implement Linux's tail command in Python? Bonus: implement head as well
You have created a web page where a user can upload a document. But the function which reads the uploaded files, runs for a long time, based on the document size and user has to wait for the read operation to complete before he/she can continue using the web site. How can you overcome this?
How yield works exactly?
Monitoring
Explain monitoring. What is it? What its goal?
Google: "Monitoring is one of the primary means by which service owners keep track of a system’s health and availability".
What is wrong with the old approach of watching for a specific value and trigger an email/phone alert while value is exceeded?
This approach require from a human to always check why the value exceeded and how to handle it while today, it is more effective to notify people only when they need to take an actual action. If the issue doesn't require any human intervention, then the problem can be fixed by some processes running in the relevant environment.
What types of monitoring outputs are you familiar with and/or used in the past?
Alerts
Tickets
Logging
What is the different between infrastructure monitoring and application monitoring? (methods, tools, ...)
Prometheus
What is Prometheus? What are some of Prometheus's main features?
Describe Prometheus architecture and components
Can you compare Prometheus to other solutions like InfluxDB for example?
What is an Alert?
Describe the following Prometheus components:
- Prometheus server
- Push Gateway
- Alert Manager
Prometheus server is responsible for scraping and storing the data
Push gateway is used for short-lived jobs
Alert manager is responsible for alerts ;)
What is an Instance? What is a Job?
What core metrics types Prometheus supports?
What is an exporter? What is it used for?
Which Prometheus best practices are you familiar with?. Name at least three
How to get total requests in a given period of time?
What HA in Prometheus means?
How do you join two metrics?
How to write a query that returns the value of a label?
How do you convert cpu_user_seconds to cpu usage in percentage?
Git
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| My first Commit | Commit | Exercise | Solution | |
| Time to Branch | Branch | Exercise | Solution |
How do you know if a certain directory is a git repository?
You can check if there is a ".git" directory inside it.
How to check if a file is tracked and if not, then track it?
What is the difference between git pull and git fetch?
Shortly, git pull = git fetch + git merge
When you run git pull, it gets all the changes from the remote or central repository and attaches it to your corresponding branch in your local repository.
git fetch gets all the changes from the remote repository, stores the changes in a separate branch in your local repository
Explain the following: git directory, working directory and staging area
The Git directory is where Git stores the meta data and object database for your project. This is the most important part of Git, and it is what is copied when you clone a repository from another computer.
The working directory is a single checkout of one version of the project. These files are pulled out of the compressed database in the Git directory and placed on disk for you to use or modify.
The staging area is a simple file, generally contained in your Git directory, that stores information about what will go into your next commit. It’s sometimes referred to as the index, but it’s becoming standard to refer to it as the staging area.
This answer taken from git-scm.com
How to resolve git merge conflicts?
First, you open the files which are in conflict and identify what are the conflicts. Next, based on what is accepted in your company or team, you either discuss with your colleagues on the conflicts or resolve them by yourself After resolving the conflicts, you add the files with `git add ` Finally, you run `git rebase --continue`
What is the difference between git reset and git revert?
git revert creates a new commit which undoes the changes from last commit.
git reset depends on the usage, can modify the index or change the commit which the branch head
is currently pointing at.
You would like to move forth commit to the top. How would you achieve that?
Using the git rebase command
In what situations are you using git rebase?
What merge strategies are you familiar with?
Mentioning two or three should be enough and it's probably good to mention that 'recursive' is the default one.
recursive resolve ours theirs
This page explains it the best: https://git-scm.com/docs/merge-strategies
How can you see which changes have done before committing them?
`git diff```
How do you revert a specific file to previous commit?
git checkout HEAD~1 -- /path/of/the/file
How to squash last two commits?
What is the .git directory? What can you find there?
The
.git folder contains all the information that is necessary for your project in version control and all the information about commits, remote repository address, etc. All of them are present in this folder. It also contains a log that stores your commit history so that you can roll back to history.
This info copied from https://stackoverflow.com/questions/29217859/what-is-the-git-folder
What are some Git anti-patterns? Things that you shouldn't do
- Not waiting too long between commits
- Not removing the .git directory :)
How do you remove a remote branch?
You delete a remote branch with this syntax:
git push origin :[branch_name]
Are you familiar with gitattributes? When would you use it?
gitattributes allow you to define attributes per pathname or path pattern.
You can use it for example to control endlines in files. In Windows and Unix based systems, you have different characters for new lines (\r\n and \n accordingly). So using gitattributes we can align it for both Windows and Unix with * text=auto in .gitattributes for anyone working with git. This is way, if you use the Git project in Windows you'll get \r\n and if you are using Unix or Linux, you'll get \n.
How do you discard local file changes? (before commit)
git checkout -- <file_name>
How do you discard local commits?
git reset HEAD~1 for removing last commit
If you would like to also discard the changes you `git reset --hard``
True or False? To remove a file from git but not from the filesystem, one should use git rm
False. If you would like to keep a file on your filesystem, use git reset <file_name>
Explain Git octopus merge
Probably good to mention that it's:
- It's good for cases of merging more than one branch (and also the default of such use cases)
- It's primarily meant for bundling topic branches together
This is a great article about Octopus merge: http://www.freblogg.com/2016/12/git-octopus-merge.html
Go
What are some characteristics of the Go programming language?
- Strong and static typing - the type of the variables can't be changed over time and they have to be defined at compile time
- Simplicity
- Fast compile times
- Built-in concurrency
- Garbage collected
- Platform independent
- Compile to standalone binary - anything you need to run your app will be compiled into one binary. Very useful for version management in run-time.
Go also has good community.
What is the difference between var x int = 2 and x := 2?
The result is the same, a variable with the value 2.
With var x int = 2 we are setting the variable type to integer while with x := 2 we are letting Go figure out by itself the type.
True or False? In Go we can redeclare variables and once declared we must use it.
False. We can't redeclare variables but yes, we must used declared variables.
What libraries of Go have you used?
This should be answered based on your usage but some examples are:
- fmt - formatted I/O
What is the problem with the following block of code? How to fix it?
func main() {
var x float32 = 13.5
var y int
y = x
}
func main() {
var x float32 = 13.5
var y int
y = x
}
The following block of code tries to convert the integer 101 to a string but instead we get "e". Why is that? How to fix it?
package main
import "fmt"
func main() {
var x int = 101
var y string
y = string(x)
fmt.Println(y)
}
package main
import "fmt"
func main() {
var x int = 101
var y string
y = string(x)
fmt.Println(y)
}
It looks what unicode value is set at 101 and uses it for converting the integer to a string.
If you want to get "101" you should use the package "strconv" and replace y = string(x) with y = strconv.Itoa(x)
What is wrong with the following code?:
package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
Constants in Go can only be declared using constant expressions.
But x, y and their sum is variable.
const initializer x + y is not a constant
What will be the output of the following block of code?:
package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main() {
fmt.Printf("%v\n", x)
fmt.Printf("%v\n", y)
fmt.Printf("%v\n", z)
}
package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main() {
fmt.Printf("%v\n", x)
fmt.Printf("%v\n", y)
fmt.Printf("%v\n", z)
}
Go's iota identifier is used in const declarations to simplify definitions of incrementing numbers. Because it can be used in expressions, it provides a generality beyond that of simple enumerations.
x and y in the first iota group, z in the second.
