13 KiB
APUNTES PYTHON Y CHATGPT

Índice
TEMA 1 - Introducción a ChatGPT y sus aplicaciones
1.1. - ¿Qué es ChatGPT?
ChatGPT es un modelo de lenguaje desarrollado por OpenAI, basado en la arquitectura GPT-3.5. GPT significa Generatice Pre-trained Tranformer (Transformador Generativo Pre-enternado). Es un sistema de procesamiento del lenguaje natural (NLP) capaz de generar respuestas coherentes y contextualmente relevantes a partir de las entradas de texto que recibe. Utiliza el aprendizaje automático y está entrenado en una amplia variedad de datos textuales para comprender y generar texto en lenguaje natural.
1.2. - ¿Cómo funciona?
El funcionamiento de ChatGPT se basa en un enfoque llamado "aprendizaje automático" o "aprendizaje profundo". El modelo GPT-3.5, en el que se basa ChatGPT, es una red neuronal profunda que ha sido entrenada en una enorme cantidad de datos textuales para aprender patrones y características del lenguaje humano.
Cuando se le proporciona una entrada de texto, como una pregunta o una declaración, ChatGPT descompone el texto en unidades más pequeñas, como palabras o tokens. Luego, analiza el contexto de las palabras y utiliza esa información para generar una respuesta relevante. El modelo se entrena para predecir la siguiente palabra o el siguiente token en una secuencia de texto, dada la secuencia anterior.
ChatGPT tiene una estructura en capas. Cada capa procesa y extrae información del texto de entrada de manera gradual y compleja. A medida que la información se mueve a través de las capas, se capturan representaciones cada vez más abstractas y significativas del texto.
Es importante tener en cuenta que ChatGPT se basa en la información con la que ha sido entrenado y no tiene conocimiento directo del mundo real fuera de los datos que se le han proporcionado durante su entrenamiento. Además, aunque ChatGPT puede generar respuestas coherentes y contextuales, también es posible que ocasionalmente genere respuestas incorrectas o no adecuadas, por lo que siempre se debe usar con cautela y verificar la información en caso de duda.
1.3. - Arquitectura
La arquitectura subyacente de ChatGPT se basa en la versión GPT-3.5 de OpenAI, que es una red neuronal de transformador. Un transformador es un tipo de arquitectura de aprendizaje profundo que ha demostrado excelentes resultados en tareas de procesamiento del lenguaje natural.
El transformador consta de múltiples capas de atención y alimentación hacia adelante. Cada capa tiene una estructura similar, que incluye una subcapa de atención multi-cabeza y una red de alimentación hacia adelante.
La subcapa de atención multi-cabeza se encarga de analizar la relación entre las diferentes palabras en la secuencia de entrada. Utiliza múltiples "cabezas de atención" para capturar diferentes aspectos de la dependencia entre palabras. Esto permite que el modelo entienda mejor las relaciones a largo plazo y el contexto en el texto.
La red de alimentación hacia adelante es una capa de redes neuronales completamente conectadas que procesa las representaciones de salida de la capa de atención. Ayuda a capturar relaciones no lineales en el texto y mejorar la calidad de las representaciones de las palabras.
En cuanto al funcionamiento, ChatGPT se entrena utilizando un proceso llamado "aprendizaje autodirigido". Durante el entrenamiento, se proporciona al modelo una gran cantidad de datos textuales de diferentes fuentes, como libros, artículos de noticias, páginas web, conversaciones y más. El modelo aprende a predecir la siguiente palabra en una secuencia de texto, dado el contexto anterior. El entrenamiento tiene dos fases:
- Pre-entrenamiento
- Ajuste fino

1.4. - Casos de uso
- Chatbots y asistentes virtuales. Ejemplo https://my.replika.com/
- Generación de contenido. Ejemplo https://www.shortlyai.com/
- Resumen y parafraseo de textos. Ejemplo https://quillbot.com/
- Análisis de sentimiento.
- Traducción automatica. DeepL utiliza IAs para sus resultados.