Iota page in Go Wiki
What _ is used for in Go?
It avoids having to declare all the variables for the returns values.
It is called the blank identifier.
answer in SO
What will be the output of the following block of code?:
package main
import "fmt"
const (
_ = iota + 3
x
)
func main() {
fmt.Printf("%v\n", x)
}
package main
import "fmt"
const (
_ = iota + 3
x
)
func main() {
fmt.Printf("%v\n", x)
}
Since the first iota is declared with the value 3 ( + 3), the next one has the value 4
What will be the output of the following block of code?:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
time.Sleep(time.Second * 2)
fmt.Println("1")
wg.Done()
}()
go func() {
fmt.Println("2")
}()
wg.Wait()
fmt.Println("3")
}
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
time.Sleep(time.Second * 2)
fmt.Println("1")
wg.Done()
}()
go func() {
fmt.Println("2")
}()
wg.Wait()
fmt.Println("3")
}
Output: 2 1 3
What will be the output of the following block of code?:
package main
import (
"fmt"
)
func mod1(a []int) {
for i := range a {
a[i] = 5
}
fmt.Println("1:", a)
}
func mod2(a []int) {
a = append(a, 125) // !
for i := range a {
a[i] = 5
}
fmt.Println("2:", a)
}
func main() {
sl := []int{1, 2, 3, 4}
mod1(s1)
fmt.Println("1:", s1)
s2 := []int{1, 2, 3, 4}
mod2(s2)
fmt.Println("2:", s2)
}
package main
import (
"fmt"
)
func mod1(a []int) {
for i := range a {
a[i] = 5
}
fmt.Println("1:", a)
}
func mod2(a []int) {
a = append(a, 125) // !
for i := range a {
a[i] = 5
}
fmt.Println("2:", a)
}
func main() {
sl := []int{1, 2, 3, 4}
mod1(s1)
fmt.Println("1:", s1)
s2 := []int{1, 2, 3, 4}
mod2(s2)
fmt.Println("2:", s2)
}
Output:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
In mod1 a is link, and when we're using a[i], we're changing s1 value to.
But in mod2, append creats new slice, and we're changing only a value, not s2.
What will be the output of the following block of code?:
package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
func main() {
h := &IntHeap{4, 8, 3, 6}
heap.Init(h)
heap.Push(h, 7)
fmt.Println((*h)[0])
}
package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
func main() {
h := &IntHeap{4, 8, 3, 6}
heap.Init(h)
heap.Push(h, 7)
fmt.Println((*h)[0])
}
Output: 3
Mongo
What are the advantages of MongoDB? Or in other words, why choosing MongoDB and not other implementation of NoSQL?
MongoDB advantages are as followings:
- Schemaless
- Easy to scale-out
- No complex joins
- Structure of a single object is clear
What is the difference between SQL and NoSQL?
The main difference is that SQL databases are structured (data is stored in the form of tables with rows and columns - like an excel spreadsheet table) while NoSQL is unstructured, and the data storage can vary depending on how the NoSQL DB is set up, such as key-value pair, document-oriented, etc.
In what scenarios would you prefer to use NoSQL/Mongo over SQL?
- Heterogeneous data which changes often
- Data consistency and integrity is not top priority
- Best if the database needs to scale rapidly
What is a document? What is a collection?
What is an aggregator?
What is better? Embedded documents or referenced?
Have you performed data retrieval optimizations in Mongo? If not, can you think about ways to optimize a slow data retrieval?
Queries
Explain this query: db.books.find({"name": /abc/})
Explain this query: db.books.find().sort({x:1})
What is the difference between find() and find_one()?
How can you export data from Mongo DB?
- mongoexport
- programming languages
OpenShift
What is OpenShift?
How OpenShift is related to Kubernetes?
True or False? OpenShift is a IaaS (infrastructure as a service) solution
False. OpenShift is a PaaS (platform as a service) solution.
What would be the best way to run and manage multiple OpenShift environments?
Federation
OpenShift Federation
What is OpenShift Federation?
Management and deployment of services and workloads accross multiple independent clusters from a single API
Explain the following in regards to Federation:
- Multi Cluster
- Federated Cluster
- Host Cluster
- Member Cluster
- Multi Cluster - Multiple clusters deployed independently, not being aware of each other
- Federated Cluster - Multiple clusters managed by the OpenShift Federation Control Plane
- Host Cluster - The cluster that runs the Federation Control Plane
- Member Cluster - Cluster that is part of the Federated Cluster and connected to Federation Control Plane
OpenShift Azure
What is "OpenShift on Azure" and "Azure Red Hat OpenShift"?
OpenShift on Aazure (OCP) is installed and managed by the customer itself as opposed to Azure Red Hat OpenShift (ARO) which is a managed service by Red Hat and Microsoft. Also, OCP is purchased from Red Hat and ARO is purchased from Azure.
Storage
What is a storage device? What storage devices are there?
- Hard Disks
- SSD
- USB
- Magnetic Tape
Explain the following:
- Block Storage
- Object Storage
- File Storage
What is Random Seek Time?
The time it takes for a disk to reach the place where the data is located and read a single block/sector.
Bones question: What is the random seek time in SSD and Magnetic Disk? Answer: Magnetic is about 10ms and SSD is somewhere between 0.08 and 0.16ms
Scripts
What do you tend to include in every script you write?
Few example:
- Comments on how to run it and/or what it does
- If a shell script, adding "set -e" since I want the script to exit if a certain command failed
You can have an entirely different answer. It's based only on your experience and preferences.
Today we have tools and technologies like Ansible. Why would someone still use scripting?
- Speed
- Flexibility
- The module we need doesn't exist (perhaps a weak point because most CM technologies allow to use what is known as "shell" module)
- We are delivering the scripts to customers who don't have access to the public network and don't necessarily have Ansible installed on their systems.
Scripts Fundamentals
Explain conditionals and how do you use them
What is a loop? What types of loops are you familiar with?
Demonstrate how to use loops
Writing Scripts
Note: write them in any language you prefer
Write a script which will list the differences between two directories
Write a script to determine whether a host is up or down
EXAMPLE ONE
#!/bin/bash
SERVERIP=<IP Address>
NOTIFYEMAIL=test@example.com
ping -c 3 $SERVERIP > /dev/null 2>&1
if [ $? -ne 0 ]
then
# Use mailer here:
mailx -s "Server $SERVERIP is down" -t "$NOTIFYEMAIL" < /dev/null
fi
Write a script to remove all the empty files in a given directory (also nested directories)
EXAMPLE ONE
#! /bin/bash
for x in *
do
if [ -s $x ]
then
continue
else
rm -rf $x
fi
done
SQL
What does SQL stand for?
Structured Query Language
How is SQL Different from NoSQL
The main difference is that SQL databases are structured (data is stored in the form of tables with rows and columns - like an excel spreadsheet table) while NoSQL is unstructured, and the data storage can vary depending on how the NoSQL DB is set up, such as key-value pair, document-oriented, etc.
What does it mean when a database is ACID compliant?
ACID stands for Atomicity, Consistency, Isolation, Durability. In order to be ACID compliant, the database much meet each of the four criteria
Atomicity - When a change occurs to the database, it should either succeed or fail as a whole.
For example, if you were to update a table, the update should completely execute. If it only partially executes, the update is considered failed as a whole, and will not go through - the DB will revert back to it's original state before the update occurred. It should also be mentioned that Atomicity ensures that each transaction is completed as it's own stand alone "unit" - if any part fails, the whole statement fails.
Consistency - any change made to the database should bring it from one valid state into the next.
For example, if you make a change to the DB, it shouldn't corrupt it. Consistency is upheld by checks and constraints that are pre-defined in the DB. For example, if you tried to change a value from a string to an int when the column should be of datatype string, a consistent DB would not allow this transaction to go through, and the action would not be executed
Isolation - this ensures that a database will never be seen "mid-update" - as multiple transactions are running at the same time, it should still leave the DB in the same state as if the transactions were being run sequentially.
For example, let's say that 20 other people were making changes to the database at the same time. At the time you executed your query, 15 of the 20 changes had gone through, but 5 were still in progress. You should only see the 15 changes that had completed - you wouldn't see the database mid-update as the change goes through.
Durability - Once a change is committed, it will remain committed regardless of what happens (power failure, system crash, etc.). This means that all completed transactions must be recorded in non-volatile memory.
Note that SQL is by nature ACID compliant. Certain NoSQL DB's can be ACID compliant depending on how they operate, but as a general rule of thumb, NoSQL DB's are not considered ACID compliant
When is it best to use SQL? NoSQL?
SQL - Best used when data integrity is crucial. SQL is typically implemented with many businesses and areas within the finance field due to it's ACID compliance.
NoSQL - Great if you need to scale things quickly. NoSQL was designed with web applications in mind, so it works great if you need to quickly spread the same information around to multiple servers
Additionally, since NoSQL does not adhere to the strict table with columns and rows structure that Relational Databases require, you can store different data types together.
What is a Cartesian Product?
A Cartesian product is when all rows from the first table are joined to all rows in the second table. This can be done implicitly by not defining a key to join, or explicitly by calling a CROSS JOIN on two tables, such as below:
Select * from customers CROSS JOIN orders;
Note that a Cartesian product can also be a bad thing - when performing a join on two tables in which both do not have unique keys, this could cause the returned information to be incorrect.
SQL Specific Questions
For these questions, we will be using the Customers and Orders tables shown below:
Customers
| Customer_ID | Customer_Name | Items_in_cart | Cash_spent_to_Date |
|---|---|---|---|
| 100204 | John Smith | 0 | 20.00 |
| 100205 | Jane Smith | 3 | 40.00 |
| 100206 | Bobby Frank | 1 | 100.20 |
ORDERS
| Customer_ID | Order_ID | Item | Price | Date_sold |
|---|---|---|---|---|
| 100206 | A123 | Rubber Ducky | 2.20 | 2019-09-18 |
| 100206 | A123 | Bubble Bath | 8.00 | 2019-09-18 |
| 100206 | Q987 | 80-Pack TP | 90.00 | 2019-09-20 |
| 100205 | Z001 | Cat Food - Tuna Fish | 10.00 | 2019-08-05 |
| 100205 | Z001 | Cat Food - Chicken | 10.00 | 2019-08-05 |
| 100205 | Z001 | Cat Food - Beef | 10.00 | 2019-08-05 |
| 100205 | Z001 | Cat Food - Kitty quesadilla | 10.00 | 2019-08-05 |
| 100204 | X202 | Coffee | 20.00 | 2019-04-29 |
How would I select all fields from this table?
Select *
From Customers;
How many items are in John's cart?
Select Items_in_cart
From Customers
Where Customer_Name = "John Smith";
What is the sum of all the cash spent across all customers?
Select SUM(Cash_spent_to_Date) as SUM_CASH
From Customers;
How many people have items in their cart?
Select count(1) as Number_of_People_w_items
From Customers
where Items_in_cart > 0;
How would you join the customer table to the order table?
You would join them on the unique key. In this case, the unique key is Customer_ID in both the Customers table and Orders table
How would you show which customer ordered which items?
Select c.Customer_Name, o.Item
From Customers c
Left Join Orders o
On c.Customer_ID = o.Customer_ID;
Using a with statement, how would you show who ordered cat food, and the total amount of money spent?
with cat_food as (
Select Customer_ID, SUM(Price) as TOTAL_PRICE
From Orders
Where Item like "%Cat Food%"
Group by Customer_ID
)
Select Customer_name, TOTAL_PRICE
From Customers c
Inner JOIN cat_food f
ON c.Customer_ID = f.Customer_ID
where c.Customer_ID in (Select Customer_ID from cat_food);
Although this was a simple statement, the "with" clause really shines when a complex query needs to be run on a table before joining to another. With statements are nice, because you create a pseudo temp when running your query, instead of creating a whole new table.
The Sum of all the purchases of cat food weren't readily available, so we used a with statement to create the pseudo table to retrieve the sum of the prices spent by each customer, then join the table normally.
Azure
Explain Azure's architecture
Explain availability sets and availability zones
An availability set is a logical grouping of VMs that allows Azure to understand how your application is built to provide redundancy and availability. It is recommended that two or more VMs are created within an availability set to provide for a highly available application and to meet the 99.95% Azure SLA.
What is Azure Policy?
What is the Azure Resource Manager? Can you describe the format for ARM templates?
Explain Azure managed disks
Azure Network
What's an Azure region?
What is the N-tier architecture?
Azure Storage
What storage options Azure supports?
Azure Security
What is the Azure Security Center? What are some of its features?
It's a monitoring service that provides threat protection across all of the services in Azure. More specifically, it:
- Provides security recommendations based on your usage
- Monitors security settings and continuously all the services
- Analyzes and identifies potential inbound attacks
- Detects and blocks malware using machine learning
What is Azure Active Directory?
Azure AD is a cloud-based identity service. You can use it as a standalone service or integrate it with existing Active Directory service you already running.
What is Azure Advanced Threat Protection?
What components are part of Azure ATP?
Where logs are stored in Azure Monitor?
Explain Azure Site Recovery
Explain what the advisor does
Explain VNet peering
Which protocols are available for configuring health probe
Explain Azure Active
What is a subscription? What types of subscriptions are there?
Explain what is a blob storage service
GCP
Explain GCP's architecture
What are the main components and services of GCP?
What GCP management tools are you familiar with?
Tell me what do you know about GCP networking
Explain Cloud Functions
What is Cloud Datastore?
What network tags are used for?
What are flow logs? Where are they enabled?
How do you list buckets?
What Compute metadata key allows you to run code at startup?
startap-script
What the following commands does? `gcloud deployment-manager deployments create`
What is Cloud Code?
It is a set of tools to help developers write, run and debug GCP kubernetes based applications. It provides built-in support for rapid iteration, debugging and running applications in development and production K8s environments.
Google Kubernetes Engine (GKE)
What is GKE
- It is the managed kubernetes service on GCP for deploying, managing and scaling containerised applications using Google infrastructure.
Anthos
What is Anthos
It is a managed application platform for organisations like enterprises that require quick modernisation and certain levels of consistency for their legacy applications in a hybrid or multicloud world. From this explanation the core ideas can be drawn from these statements;
- Managed -> the customer does not need to worry about the underlying software intergrations, they just enable the API.