TEMA 2 - Configuración y Autenticación con la API de OpenAI
2.1. - Pasos para autenticarse a ChatGPT
- Paso 1 – Registrarse en OpenAI https://platform.openai.com/
- Paso 2 – Obtener las credenciales API https://platform.openai.com/account/api-keys
- Paso 3 – Almacenarlas de forma segura
Para guardar las contraseñas de manera segura nos bajamos la librería python-dotenv:
pip install python-dotenv
Para guardar la API creamos un fichero .env y ponemos una variable en mayúsculas con la API:
OPENAI_API_KEY=sk-x5ejwlcnwvkcvME_ncjkwceLAcnoewejkINVENTOcnwjl
Luego, para llamar la api desde cualquier fichero python tenemos que llamar a la API mediante la librería python-dotenv. Ejemplo miPrograma.py:
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.getenv('OPENAI_API_KEY')
2.2. - Instalar y configurar las bibliotecas para OpenAI
- Paso 1 – Instalar la biblioteca de OpenAI
pip install openai
- Paso 2 – Importarla y configurar la API key
import openai
Ahora vamos a configurar la biblioteca openai con la API
Debajo del código ponemos:
openai.api_key = api_key
- Paso 3 – Verificar la conexión
Nos aseguramos de que está configurada la api llamando a los módelos a la biblioteca:
modelos = openai.Model.list()
Nos devolverá todos los modelos disponibles. Para verlo en consola imprimimos la variable:
print(modelos)
Ejecutando el programa podemos ver todos los modelos, para aislar los nombres se puede usar el comando jq:
python3 code/miPrograma.py | jq '.data[].id'

2.3. - Descripción y documentación de las bibliotecas
os: La librería os proporciona funciones para interactuar con el sistema operativo en Python. Permite realizar tareas relacionadas con el sistema operativo, como acceder a variables de entorno, manipular rutas de archivos y directorios, ejecutar comandos en la línea de comandos, entre otros. Documentación oficial: https://docs.python.org/3/library/os.html
openai: La librería Python de OpenAI, llamada openai, proporciona una interfaz para acceder a modelos de lenguaje avanzados desarrollados por OpenAI, como GPT-3.5. Puedes utilizar la librería openai para generar texto, completar oraciones, responder preguntas, traducir texto, entre otros usos relacionados con el procesamiento del lenguaje natural (NLP). Documentación oficial: https://platform.openai.com/docs/libraries
dotenv: La librería dotenv es una herramienta popular utilizada para cargar variables de entorno desde archivos de configuración en aplicaciones Python. Permite definir variables de entorno en un archivo .env y luego cargar esas variables en el entorno de ejecución de la aplicación. Esto proporciona una forma conveniente de gestionar configuraciones sensibles y separarlas del código fuente. La librería dotenv es ampliamente utilizada en combinación con frameworks como Django o Flask. Documentación oficial: https://pypi.org/project/python-dotenv/
TEMA 3 - Interactuar con ChatGPT usando Python
3.1. - Realizar peticiones básicas a chatgpt
- Paso 1 – Preparar la petición
Vamos a definir el modelo que queremos utilizar y que pregunta queremos hacer. Por ejemplo, vamos a crear una variable con el modelo y en otra variable ponemos la pregunta, que se llama prompt:
modelo = "text-davinci-002"
prompt = "¿Cuál es la capital de Costa Rica?"
- Paso 2 – Enviar la petición
Usaremos la biblioteca openai para almacenar la respuesta:
respuesta = openai.Completion.create(
engine=modelo,
prompt=prompt,
n=1, # Opcional. Número de respuestas a devolver
)
- Paso 3 – Procesar y mostrar la respuesta
Para mostrar la respuesta en consola:
print(respuesta)
Si queremos mostrar solo el texto de la respuesta:
print(respuesta.choices[0].text.strip())
3.2. - Personalización de las peticiones de ChatGPT
3.2.1. - Temperatura (creatividad)
Es un parametro que controla como es de aleatoria la respuesta. Cuanto más alta más diversa será la respuesta, se puede poner valores de 0.1 a 1.