- application platform -> It consists of open source tools like K8s, Knative, Istio and Tekton
- Enterprises -> these are usually organisations with complex needs
- Consistency -> to have the same policies declaratively initiated to be run anywhere securely e.g on-prem, GCP or other-clouds (AWS or Azure)
fun fact: Anthos is flower in greek, they grow in the ground (earth) but need rain from the clouds to flourish.
List the technical components that make up Anthos
- Infrastructure management - Google Kubernetes Engine (GKE)
- Cluster management - GKE, Ingress for Anthos
- Service management - Anthos Service Mesh
- Policy enforcement - Anthos Config Management, Anthos Enterprise Data Protection, Policy Controller
- Application deployment - CI/CD tools like Cloud Build, GitLab
- Application development - Cloud Code
What is the primary computing environment for Anthos to easily manage workload deployment?
- Google Kubernetes Engine (GKE)
How does Anthos handle the control plane and node components for GKE?
On GCP the kubernetes api-server is the only control plane component exposed to customers whilst compute engine manages instances in the project.
Which load balancing options are available?
- Networking load balancing for L4 and HTTP(S) Load Balancing for L7 which are both managed services that do not require additional configuration.
- Ingress for Anthos which allows the ability to deploy a load balancer that serves an application across multiple clusters on GKE
List and explain the enterprise security capabilities provided by Anthos
- Control plane security - GCP manages and maintains the K8s control plane out of the box. The user can secure the api-server by using master authorized networks and private clusters. These allow the user to disable access on the public IP address by assigning a private IP address to the master.
- Node security - By default workloads are provisioned on Compute engine instances that use Google's Container Optimised OS. This operating system implements a locked-down firewall, limited user accounts with root disabled and a read-only filesystem. There is a further option to enable GKE Sandbox for stronger isolation in multi-tenant deployment scenarios.
- Network security - Within a created cluster VPC, Anthos GKE leverages a powerful software-defined network that enables simple Pod-to-Pod communications. Network policies allow locking down ingress and egress connections in a given namespace. Filtering can also be implemented to incoming load-balanced traffic for services that require external access, by supplying whitelisted CIDR IP ranges.
- Workload security - Running workloads run with limited privileges, default Docker AppArmor security policies are applied to all Kubernetes Pods. Workload identity for Anthos GKE aligns with the open source kubernetes service accounts with GCP service account permissions.
- Audit logging - Adminstrators are given a way to retain, query, process and alert on events of the deployed environments.
How can workloads deployed on Anthos GKE on-prem clusters securely connect to Google Cloud services?
- Google Cloud Virtual Private Network (Cloud VPN) - this is for secure networking
- Google Cloud Key Management Service (Cloud KMS) - for key management
What is Island Mode configuration with regards to networking in Anthos GKE deployed on-prem?
- This is when pods can directly talk to each other within a cluster, but cannot be reached from outside the cluster thus forming an "island" within the network that is not connected to the external network.
Explain Anthos Config Management
It is a core component of the Anthos stack which provides platform, service and security operators with a single, unified approach to multi-cluster management that spans both on-premises and cloud environments. It closely follows K8s best practices, favoring declarative approaches over imperative operations, and actively monitors cluster state and applies the desired state as defined in Git. It includes three key components as follows:
- An importer that reads from a central Git repository
- A component that synchronises stored configuration data into K8s objects
- A component that monitors drift between desired and actual cluster configurations with a capability of reconciliation when need rises.
How does Anthos Config Management help?
It follows common modern software development practices which makes cluster configuration, management and policy changes auditable, revertable, and versionable easily enforcing IT governance and unifying resource management in an organisation.
What is Anthos Service Mesh?
- It is a suite of tools that assist in monitoring and managing deployed services on Anthos of all shapes and sizes whether running in cloud, hybrid or multi-cloud environments. It leverages the APIs and core components from Istio, a highly configurable and open-source service mesh platform.
Describe the two main components of Anthos Service Mesh
- Data plane - it consists of a set of distributed proxies that mediate all inbound and outbound network traffic between individual services which are configured using a centralised control plane and an open API
- Control plane - is a fully managed offering outside of Anthos GKE clusters to simplify management overhead and ensure highest possible availability.
What are the components of the managed control plane of Anthos Service Mesh?
- Traffic Director - it is GCP's fully managed service mesh traffic control plane, responsible for translating Istio API objects into configuration information for the distributed proxies, as well as directing service mesh ingress and egress traffic
- Managed CA - is a centralised certificate authority responsible for providing SSL certificates to each of the distributed proxies, authentication information and distributing secrets
- Operations tooling - formerly stackdriver, provides a managed ingestion point for observability and telemetry, specifically monitoring, tracing and logging data generated by each of the proxies. This powers the observability dashboard for operators to visually inspect their services and service dependencies assisting in the implementation of SRE best practices for monitoring SLIs and establishing SLOs.
How does Anthos Service Mesh help?
Tool and technology integration that makes up Anthos service mesh delivers signficant operational benefits to Anthos environments, with minimal additional overhead such as follows:
- Uniform observability - the data plane reports service to service communication back to the control plane generating a service dependency graph. Traffic inspection by the proxy inserts headers to facilitate distributed tracing, capturing and reporting service logs together with service-level metrics (i.e latency, errors, availability).
- Operational agility - fine-grained controls for managing the flow of inter-mesh (north-south) and intra-mesh (east-west) traffic are provided.
- Policy-driven security - policies can be enforced consistently across diverse protocols and runtimes as service communications are secured by default.
List possible use cases of traffic controls that can be implemented within Anthos Service Mesh
- Traffic splitting across differing service versions for canary or A/B testing
- Circuit breaking to prevent cascading failures
- Fault injection to help build resilient and fault-tolerant deployments
- HTTP header-based traffic steering between individual services or versions
What is Cloud Run for Anthos?
It is part of the Anthos stack that brings a serverless container experience to Anthos, offering a high-level platform experience on top of K8s clusters. It is built with Knative, an open-source operator for K8s that brings serverless application serving and eventing capabilities.
How does Cloud Run for Anthos simplify operations?
Platform teams in organisations that wish to offer developers additional tools to test, deploy and run applications can use Knative to enhance this experience on Anthos as Cloud Run. Below are some of the benefits;
- Easy migration from K8s deployments - Without Cloud Run, platform engineers have to configure deployment, service, and HorizontalPodAutoscalers(HPA) objects to a loadbalancer and autoscaling. If application is already serving traffic it becomes hard to change configurations or roll back efficiently. Using Cloud Run all this is managed thus the Knative service manifest describes the application to be autoscaled and loadbalanced
- Autoscaling - a sudden traffic spike may cause application containers in K8s to crash due to overload thus an efficient automated autoscaling is executed to serve the high volume of traffic
- Networking - it has built-in load balancing capabilities and policies for traffic splitting between multiple versions of an application.
- Releases and rollouts - supports the notion of the Knatibe API's revisions which describe new versions or different configurations of your application and canary deployments by splitting traffic.
- Monitoring - observing and recording metrics such as latency, error rate and requests per second.
List and explain three high-level out of the box autoscaling primitives offered by Cloud Run for Anthos that do not exist in K8s natively
- Rapid, request-based autoscaling - default autoscalers monitor request metrics which allows Cloud Run for Anthos to handle spiky traffic patterns smoothly
- Concurrency controls - limits such as max in-flight requests per container are enforced to ensure the container does not become overloaded and crash. More containers are added to handle the spiky traffic, buffering the requests.
- Scale to zero - if an application is inactive for a while Cloud Run scales it down to zero to reduce its footprint. Alternatively one can turn off scale-to-zero to prevent cold starts.
List some Cloud Run for Anthos use cases
As it does not support stateful applications or sticky sessions, it is suitable for running stateless applications such as:
- Machine learning model predictions e.g Tensorflow serving containers
- API gateways, API middleware, web front ends and Microservices
- Event handlers, ETL
OpenStack
What components/projects of OpenStack are you familiar with?
Can you tell me what each of the following services/projects is responsible for?:
-
Nova
-
Neutron
-
Cinder
-
Glance
-
Keystone
Nova
Neutron
Cinder
Glance
Keystone
Nova - Manage virtual instances
Cinder - Block Storage
Keystone - Authentication service across the cloud
Identify the service/project used for each of the following:
- Copy or snapshot instances
- GUI for viewing and modifying resources
- Block Storage
- Manage virtual instances
- Glance - Images Service. Also used for copying or snapshot instances
- Horizon - GUI for viewing and modifying resources
- Cinder - Block Storage
- Nova - Manage virtual instances
What is a tenant/project?
Determine true or false:
- OpenStack is free to use
- The service responsible for networking is Glance
- The purpose of tenant/project is to share resources between different projects and users of OpenStack
Describe in detail how you bring up an instance with a floating IP
You get a call from a customer saying: "I can ping my instance but can't connect (ssh) it". What might be the problem?
What types of networks OpenStack supports?
How do you debug OpenStack storage issues? (tools, logs, ...)
How do you debug OpenStack compute issues? (tools, logs, ...)
OpenStack Deployment & TripleO
Have you deployed OpenStack in the past? If yes, can you describe how you did it?
Are you familiar with TripleO? How is it different from Devstack or Packstack?
You can read about TripleO right here
OpenStack Compute
Can you describe Nova in detail?
- Used to provision and manage virtual instances
- It supports Multi-Tenancy in different levels - logging, end-user control, auditing, etc.
- Highly scalable
- Authentication can be done using internal system or LDAP
- Supports multiple types of block storage
- Tries to be hardware and hypervisor agnostice
What do you know about Nova architecture and components?
- nova-api - the server which serves metadata and compute APIs
- the different Nova components communicate by using a queue (Rabbitmq usually) and a database
- a request for creating an instance is inspected by nova-scheduler which determines where the instance will be created and running
- nova-compute is the component responsible for communicating with the hypervisor for creating the instance and manage its lifecycle
OpenStack Networking (Neutron)
Explain Neutron in detail
- One of the core component of OpenStack and a standalone project
- Neutron focused on delivering networking as a service
- With Neutron, users can set up networks in the cloud and configure and manage a variety of network services
- Neutron interacts with:
- Keystone - authorize API calls
- Nova - nova communicates with neutron to plug NICs into a network
- Horizon - supports networking entities in the dashboard and also provides topology view which includes networking details
Explain each of the following components:
-
neutron-dhcp-agent
-
neutron-l3-agent
-
neutron-metering-agent
-
neutron-*-agtent
-
neutron-server
neutron-dhcp-agent
neutron-l3-agent
neutron-metering-agent
neutron-*-agtent
neutron-server
neutron-l3-agent - L3/NAT forwarding (provides external network access for VMs for example)
neutron-dhcp-agent - DHCP services
neutron-metering-agent - L3 traffic metering
neutron-*-agtent - manages local vSwitch configuration on each compute (based on chosen plugin)
neutron-server - exposes networking API and passes requests to other plugins if required
Explain these network types:
-
Management Network
-
Guest Network
-
API Network
-
External Network
Management Network
Guest Network
API Network
External Network
Management Network - used for internal communication between OpenStack components. Any IP address in this network is accessible only within the datacetner
Guest Network - used for communication between instances/VMs
API Network - used for services API communication. Any IP address in this network is publicly accessible
External Network - used for public communication. Any IP address in this network is accessible by anyone on the internet
What is a provider network?
What components and services exist for L2 and L3?
What is the ML2 plug-in? Explain its architecture
What is the L2 agent? How does it works and what is it responsible for?
What is the L3 agent? How does it works and what is it responsible for?
Explain what the Metadata agent is responsible for
What networking entities Neutron supports?
How do you debug OpenStack networking issues? (tools, logs, ...)
OpenStack - Glance
Explain Glance in detail
- Glance is the OpenStack image service
- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
- glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly
- glance-registry - responsible for handling image metadata requests (e.g. size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
- Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data
- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
-
Container
-
Account
-
Object
Container
Account
Object
Container - Defines a namespace for objects.
Account - Defines a namespace for containers
Object - Data content (e.g. image, document, ...)
True or False? there can be two objects with the same name in the same container but not in two different containers
False. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
- Cinder is OpenStack Block Storage service
- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
- cinder-api - receives API requests
- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?
-
Role
-
Tenant/Project
-
Service
-
Endpoint
-
Token
Role
Tenant/Project
Service
Endpoint
Token
Role - A list of rights and privileges determining what a user or a project can perform
Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
Service - An endpoint which the user can use for accessing different resources
Endpoint - a network address which can be used to access a certain OpenStack service
Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
Using:
- Name
- ID number
- Type
- Description
Explain the following: * PublicURL * InternalURL * AdminURL
- PublicURL - Publicly accessible through public internet
- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services
-
Swift
-
Sahara
-
Ironic
-
Trove
-
Aodh
-
Ceilometer
Swift
Sahara
Ironic
Trove
Aodh
Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store
Sahara - Manage Hadoop Clusters
Ironic - Bare Metal Provisioning
Trove - Database as a service that runs on OpenStack
Aodh - Alarms Service
Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:
-
Database as a service which runs on OpenStack
-
Bare Metal Provisioning
-
Track and monitor usage
-
Alarms Service
-
Manage Hadoop Clusters
-
highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack
Bare Metal Provisioning
Track and monitor usage
Alarms Service
Manage Hadoop Clusters
highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove
Bare Metal Provisioning - Ironic
Track and monitor usage - Ceilometer
Alarms Service - Aodh
Manage Hadoop Clusters
Manage Hadoop Clusters - Sahara
highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
- You can't have OpenStack deployed without Keystone
- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
- There is a service API and admin API through which Keystone gets requests
- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- LDAP
- KVS (Key Value Store)
- SQL
- PAM
- Memcached
Describe the Keystone authentication process
- Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL
- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:
-
nova-api
-
nova-compuate
-
nova-conductor
-
nova-cert
-
nova-consoleauth
-
nova-scheduler
nova-api
nova-compuate
nova-conductor
nova-cert
nova-consoleauth
nova-scheduler
nova-api - responsible for managing requests/calls
nova-compute - responsible for managing instance lifecycle
nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
- Nova-novncproxy - Access through VNC connections
- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
- Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards
- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
- API is backward compatible
- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
Security
What is DevSecOps? What its core principals?