temperature=1
3.2.2. - Tokens máximos (largo)
Controlas el largo de la respuesta contando los tokens máximos:
max_tokens=100
3.2.3. - Cantidad de respuestas
Es con el argumento n que ya habíamos usado, pero necesitaremos un loop for para recorrer las respuestas y mostrarlas:
for idx, opcion in enumerate(respuesta.choices):
texto_generado = opcion.text.strip()
print(f"Respuesta {idx + 1}: {texto_generado}\n")
3.3. - Procesar y analizar las respuestas de chatgpt
3.3.1. - Analizar la respuesta
Vamos a utilizar bibliotecas python para mejorar el procesamiento del lenguaje natural de la respuesta:
-
SpaCy: es una biblioteca de procesamiento del lenguaje natural (NLP) de código abierto y muy eficiente. Proporciona una amplia gama de funcionalidades para el procesamiento de texto, como el análisis morfológico, el etiquetado gramatical, el reconocimiento de entidades nombradas, el análisis de dependencias sintácticas, la lematización y la extracción de frases clave. SpaCy se destaca por su rendimiento rápido y su capacidad para procesar grandes volúmenes de texto de manera eficiente. Documentación: https://spacy.io/usage
-
TextBlob: es una biblioteca de procesamiento del lenguaje natural (NLP) basada en NLTK. Ofrece una interfaz sencilla y fácil de usar para realizar tareas comunes de procesamiento de texto, como análisis de sentimientos, corrección ortográfica, tokenización, extracción de frases, lematización y etiquetado gramatical. TextBlob es conocido por su facilidad de uso y su capacidad para realizar tareas básicas de NLP con pocas líneas de código.* Documentación*: https://textblob.readthedocs.io/en/dev/
-
NLTK (Natural Language Toolkit): es una biblioteca popular y ampliamente utilizada para el procesamiento del lenguaje natural en Python. Ofrece una amplia gama de herramientas y recursos para tareas de procesamiento de texto, como tokenización, etiquetado gramatical, lematización, análisis sintáctico, análisis de sentimientos, clasificación de texto, entre otras. NLTK también proporciona acceso a diversos corpus de texto y modelos pre-entrenados, lo que facilita el desarrollo y la experimentación en el campo del procesamiento del lenguaje natural. Documentación: https://www.nltk.org/
Se instalan con pip install y tendremos que añadirlas con import el en código.
Escogemos spacy para realizar algunas pruebas.
Se instalan con pip install spacy y tendremos que añadirlas con import spacy el en código.
Escogemos el modelo en español en el código con:
modelo_spacy = spacy.load("es_core_news_md")
Este modelo también lo tenemos que instalar en la terminal
python3 -m spacy download es_core_news_md
Ahora imprimimos el analisis de la respuesta e imprimimos la lista de tokens, de categorías gramaticales y la relación de dependencia con su encabezado:
analisis = modelo_spacy(texto_generado)
for token in analisis:
print(token.text, token.pos_, token.dep_, token.head.text)
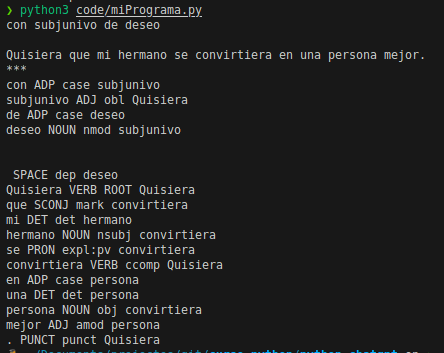
Ahora vamos a imprimir las entidades y las etiquetas que los categorizan,
for ent in analisis.ents:
print(ent.text, ent.label_)

3.3.2. - Utilizar la información extraída
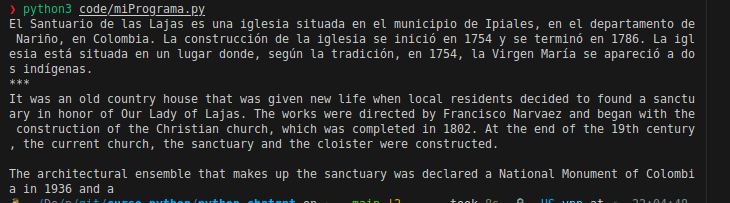
Podemos utilizar la información que hemos extraído. Por ejemplo, puede sacar información de tipo LOC, de ubicación. Con lo cuál se puede generar una pregunta por cada etiqueta de este tipo. Por ejemplo:
ubicacion = None
for ent in analisis.ents:
# print(ent.text, ent.label_)
if ent.label_ == "LOC":
ubicacion = ent
break
if ubicacion:
prompt2 = f"Dime más acerca de {ubicacion}"
respuesta2 = openai.Completion.create(
engine=modelo,
prompt=prompt2,
n=1,
temperature=1,
max_tokens=100
)
print(respuesta2.choices[0].text.strip())