What security techniques are you familiar with? (or what security techniques have you used in the past?)
What the "Zero Trust" concept means? How Organizations deal with it?
Codefresh definition: "Zero trust is a security concept that is centered around the idea that organizations should never trust anyone or anything that does not originate from their domains. Organizations seeking zero trust automatically assume that any external services it commissions have security breaches and may leak sensitive information"
Explain Authentication and Authorization
Authentication is the process of identifying whether a service or a person is who they claim to be. Authorization is the process of identifying what level of access the service or the person have (after authentication was done)
How do you manage sensitive information (like passwords) in different tools and platforms?
Explain what is Single Sign-On
SSO (Single Sign-on), is a method of access control that enables a user to log in once and gain access to the resources of multiple software systems without being prompted to log in again.
Explain MFA (Multi-Factor Authentication)
Multi-Factor Authentication (Also known as 2FA). Allows the user to present two pieces of evidence, credentials, when logging into an account.
- The credentials fall into any of these three categories: something you know (like a password or PIN), something you have (like a smart card), or something you are (like your fingerprint). Credentials must come from two different categories to enhance security.
Explain RBAC (Role-based Access Control)
Access control based on user roles (i.e., a collection of access authorizations a user receives based on an explicit or implicit assumption of a given role). Role permissions may be inherited through a role hierarchy and typically reflect the permissions needed to perform defined functions within an organization. A given role may apply to a single individual or to several individuals.
- RBAC mapped to job function, assumes that a person will take on different roles, overtime, within an organization and different responsibilities in relation to IT systems.
Security - Web
What is Nonce?
Security - SSH
What is SSH how does it work?
Wikipedia Definition: "SSH or Secure Shell is a cryptographic network protocol for operating network services securely over an unsecured network."
Hostinger.com Definition: "SSH, or Secure Shell, is a remote administration protocol that allows users to control and modify their remote servers over the Internet."
This site explains it in a good way.
What is the role of an SSH key?
Security Cryptography
Explain Symmetrical encryption
A symmetric encryption is any technique where a key is used to both encrypt and decrypt the data/entire communication.
Explain Asymmetrical encryption
A asymmetric encryption is any technique where the there is two different keys that are used for encryption and decryption, these keys are known as public key and private key.
What is "Key Exchange" (or "key establishment") in cryptography?
Wikipedia: "Key exchange (also key establishment) is a method in cryptography by which cryptographic keys are exchanged between two parties, allowing use of a cryptographic algorithm."
True or False? The symmetrical encryption is making use of public and private keys where the private key is used to decrypt the data encrypted with a public key
False. This description fits the asymmetrical encryption.
True or False? The private key can be mathematically computed from a public key
False.
True or False? In the case of SSH, asymmetrical encryption is not used to the entire SSH session
True. It is only used during the key exchange algorithm of symmetric encryption.
What is Hashing?
How hashes are part of SSH?
Hashes used in SSH to verify the authenticity of messages and to verify that nothing tampered with the data received.
Explain the following:
- Vulnerability
- Exploits
- Risk
- Threat
What is XSS?
Cross Site Scripting (XSS) is an type of a attack when the attacker inserts browser executable code within a HTTP response. Now the injected attack is not stored in the web application, it will only affact the users who open the maliciously crafted link or third-party web page. A successful attack allows the attacker to access any cookies, session tokens, or other sensitive information retained by the browser and used with that site
You can test by detecting user-defined variables and how to input them. This includes hidden or non-obvious inputs such as HTTP parameters, POST data, hidden form field values, and predefined radio or selection values. You then analyze each found vector to see if their are potential vulnerabilities, then when found you craft input data with each input vector. Then you test the crafted input and see if it works.
What is an SQL injection? How to manage it?
SQL injection is an attack consists of inserts either a partial or full SQL query through data input from the browser to the web application. When a successful SQL injection happens it will allow the attacker to read sensitive information stored on the database for the web application.
You can test by using a stored procedure, so the application must be sanitize the user input to get rid of the tisk of code injection. If not then the user could enter bad SQL, that will then be executed within the procedure
What is Certification Authority?
How do you identify and manage vulnerabilities?
Explain "Privilege Restriction"
How HTTPS is different from HTTP?
What types of firewalls are there?
What is DDoS attack? How do you deal with it?
What is port scanning? When is it used?
What is the difference between asynchronous and synchronous encryption?
Explain Man-in-the-middle attack
Explain CVE and CVSS
What is ARP Poisoning?
Describe how do you secure public repositories
How do cookies work?
What is DNS Spoofing? How to prevent it?
DNS spoofing occurs when a particular DNS server’s records of “spoofed” or altered maliciously to redirect traffic to the attacker. This redirection of traffic allows the attacker to spread malware, steal data, etc.
Prevention
- Use encrypted data transfer protocols - Using end-to-end encryption vian SSL/TLS will help decrease the chance that a website / its visitors are compromised by DNS spoofing.
- Use DNSSEC - DNSSEC, or Domain Name System Security Extensions, uses digitally signed DNS records to help determine data authenticity.
- Implement DNS spoofing detection mechanisms - it’s important to implement DNS spoofing detection software. Products such as XArp help product against ARP cache poisoning by inspecting the data that comes through before transmitting it.
What can you tell me about Stuxnet?
Stuxnet is a computer worm that was originally aimed at Iran’s nuclear facilities and has since mutated and spread to other industrial and energy-producing facilities. The original Stuxnet malware attack targeted the programmable logic controllers (PLCs) used to automate machine processes. It generated a flurry of media attention after it was discovered in 2010 because it was the first known virus to be capable of crippling hardware and because it appeared to have been created by the U.S. National Security Agency, the CIA, and Israeli intelligence.
What can you tell me about the BootHole vulnerability?
What can you tell me about Spectre?
Spectre is an attack method which allows a hacker to “read over the shoulder” of a program it does not have access to. Using code, the hacker forces the program to pull up its encryption key allowing full access to the program
Explain OAuth
Explain "Format String Vulnerability"
Explain DMZ
Explain TLS
What is CSRF? How to handle CSRF?
Cross-Site Request Forgery (CSRF) is an attack that makes the end user to initate a unwanted action on the web application in which the user has a authenticated session, the attacker may user an email and force the end user to click on the link and that then execute malicious actions. When an CSRF attack is successful it will compromise the end user data
You can use OWASP ZAP to analyze a "request", and if it appears that there no protection against cross-site request forgery when the Security Level is set to 0 (the value of csrf-token is SecurityIsDisabled.) One can use data from this request to prepare a CSRF attack by using OWASP ZAP
Explain HTTP Header Injection vulnerability
HTTP Header Injection vulnerabilities occur when user input is insecurely included within server responses headers. If an attacker can inject newline characters into the header, then they can inject new HTTP headers and also, by injecting an empty line, break out of the headers into the message body and write arbitrary content into the application's response.
What security sources are you using to keep updated on latest news?
What TCP and UDP vulnerabilities are you familiar with?
Do using VLANs contribute to network security?
What are some examples of security architecture requirements?
What is air-gapped network (or air-gapped environment)? What its advantages and disadvantages?
Explain what is Buffer Overflow
A buffer overflow (or buffer overrun) occurs when the volume of data exceeds the storage capacity of the memory buffer. As a result, the program attempting to write the data to the buffer overwrites adjacent memory locations.
Containers
What security measures are you taking when dealing with containers?
Explain what is Docker Bench
Explain MAC flooding attack
MAC address flooding attack (CAM table flooding attack) is a type of network attack where an attacker connected to a switch port floods the switch interface with very large number of Ethernet frames with different fake source MAC address.
What is port flooding?
What is "Diffie-Hellman key exchange" and how does it work?
Explain "Forward Secrecy"
What is Cache Poisoned Denial of Service?
CPDoS or Cache Poisoned Denial of Service. It poisons the CDN cache. By manipulating certain header requests, the attacker forces the origin server to return a Bad Request error which is stored in the CDN’s cache. Thus, every request that comes after the attack will get an error page.
Security - Threats
Explain "Advanced persistent threat (APT)"
What is a "Backdoor" in information security?
Puppet
What is Puppet? How does it works?
Explain Puppet architecture
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
Explain the following:
- Module
- Manifest
- Node
Explain Facter
What is MCollective?
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
Elastic
What is the Elastic Stack?
The Elastic Stack consists of:
- Elasticsearch
- Kibana
- Logstash
- Beats
- Elastic Hadoop
- APM Server
Elasticserach, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides.
Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
- The data logged by the application is picked by filebeat and sent to logstash
- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
Elasticsearch
What is a data node?
This is where data is stored and also where different processing takes place (e.g. when you search for a data).
What is a master node?
Par of a master node responsibilites:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for parsing the data. In case you don't use logstash then this node can recieve data from beats and parse it, similarly to how it can be parsed in Logstash.
What is Coordinating node?
A Coordinating node responsible for routing requests out and in to the cluser (data nodes).
How data is stored in elasticsearch?
- Data is stored in an index
- The index is spread across the cluster using shards
What is an Index?
Index in Elastic is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (e.g. index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elastic is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a Document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. What does it mean? What can cause the status to be yellow instead of green?
Red means some data is unavailable. Yellow can be caused by running single node cluster instead of multi-node.
True or False? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
False. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
- _index
- _id
- _type
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
- You can optimize fields for partial matching
- You can define custom formats of known fields (e.g. date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index’s shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". What does it mean?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
- If name value was different then it would update "name" to the new value
- In any case, it bumps version field by one
What is the Bulk API? What would you use it for?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (e.g. Reddis or RabbitMQ) and also security component such as Nginx.
Logstash
What are Logstash plugins? What plugins types are there?
- Input Plugins - how to collect data from different sources
- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
Kibana
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". What does it mean?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
True or False? a single harvester harvest multiple files, according to the limits set in filebeat.yml
False. One harvester harvests one file.
What are filebeat modules?
Elastic Stack
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
DNS
What is DNS? What is it used for?
DNS (Domain Name Systems) is a protocol used for converting domain names into IP addresses.
As you know computer networking is done with IP addresses (layer 3 of the OSI model) but for as humans it's hard to remember IP addresses, it's much easier to remember names. This why we need something such as DNS to convert any domain name we type into an IP address. You can think on DNS as a huge phonebook or database where each corresponding name has an IP.
How DNS works?
In general the process is as follows:
- The user types an address in the web browser (some_site.com)
- The operating system gets a request from the browser to translate the address the user entered
- A query created to check a local entry of the address exists in the system. In case it doesn't, the request is forwarded to the DNS resolver
- The Resolver is a server, usually configured by your ISP when you connect to the internet, that responsible for resolving your query by contacting other DNS servers
- The Resolver contacts the root nameserver (aka as .)
- The root nameserver responds with the address of the relevant Top Level Domain DNS server (if your address ends with org then the org TLD)
- The Resolver then contacts the TLD DNS and TLD DNS responds with the IP address that matches the address the user typed in the browser
- The Resolver passes this information to the browser
- The user is happy :D
Explain the resolution sequence of: www.site.com
It's resolved in this order:
- .
- .com
- site.com
- www.site.com
What types of DNS records are there?
- A
- PTR
- MX
- AAAA
What is a A record?
A (Address) Maps a host name to an IP address. When a computer has multiple adapter cards and IP addresses, it should have multiple address records.
What is a AAAA record?
An AAAA Record performs the same function as an A Record, but for an IPv6 Address.
What is a PTR record?
While an A record points a domain name to an IP address, a PTR record does the opposite and resolves the IP address to a domain name.
What is a MX record?
MX (Mail Exchange) Specifies a mail exchange server for the domain, which allows mail to be delivered to the correct mail servers in the domain.
Is DNS using TCP or UDP?
DNS uses UDP port 53 for resolving queries either regular or reverse. DNS uses TCP for zone transfer.
True or False? DNS can be used for load balancing
True.
Which techniques a DNS can use for load balancing?
What is DNS Record TTL? Why do we need it?
What is a zone? What types of zones are there?
Distributed
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
- Network
- CPU
- Memory
- Disk
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
- Availability: Every request receives a response (it doesn't has to be the most recent data)
- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
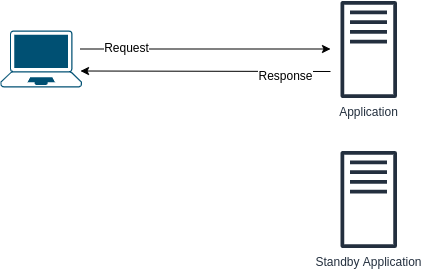

1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing
What are the problems with the following design? How to improve it?
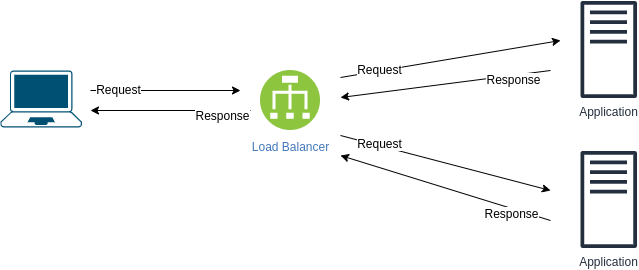

Issues: If load balancer dies , we lose the ability to communicate with the application.
Ways to improve:
- Add another load balancer
- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage, memory, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
Misc
What is a server? What is a client?
A computer which serves data from itself to the client.
Define or Explain what is an API
I like this definition from here:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debuggger and how it works?
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use? Why?
I can't answer this for you :)
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
True or False? Any valid JSON file is also a valid YAML file
True. Because YAML is superset of JSON.
What is the format of the following data?
{
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
{
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON
What is the format of the following data?
applications:
- app: "my_app"
language: "python"
version: 20.17
applications:
- app: "my_app"
language: "python"
version: 20.17
YAML
How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: |
look mama
I can write a multi-line string
I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: >?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: ---
For Examples:
document_number: 1
---
document_number: 2
Jira
Explain/Demonstrate the following types in Jira:
- Epic
- Story
- Task
What is a project in Jira?
Kafka
What is Kafka?
In Kafka, how to automatically balance brokers leadership of partitions in a cluster?
- Enable auto leader election and reduce the imbalance
percentage ratio
- Manually rebalance by using kafkat
- Configure group.initial.rebalance.delay.ms to 3000
- All of the above
Cassandra
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?
- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
Customers and Service Providers
What is SLO (service-level objective)?
What is SLA (service-level agreement)?
HTTP
What is HTTP?
Describe HTTP request lifecycle
- Resolve host by request to DNS resolver
- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP response
True or False? HTTP is stateful
False. It doesn't maintain state for incoming request.
How HTTP request looks like?
It consists of:
- Request line - request type
- Headers - content info like length, enconding, etc.
- Body (not always included)
What HTTP method types are there?
- GET
- POST
- HEAD
- PUT
- DELETE
- CONNECT
- OPTIONS
- TRACE
What HTTP response codes are there?
- 1xx - informational
- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. What does it mean?
The server didn't receive a response from another server it communicates with in a timely manner.
What is a proxy?
What is a reverse proxy?
What is CDN?
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
What benefits load balancers provide?
- Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.
- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
- Round Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
- A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.
- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
What are sticky sessions? What are their pros and cons?
Recommended read:
Cons:
- Can cause uneven load on instance (since requests routed to the same instances) Pros:
- Ensures in-proc sessions are not lost when a new request is created
Explain each of the following load balancing techniques
- Round Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy.
The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
Licenses
Are you familiar with "Creative Commons"? What do you know about it?
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
Random
How a search engine works?
How auto completion works?
What is faster than RAM?
What is a memory leak?
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
HR
These are not DevOps related questions as you probably noticed, but since they are part of the DevOps interview process I've decided it might be good to keep them
Tell us little bit about yourself
Tell me about your last big project/task you worked on
What was most challenging part in the project you worked on?
How did you hear about us?
Tell them how did you hear about them :D Relax, there is no wrong or right answer here...I think.
How would you describe a good leadership? What makes a good boss for you?
Tell me about a time where you didn't agree on an implementation
How do you deal with a situation where key stakeholders are not around and a big decision needs to be made?
Where do you see yourself 5 years down the line?
Give an example of a time when you were able to change the view of a team about a particular tool/project/technology
Have you ever caused a service outage? (or broke a working project, tool, ...?)
If you worked in this area for more than 5 years it's hard to imagine the answer would be no. It also doesn't have to be big service outage. Maybe you merged some code that broke a project or its tests. Simply focus on what you learned from such experience.
Rank the following in order 1 to 5, where 1 is most important: salaray, benefits, career, team/people, work life balance
You know best your order just have a good thought if you really want to put salary in top or bottom....
You have three important tasks scheduled for today. One is for your boss, second for a colleague who is also a friend, third is for a customer. All tasks are equally important. What do you do first?
You have a colleague you don‘t get along with. Tell us some strategies how you create a good work relationship with them anyway.
Bad answer: I don't. Better answer: Every person has strengths and weaknesses. This is true also for colleagues I don't have good work relationship with and this is what helps me to create good work relationship with them. If I am able to highlight or recognize their strengths I'm able to focus mainly on that when communicating with them.
What do you love about your work?
You know the best, but some ideas if you find it hard to express yourself:
- Diversity
- Complexity
- Challenging
- Communication with several different teams
What are your responsibilities in your current position?
You know the best :)
Why should we hire you for the role?
You can use and elaborate on one or all of the following:
- Passion
- Motivation
- Autodidact
- Creativity (be able to support it with some actual examples)
Pointless Questions
Why do you want to work here?
Why are you looking to leave your current place?
What are your strengths and weaknesses?
Where do you see yourself in five years?
Team Lead
How would you improve productivity in your team?
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt.
Phrase the question in the light that all companies have the deal with this, but you want to see the current
pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company.
Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
Testing
Explain white-box testing
Explain black-box testing
What are unit tests?
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:
- Load Testing
- Stress Testing
- Capacity Testing
- Volume Testing
- Endurance Testing
Databases
What is sharding?
Sharding is a horizontal partitioning.
Are you able to explain what is it good for?
You find out your database became a bottleneck and users experience issues accessing data. How can you deal with such situation?
Not much information provided as to why it became a bottleneck and what is current architecture, so one general approach could be
to reduce the load on your database by moving frequently-accessed data to in-memory structure.
What is a connection pool?
Connection Pool is a cache of database connections and the reason it's used is to avoid an overhead of establishing a connection for every query done to a database.
What is a connection leak?
A connection leak is a situation where database connection isn't closed after being created and is no longer needed.
What is Table Lock?
Your database performs slowly than usual. More specifically, your queries are taking a lot of time. What would you do?
- Query for running queries and cancel the irrelevant queries
- Check for connection leaks (query for running connections and include their IP)
- Check for table locks and kill irrelevant locking sessions
What is a Data Warehouse?
"A data warehouse is a subject-oriented, integrated, time-variant and non-volatile collection of data in support of organisation's decision-making process"
Explain what is a time-series database
What is OLTP (Online transaction processing)?
What is OLAP (Online Analytical Processing)?
What is an index in a database?
A database index is a data structure that improves the speed of operations in a table. Indexes can be created using one or more columns, providing the basis for both rapid random lookups and efficient ordering of access to records.
Regex
Given a text file, perform the following exercises
Extract
Extract all the numbers
Extract the first word of each line
Bonus: extract the last word of each line
Extract all the IP addresses
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
Replace
Replace tabs with four spaces
Replace 'red' with 'green'
System Design
Explain what is a "Single point of failure" and give an example
Explain "3-Tier Architecture" (including pros and cons)
What are the drawbacks of monolithic architecture?
- Not suitable for frequent code changes and the ability to deploy new features
- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
What are the advantages of microoservices architecture over a monolithic architecture?
- Each of the services individually fail without escalating into an application-wide outage.
- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
Explain "Loose Coupling"
What is a message queue? When is it used?
Scalability
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvange of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain when in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?


What is the problem with the following architecture and how would you fix it?


The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?


How would you scale the architecture from the previous question to hundreds of users?
Cache
What is "cache"? In which cases would you use it?
What is "distributed cache"?
Why not writing everything to cache instead of a database/datastore?
Migrations
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

Hardware
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
Raspberry Pi
What types of storage are there?
Big Data
Explain what is exactly Big Data
As defined by Doug Laney:
- Volume: Extremely large volumes of data
- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
- Structured - data that has defined format and length (e.g. numbers, words)
- Semi-structured - Doesn't conform to a specific format but is self-describing (e.g. XML, SWIFT)
- Unstructured - does not follow a specific format (e.g. images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
- Distributed file system providing high aggregate bandwidth across the cluster.
- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
- Master-slave architecture
- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
True or False? Ceph favor consistency and correctness over performances
True
Which services or types of storage Ceph supports?
- Object (RGW)
- Block (RBD)
- File (CephFS)
What is RADOS?
- Reliable Autonomic Distributed Object Storage
- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
- Monitor
- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- Manager
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
- Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
What is the workflow of retrieving data from Ceph?
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? How it works?
Packer
What is Packer? What is it used for?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
- Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.
- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
Certificates
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. Good luck :)
AWS
- Cloud Practitioner (Latest update: 2020)
Kubernetes
- Certified Kubernetes Administrator (CKA) (Latest update: 2020)
Other DevOps Projects



Credits
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
License
![]()